Title: Joint Detection and Identification Feature Learning for Person Search;
- aXiv上该论文的第一个版本题目是 End-to-End Deep Learning for Person Search
Authors: Tong Xiao1* ; Shuang Li1* ; Bochao Wang2 ; Liang Lin2; Xiaogang Wang1
Affilations: 1.The Chinese University of Hong Kong; 2.Sun Yat-Sen University
第一遍看的时候看的是第一个版本,只简单地扫了一眼结构图,觉得就是对faster r-cnn做了小修,而且没有OIM loss,觉得创新性一般。然后发现好几篇后来的文章都用了OIM loss,回过头来再细看文章才发现文章有很多有意思的地方。惭愧!
Motivation
person re-id问题往往是用已经cropped的行人图像块进行检索,判断query和gallary中的图像是否是同一个identity。这里面存在几个问题:
①现实中检索都是直接从原始场景图像中实现,而不是利用detection之后的cropped image;
②很多数据集都是手动标注的框,实际上detector的检测精度以及是否存在漏检都会对行人重识别的结果造成影响。
因此,作者提出端到端的person search思想,将detection和re-id问题融在一起。
模型

- 网络的输入是整张图像;
- pedestrian proposal net:输入经过ResNet-50的第一个部分(conv1-conv4_3)之后输出1024d的feature maps(大小是原输入的1/16);类似于RPN,该feature map先经过一个$512 imes3 imes3$的卷积,得到的特征每个位置的9个anchors分别送入一个softmax classifier(person/non-person)和linear layer(bbox regression);bbox经过NMS,得到128个final proposals;
- identification net:每个proposal经过ROI pooling得到$1024 imes14 imes14$的特征,然后送入ResNet-50的第二个部分(conv4_4-conv5_3),经过一个GAP(global average pooling)得到一个1024维的feature map;这个1024 feature map一分为三:①softmax二分类;②linear regression位置回归;③映射成一个256维、l2 normalized的子控件,实际上是一个FC层,得到256d的id-feat,inference阶段id-feat用来计算consine similarity,training阶段用来计算OIM loss。
Online Instance Matching Loss(OIM LOSS)
注意是用所有final proposals的256d id-feat计算OIM loss。
训练集中有$L$个labeled identities,赋予他们class-id(1到$L$);也有许多unlabeled identities;还有许多背景和错误信息。OIM只考虑前两种。
做法:
- 对于labeled identities: 记mini-batch中的一个labeled identity为$xinmathbb{R}^D$,$D$是特征维度。线下计算和存储一个lookup table(LUT)$Vinmathbb{R}^{D imes L}$,里面存储着所有labeled identities的id-feat。
- 前向阶段,用$V^Tx$计算mini-batch中的样本和所有labeled identities之间的余弦相似性。
- 后向阶段,如果目标的class-id是$t$,那么用$v_t leftarrow gamma v_t+(1-gamma)x$更新LUT的第$t$列,其中$rin[0,1]$不明白为什么这么更新
- 对于unlabeled identities,由于数量不等,作者用了一个循环队列来存储$Uinmathbb{R}^{D imes Q}$,$Q$是队列空间大小。同样用$U^Tx$来计算mini-batch中样本和队列中unlabeled identities的余弦相似性。每次循环,将新的feature vector push,pop一个旧的,保证队列大小不变。
- 基于上述结构,$x$被认作class-id $i$的概率用softmax函数计算
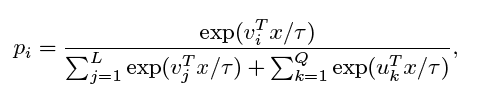
- 同样,被认作第$i$个unlabeled identity的概率是

- OIM objective是最大化log似然的期望

- 求导是

为什么不用softmax loss直接分类?
- 一是类别太多,而每类的正样本太少,使得训练很难
- 二是无法利用unlabeled identities,因为他们没有标签
Dataset
作者提出了新的person search的数据集,包含street view和视频截图,即CUHK-SYSY
Evaluation Protocols and Metrics
person search很自然地继承了detection和re-ID的评价指标,cumulative matching characteristics (CMC top-K) 和mean averaged precision (mAP)。这里要注意和person re-id中这两个指标的异同。
CMC
原文:a matching is counted if there is at least one of the top-K predicted bounding boxes overlaps with the ground truths with intersection-over-union (IoU) greater or equal to 0.5.
这里相对好理解,对于输出的bbox,与GT的IoU>0.5的算作candidates,然后和re-id一样计算top K中 是否包含,包含则算做匹配上。对于误检或者漏检不管。
mAP
原文:(MAP)is inspired from the object detection tasks. We follow the ILSVRC object detection criterion [29] to judge the correctness of predicted bounding boxes. An averaged precision (AP) is calculated for each query based on the precision-recall curve, and then we average the APs across all the queries to get the final result.
这个和reid的mAP应该有较大区别;应该是对每个query相当于一类,求detection的AP