一、文件操作:
一、需要的条件:1、文件的路径 2、文件的编码方式 3、文件操作的动作(是读写还是写读)
f1 = open('D: est.txt',encoding='utf-8',mode='r')
content = f1.read()
print(content)
f1.close()
f1成为文件句柄,又叫文件对象,可以命名为 file、file_handle、f_handle、f_obj,
open,打开文件的指令,是windows的指令,windows默认编码是gbk,Linux的默认编码方式是utf-8,mac的默认编码方式也是utf-8
综上所述,操作文件需要三步:1,打开文件,产生文件句柄;2,操作文件句柄;3,关闭文件句柄
‘r‘ 模式文字类的文件读;‘rb’ 模式,非文字类的文件读 (如图片、视频、音频等)
‘r’下有三种方法 f.read(),一次性读取文件的全部内容;f.readline()执行一次,读取一行文件的内容;f.readlines(),将文件的每一行作为列表的一个元素读取出来。
for循环读取文件:
f1 = open('D: est.txt',encoding='utf-8') #f1叫做迭代器,好处:只在内存中占一条的空间,for循环的时候,在内存中只在一行的内存,读完后,这一行内存消失,节省内存空间,对于读取文件,用for循环去读,读取一个文件句柄。
for i in f1:
print(i)
f1.close()
f.read(n),对于r模式,n表示字符,按照一次性读取n个字符读取文件。对于rb模式来说,n表示字节,按照一次性读取n个字节读取文件
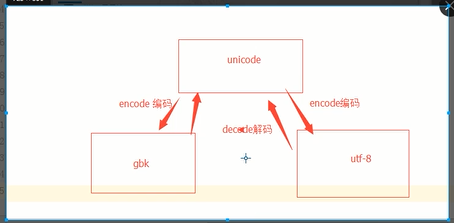
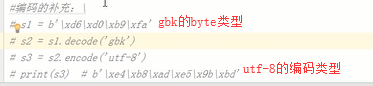
Unicode ----->bytes 使用encode();bytes----->Unicode 使用decode()例如str.decode(‘utf-8’)
# with open() as:该方法不用手动关闭文件,对文件操作过多,建议不要用该方法,因为文件关闭的时间不知道,如果用该方法先读后写,就容易出现问题
如果单纯的对文件进行读写,该方法比较好。

二、文件的改:
1,打开原文件,产生文件句柄
2,创建新文件,产生文件句柄
3,读取原文件,进行修改,写入新文件
4,将原文件删除
5,将新文件重命名为原文件
使用:import os
with open('file_test',encoding='utf-8') as f1,
open('file_test.bak',encoding='utf-8',mode='w') as f2:
old_content = f1.read()
new_content = old_content.reaplace('alex','SB')
f2.write(new_content)
或者:
for line in f1:
new_line = line.replace('alex','SB')
f2.write(new_line) #for循环不结束,写的动作不结束,该动作放到for循环外面,之前写的内容就会被覆盖。
os.remove('file_test')
os.rename('file_test.bak','file_test')
一、函数的初识:
不使用函数:1,重复代码多;2,可读性差;3,函数以实现功能为导向,函数体中尽量不要使用print()
函数的组成方式: def 关键字 函数名(函数名的定义方法与变量相同--数字字母下划线,开头不能是数字,不能是关键字,必须具有可读性):
函数体
例如:count = 1
s = 'sdfsfdsf34'
def my_len():
for i in s:
count += 1
print(count)
my_len()#函数名+(),执行函数
2,函数的返回值:1,遇到return,结束函数(类似于break),后面的代码不执行
没有return 返回None;直接写return 或者return None 返回值为None
return返回单个数据,函数的调用者就返回什么,返回的数据类型不变,如果返回多个数据,将多个值放到元组里,讲元祖返回给函数的调用者
例如:def func1():
print(111)
print(222)
return
print(333)
print(444)
func1() 输出结果为 111,222
2,给函数的调用者返回值
函数的调用者是函数名+()
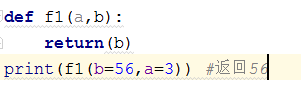
3,函数的传参:
1,形式参数:位置参数--传递实参时必须按顺序一一对应;

关键字参数:必须一一对应,可以不分顺序
三元表达式: 如果只有一个简单的比较大小
def max(a,b):
ret = a if a>b else b
return(ret)
混合参数:既有位置参数,又有关键字参数,一一对应,关键字参数必须要在位置参数后面
从形参的角度:1,位置参数:必须一一对应,按顺序
2,默认参数:默认参数必须在位置参数后面

