一、字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。
存储大量的数据,是关系型数据,查询数据快。
列表是从头遍历到尾
字典使用二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。
比如字典有1~100的数据,现在想要查找75。
先劈一半,找到中间值50。判断50和75的大小,发现小于,再劈一半。
找到中间值75,直接返回结果。
对于字符串查找
每一个字符串,都有一个hash值,是唯一的。
print(hash('a'))
执行输出:
977260134378667761
print(hash('afdsfeye'))
执行输出:
-8718419340409073569
字典可以存放各种数据类型
dic = {
'name':'老男孩',
'age':17,
'name_list':['张三','李四'],
1:True
...
}
数据类型的分类:
可变数据类型(不可哈希):list,dict,set
不可变数据类型(可哈希):int,bool,str,tuple
容器类型:
容器类(承载各种数据类型):list,tuple,dic
字典的键:必须是不可变数据类型
字典的值:任意数据类型。
字典的键是唯一的。
数据类型分类,主要是可变和不可变
字典的顺序:
严格意义上来讲,是无序的
3.5之前,字典是无序的
3.6开始,字典创建的时候,按照一定的顺序插入的值,看起来是有序的
下面介绍字典的增删改查
增
第一种:
dic = {'name':'xiao','age':21}
dic['hobby'] = 'girl'
print(dic)
执行输出:
{'age': 21, 'hobby': 'girl', 'name': 'xiao'}
第二种:
setdefault() 无则添加,有则不变
dic = {'name':'xiao','age':21}
dic.setdefault('hobby')
print(dic)
执行输出:
{'hobby': None, 'name': 'xiao', 'age': 21}
dic.setdefault('hobby') 虽然只指定了key,没有指定value,默认会填充None
添加键值对
dic = {'name':'xiao','age':21}
dic.setdefault('hobby','girl')
print(dic)
执行输出:
{'age': 21, 'name': 'xiao', 'hobby': 'girl'}
添加一个已经存在的key
dic = {'name':'xiao','age':21}
dic.setdefault('name','江疏影')
print(dic)
执行输出:
{'name': 'xiao', 'age': 21}
上述2个添加的方法,只能一个个添加。
删
pop() 删除指定的key
pop()是所有方法中,唯一有返回值的。
dic = {'name':'xiao','age':21}
print(dic.pop('age'))
print(dic)
执行输出:
21
{'name': 'xiao'}
删除一个不存在的key
dic = {'name':'xiao','age':21}
print(dic.pop('hobby'))
print(dic)
执行报错: KeyError: 'hobby'
删除一个不存在的key,并指定默认返回值None
dic = {'name':'xiao','age':21}
print(dic.pop('hobby',None))
print(dic)
执行输出:
None
{'age': 21, 'name': 'xiao'}
推荐使用上述方法,删除一个key。因为如果key不存在时,不会报错,返回None。程序员最怕报错了!
clear() 清空
dic = {'name':'xiao','age':21}
dic.clear()
print(dic)
执行输出:
{}
del 删除字典
dic = {'name':'xiao','age':21}
del dic
del也可以删除指定的key,如果不存在,会报错
dic = {'name':'xiao','age':21}
del dic['hobby']
推荐使用pop删除,并指定None
popitem() 随机删除,有返回值
dic = {'name':'xiao','age':21}
print(dic.popitem())
print(dic)
执行输出:
('age', 21)
{'name': 'xiao'}
在3.6版本,会删除最后一个。
在抽签场景中,可能会用到此方法。
改
dic = {'name':'xiao','age':21}
dic['name'] = 'zhangsan'
print(dic)
执行输出:
{'name': 'zhangsan', 'age': 21}
update() 针对2个字典的修改
dic = {'name':'jin','age':21,'sex':'male'}
dic2 = {'name':'sun','weight':76}
#将dic键值对,覆盖并添加到dic2
dic2.update(dic)
print(dic)
print(dic2)
执行输出:
{'sex': 'male', 'name': 'jin', 'age': 21}
{'age': 21, 'weight': 76, 'name': 'jin', 'sex': 'male'}
可以发现dic没有改变,dic2改变了
update()修改原则
有相同的就覆盖,没有的就添加
查
通过key查找
dic = {'name':'xiao','age':21}
print(dic['name'])
执行输出:
xiao
通过value查询
dic = {'name':'xiao','age':21}
print(dic['xiao'])
执行报错: KeyError: 'xiao'
字典只能通过key查询,不能通过value查询,否则报错
get() 通过key查询
dic = {'name':'xiao','age':21}
print(dic.get('name'))
执行输出:
xiao
查询一个不存在的key
dic = {'name':'xiao','age':21}
print(dic.get('hobby'))
执行输出:
None
默认的None返回值是可以改变的
dic = {'name':'xiao','age':21}
print(dic.get('hobby','亲,木有这个字哦!'))
执行输出:
亲,木有这个字哦!
如果需要查询多个key,请使用for循环
dic = {'name':'xiao','age':21}
for i in dic:
print(i)
执行输出:
age
name
其它操作方法:
keys() values() items()
keys()
dic = {'name':'xiao','age':21}
print(dic.keys())
print(type(dic.keys()))
执行输出:
dict_keys(['name', 'age'])
<class 'dict_keys'>
keys()方法输出的数据是一个特殊类型,它相当于把所有的key放到了一个容器里面。
它类似于列表的容器,当它并不是列表。
它可以循环
dic = {'name':'xiao','age':21}
for i in dic.keys():
print(i)
执行输出:
age
name
values()
把所有的value放到一个容器里面
dic = {'name':'xiao','age':21}
for i in dic.values():
print(i)
执行输出:
xiao
21
items()
将键值对作为一个整体,放到元组中。集中放到一个容器中。
dic = {'name':'xiao','age':21}
for i in dic.items():
print(i)
执行输出:
('age', 21)
('name', 'xiao')
特殊类型转换为列表
dic = {'name':'xiao','age':21}
print(list(dic.keys()))
执行输出:
['age', 'name']
分别循环key和value
dic = {'name':'xiao','age':21}
for k,v in dic.items():
print(k,v)
执行输出:
age 21
name xiao
现有如下字典,需要遍历key
dic = {'name':'xiao','age':21}
第一种写法:
for i in dic.keys():
print(i)
第二种写法:
for i in dic:
print(i)
以上2段代码,功能是一样的。推荐使用第二种。
概念: 分别赋值
比如
a,b = 2,3 print(a,b)
执行输出:
2 3
面试题:
a = 4,b = 5,请用一行代码,将a和b的值互换。
答案
a,b = b,a
字典的嵌套
出一个题目
dic = {
'name_list':['张三','lisi','隔壁王叔叔'],
'dic2':{'name':'太白','age':12}
}
1. 给列表追加一个元素:'旺旺'
2. 给列表lisi全部大写
3. 给dic2 对应的字典添加一个键值对:hobby:girl
答案:
#1.
dic['name_list'].append('旺旺')
print(dic)
#2.
dic['name_list'][1] = dic['name_list'][1].upper()
print(dic)
#3.
dic['dic2']['hobby'] = 'girl'
print(dic)
执行输出:
{'name_list': ['张三', 'lisi', '隔壁王叔叔', '旺旺'], 'dic2': {'name': '太白', 'age': 12}}
{'name_list': ['张三', 'LISI', '隔壁王叔叔', '旺旺'], 'dic2': {'name': '太白', 'age': 12}}
{'name_list': ['张三', 'LISI', '隔壁王叔叔', '旺旺'], 'dic2': {'hobby': 'girl', 'name': '太白', 'age': 12}}
今日作业:
1,有如下变量(tu是个元祖),请实现要求的功能
tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)}, 44])
a. 讲述元祖的特性
b. 请问tu变量中的第一个元素 "alex" 是否可被修改?