3,动态参数:*args;**kwargs 万能参数,当函数传递的参数不用的时候使用
def func1(*args,**kwargs):
print(args) #元祖(返回所有位置参数)
print(kwargs) #字典(返回关键字参数,以字典方式存储)
func1(1,2,3,4,5,'alex','laonanhai',a='ww',b='qq') #返回(1,2,3,4,5,'alex','laonanhai') {'a':'ww','b':'qq'}
4,形式参数参数的摆放顺序(位置参数,*args,默认参数,**kwargs)
5,打散功能 fu(*l1,*l2)函数的执行加*表示打散,将可循环的参数的元素作为位置参数传递给args
fu(*args,**args),函数的定义时,加*表示聚合

三、函数的进阶:Python不是内存级别的变成语言,C语言是内存级别的开发语言有指针
名称空间,又叫命名空间,比如name='alex',存放的是变量与值的内存地址的关系,name与alex id的关系
临时命名空间,又叫局部命名空间,存入函数里变量与值的关系,随着函数执行的结束,临时命名空间结束
名称空间有全局名称空间,临时名称空间又叫局部名称空间,内置名称空间(只要创建py文件,有先把内置名称空间,先加载到内存,len等内置方法)
作用域 : 作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
加载顺序:内置名称空间先加载到内存,然后是全局名称空间,然后是局部名称空间(函数执行时,函数不执行不开创局部名称空间)
取值顺序:在局部调用:局部命名空间->全局命名空间->内置命名空间
在全局调用:全局命名空间->内置命名空间
综上所述,在找寻变量时,从小范围,一层一层到大范围去找寻。
def func1():
m = 1
print(m)
print(m) #这行报的错
报错了:NameError: name 'm' is not defined
上面为什么会报错呢?现在我们来分析一下python内部的原理是怎么样:
我们首先回忆一下Python代码运行的时候遇到函数是怎么做的,从Python解释器开始执行之后,就在内存中开辟里一个空间,每当遇到一个变量的时候,就把变量名和值之间对应的关系记录下来,但是当遇到函数定义的时候,解释器只是象征性的将函数名读入内存,表示知道这个函数存在了,至于函数内部的变量和逻辑,解释器根本不关心。
等执行到函数调用的时候,Python解释器会再开辟一块内存来储存这个函数里面的内容,这个时候,才关注函数里面有哪些变量,而函数中的变量回储存在新开辟出来的内存中,函数中的变量只能在函数内部使用,并且会随着函数执行完毕,这块内存中的所有内容也会被清空。
我们给这个‘存放名字与值的关系’的空间起了一个名字-------命名空间。
代码在运行伊始,创建的存储“变量名与值的关系”的空间叫做全局命名空间;
在函数的运行中开辟的临时的空间叫做局部命名空间。
global关键字,nonlocal关键字。
global:
1,声明一个全局变量。
2,在局部作用域想要对全局作用域的全局变量进行修改时,需要用到 global(限于字符串,数字)。
def func():
global a
a = 3
func()
print(a)
例2:
count = 1
def search():
global count
count = 2
search()
print(count)
ps:对可变数据类型(list,dict,set)可以直接引用不用通过global

nonlocal:
1,不能修改全局变量。
2,在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的哪层,从那层及以下此变量全部发生改变。
 输出结果为:10,30,30,42
输出结果为:10,30,30,42
四,函数名的本质。
函数名本质上就是函数的内存地址。
1.可以被引用
def func():
print('in func')
f = func
f() #输出结果为 in func
2.可以被当作容器类型的元素
def f1():
print('f1')
def f2():
print('f2')
def f3():
print('f3')
l = [f1,f2,f3]
d = {'f1':f1,'f2':f2,'f3':f3}
#调用
l[0]()----结果为 f1
d['f2']()----结果为 f2
3.可以当作函数的参数和返回值
def f1():
print('f1')
def func1(argv):
argv()
return argv
f = func1(f1)
f() #执行结果为f1 f1
第一类对象(first-class object)指
1.可在运行期创建
2.可用作函数参数或返回值
3.可存入变量的实体。*不明白?那就记住一句话,就当普通变量用
五,闭包
def func():
name = '太白金星'
def inner():
print(name)
inner()
f = func
f()
闭包函数:
内部函数包含对外部作用域而非全剧作用域变量的引用,该内部函数称为闭包函数
#函数内部定义的函数称为内部函数
由于有了作用域的关系,我们就不能拿到函数内部的变量和函数了。如果我们就是想拿怎么办呢?返回呀!
我们都知道函数内的变量我们要想在函数外部用,可以直接返回这个变量,那么如果我们想在函数外部调用函数内部的函数呢?
是不是直接就把这个函数的名字返回就好了?
这才是闭包函数最常用的用法
**判断闭包函数的方法__closure__
def func():
name = 'eva'
def inner():
print(name)
print(inner.__closure__)
return inner
f = func()
f()
#输出的__closure__为None :不是闭包函数
name = 'egon'
def func2():
def inner():
print(name)
print(inner.__closure__)
return inner
f2 = func2()
f2()
def wrapper():
money = 1000
def func():
name = 'eva'
def inner():
print(name,money)
return inner
return func
f = wrapper()
i = f()
i()