c. 请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven"
d. 请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven"
2, 字典dic,dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
a. 请循环输出所有的key
b. 请循环输出所有的value
c. 请循环输出所有的key和value
d. 请在字典中添加一个键值对,"k4": "v4",输出添加后的字典
e. 请在修改字典中 "k1" 对应的值为 "alex",输出修改后的字典
f. 请在k3对应的值中追加一个元素 44,输出修改后的字典
g. 请在k3对应的值的第 1 个位置插入个元素 18,输出修改后的字典
3,av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌丝请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","verygood"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
# 1,给此 ["很多免费的,世界最大的","质量一般"]列表第二个位置插入一个元素:'量很大'。
# 2,将此 ["质量很高,真的很高","全部收费,屌丝请绕过"]列表的 "全部收费,屌丝请绕过" 删除。
# 3,将此 ["质量很高,真的很高","全部收费,屌丝请绕过"]列表的 "全部收费,屌丝请绕过" 删除。
# 4,将此["质量怎样不清楚,个人已经不喜欢日韩范了","verygood"]列表的 "verygood"全部变成大写。
# 5,给 '大陆' 对应的字典添加一个键值对 '1048' :['一天就封了']
# 6,删除此"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"]键值对。
# 7,给此["全部免费,真好,好人一生平安","服务器在国外,慢"]列表的第一个元素,加上一句话:'可以爬下来'
4、有字符串"k:1|k1:2|k2:3|k3:4" 处理成字典 {'k':1,'k1':2....}
5、元素分类
有如下值li= [11,22,33,44,55,66,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表}
6、输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ["手机", "电脑", '鼠标垫', '游艇']
要求:1:页面显示 序号 + 商品名称,如:
1 手机
2 电脑
…
2: 用户输入选择的商品序号,然后打印商品名称
3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。
4:用户输入Q或者q,退出程序。
明日默写内容。
1)字典的增删改查。
2)过滤敏感字符代码的默写。
li = ["苍老师","东京热","武藤兰","波多野结衣"]
l1 = []
comment = input('请输入评论>>>')
for i in li:
if i in comment:
comment = comment.replace(i,'*'*len(i))
l1.append(comment)
print(l1)
答案:
第1题
1,有如下变量(tu是个元祖),请实现要求的功能
tu = ("alex", [11, 22, {"k1": 'v1',元祖的特性 "k2": ["age", "name"], "k3": (11,22,33)}, 44])
a. 讲述元祖的特性
答案:
1.创建之后不能加减修改元素
2.元素也可以是数字、字符、变量或者混杂
3.元组也可以嵌套
b. 请问tu变量中的第一个元素 "alex" 是否可被修改?
答案: 不可以
c. 请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven"
答案:"k2"对应的值是列表,可以修改。
修改代码如下:
tu[1][2]['k2'].append('Seven')
d. 请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven"
答案:"k3"对应的值是元组类型,不可以修改
第2题
2, 字典dic,dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
a. 请循环输出所有的key
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
for i in dic:
print(i)
b. 请循环输出所有的value
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
for i in dic.values():
print(i)
c. 请循环输出所有的key和value
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
for k,v in dic.items():
print(k,v)
d. 请在字典中添加一个键值对,"k4": "v4",输出添加后的字典
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
dic['k4'] = 'v4'
print(dic)
e. 请在修改字典中 "k1" 对应的值为 "alex",输出修改后的字典
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
dic['k1'] = 'alex'
print(dic)
f. 请在k3对应的值中追加一个元素 44,输出修改后的字典
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
dic['k3'].append(44)
print(dic)
g. 请在k3对应的值的第 1 个位置插入个元素 18,输出修改后的字典
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
dic['k3'].insert(1,18)
print(dic)
第3题:
3,av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌丝请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","verygood"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
# 1,给此 ["很多免费的,世界最大的","质量一般"]列表第二个位置插入一个元素:'量很大'。
av_catalog['欧美']['www.youporn.com'].insert(1,'量很大')
# 2,将此 ["质量很高,真的很高","全部收费,屌丝请绕过"]列表的 "全部收费,屌丝请绕过" 删除。
av_catalog['欧美']['x-art.com'].pop(1)
# 3,将此 ["质量很高,真的很高","全部收费,屌丝请绕过"]列表的 "全部收费,屌丝请绕过" 删除。
av_catalog['欧美']['x-art.com'].pop(1)
# 4,将此["质量怎样不清楚,个人已经不喜欢日韩范了","verygood"]列表的 "verygood"全部变成大写。
av_catalog['日韩']['tokyo-hot'][1].upper()
# 5,给 '大陆' 对应的字典添加一个键值对 '1048' :['一天就封了']
av_catalog['大陆']['1048'] = ['一天就封了']
# 6,删除此"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"]键值对。
av_catalog['欧美'].pop('letmedothistoyou.com',None)
# 7,给此["全部免费,真好,好人一生平安","服务器在国外,慢"]列表的第一个元素,加上一句话:'可以爬下来'
av_catalog['大陆']['1024'][0] = av_catalog['大陆']['1024'][0]+'可以爬下来'
第4题
4、有字符串"k:1|k1:2|k2:3|k3:4" 处理成字典 {'k':1,'k1':2....}
先使用split()指定分割符| 切割成列表
li = "k:1|k1:2|k2:3|k3:4"
li_s = li.split('|')
for i in li_s:
print(i)
执行输出:
k:1
k1:2
k2:3
k3:4
在for循环里面是,指定分割符:,再次切割
li = "k:1|k1:2|k2:3|k3:4"
li_s = li.split('|')
for i in li_s:
q = i.split(':')
print(q)
执行输出:
['k', '1']
['k1', '2']
['k2', '3']
['k3', '4']
那么列表中索引为0的就是key,索引为1就是value
使用字典方法添加键值对,完整代码如下:
li = "k:1|k1:2|k2:3|k3:4"
#使用|分割成列表
li_s = li.split('|')
#空字典
dic = {}
for i in li_s:
#使用:分割成列表
qie = i.split(':')
# #字典key
key = qie[0]
#字典value
value = qie[1]
#添加键值对
dic[key] = value
#打印字典
print(dic)
执行输出:
{'k1': '2', 'k2': '3', 'k': '1', 'k3': '4'}
代码优化
li = "k:1|k1:2|k2:3|k3:4"
#使用|分割成列表
li_s = li.split('|')
#空字典
dic = {}
for i in li_s:
#使用:分割成列表
qie = i.split(':')
#添加键值对
dic[qie[0]] = qie[1]
#打印字典
print(dic)
执行输出:
{'k3': '4', 'k2': '3', 'k': '1', 'k1': '2'}
将数字转换为整形
li = "k:1|k1:2|k2:3|k3:4"
#使用|分割成列表
li_s = li.split('|')
#空字典
dic = {}
for i in li_s:
#使用:分割成列表
qie = i.split(':')
#添加键值对
dic[qie[0]] = int(qie[1])
#打印字典
print(dic)
执行输出:
{'k2': 3, 'k': 1, 'k1': 2, 'k3': 4}
第5题:
5、元素分类
有如下值li= [11,22,33,44,55,66,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表}
先打印列表的每一个元素
li= [11,22,33,44,55,66,77,88,99,90]
for i in li:
print(i)
执行输出:
11
22
33
...
90
定义字典,将大于66的,放入k1的列表中
li= [11,22,33,44,55,66,77,88,99,90]
#定义字典,key和value是空列表
dic1 = {'k1': [], 'k2': []}
for i in li:
if i > 66:
dic1['k1'].append(i)
print(dic1)
执行输出:
{'k2': [], 'k1': [77, 88, 99, 90]}
将小于66的放入k2中,完整代码如下:
li= [11,22,33,44,55,66,77,88,99,90]
#定义字典,key和value是空列表
dic1 = {'k1': [], 'k2': []}
for i in li:
#判断i是否大于66
if i > 66:
#追加到k1中
dic1['k1'].append(i)
else:
# 追加到k2中
dic1['k2'].append(i)
print(dic1)
执行输出:
{'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]}
由于66跑到k2里面了,在改一下判断条件
li = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
# 定义字典,key和value是空列表
dic1 = {'k1': [], 'k2': []}
for i in li:
# 判断i是否大于66
if i > 66:
# 追加到k1中
dic1['k1'].append(i)
elif i <= 66:
# 追加到k2中
dic1['k2'].append(i)
print(dic1)
执行输出:
{'k1': [77, 88, 99, 90], 'k2': [11, 22, 33, 44, 55, 66]}
第6题
6、输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ["手机", "电脑", '鼠标垫', '游艇']
要求:1:页面显示 序号 + 商品名称,如:
1 手机
2 电脑
…
2: 用户输入选择的商品序号,然后打印商品名称
3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。
4:用户输入Q或者q,退出程序。
先输入商品列表,并打印序号(使用index方法)
6.1
li = ["手机", "电脑", '鼠标垫', '游艇']
for i in li:
#索引值
index = li.index(i)
print(index,i)
执行输出:
0 手机
1 电脑
2 鼠标垫
3 游艇
有了序号,就可以打印商品
判断用户的输入的内容是否为数字,定义一个非法字符串aa
6.2
li = ["手机", "电脑", '鼠标垫', '游艇']
#用户输入内容
entry = 'aa'
for i in li:
#索引值
index = li.index(i)
#判断用户输入的,是否是数字
if entry.isdigit():
#输入的序号转换为数字
entry_int = int(entry)
else:
print('您输入的含有非数字元素')
break
执行输出:
您输入的含有非数字元素
判断用户输入的数字是否大于列表的长度,定义一个数字11
6.3
li = ["手机", "电脑", '鼠标垫', '游艇']
#用户输入内容
entry = '11'
for i in li:
#索引值
index = li.index(i)
#判断用户输入的,是否是数字
if entry.isdigit():
#输入的序号转换为数字
entry_int = int(entry)
#判断序号是否大于列表长度
if entry_int < len(li):
#打印商品列表
print(li[entry_int])
break
else:
print('你输入的序号商品不存在,请重新输入!')
break
else:
print('您输入的含有非数字元素')
break
执行输出:
你输入的序号商品不存在,请重新输入!
重新修改数字为1,再次执行,就可以输出商品了。
上面的代码是一次性输入,如果需要循环执行,怎么办?用while循环
先来一个简单的循环输入input,根据第4点要求,遇到Q或者q,退出程序
6.4
flag = True
while flag:
entry = input('请输入序号:').strip()
#将内容转换为大写, 判断是否是Q
if entry.upper() == 'Q':
flag = False
print('退出程序')
执行程序:
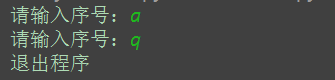
执行执行之前,打印商品列表
6.5
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
#遍历商品列表
for i in li:
# 索引值
index = li.index(i)
#打印序号和商品名称
print(index, i)
while flag:
entry = input('请输入序号:').strip()
#将内容转换为大写, 判断是否是Q
if entry.upper() == 'Q':
flag = False
print('退出程序')
else:
pass
执行输出:
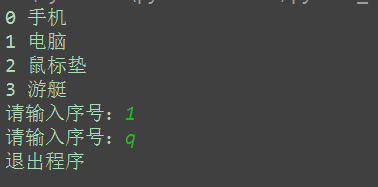
将6.3里面的for循环代码复制,替换到6.5里面pass里面,最后代码如下:
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
#遍历商品列表
for i in li:
# 索引值
index = li.index(i)
#打印序号和商品名称
print(index, i)
while flag:
entry = input('请输入序号:').strip()
#将内容转换为大写, 判断是否是Q
if entry.upper() == 'Q':
flag = False
print('退出程序')
else:
for i in li:
# 索引值
index = li.index(i)
# 判断用户输入的,是否是数字
if entry.isdigit():
# 输入的序号转换为数字
entry_int = int(entry)
# 判断序号是否大于列表长度
if entry_int < len(li):
# 打印商品列表
print(li[entry_int])
break
else:
print('你输入的序号商品不存在,请重新输入!')
break
else:
print('您输入的含有非数字元素')
break
执行输出:

输出部分修饰一下:
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
print('''
|欢迎访问天猫商店|
|序号| |商品名|
''')
#遍历商品列表
for i in li:
# 索引值
index = li.index(i)
#打印序号和商品名称
print(' '+str(index), ' '+i)
while flag:
entry = input('请输入序号:').strip()
#将内容转换为大写, 判断是否是Q
if entry.upper() == 'Q':
flag = False
print('退出程序')
else:
for i in li:
# 索引值
index = li.index(i)
# 判断用户输入的,是否是数字
if entry.isdigit():
# 输入的序号转换为数字
entry_int = int(entry)
# 判断序号是否大于列表长度
if entry_int < len(li):
# 打印商品列表
print(li[entry_int])
break
else:
print('你输入的序号商品不存在,请重新输入!')
break
else:
print('您输入的含有非数字元素')
break
执行输出:

代码优化:
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
print('''
|欢迎访问天猫商店|
|序号| |商品名|
''')
#遍历商品列表
for i in li:
# 索引值
index = li.index(i)
#打印序号和商品名称
print(' '+str(index), ' '+i)
while flag:
entry = input('请输入序号:').strip()
# 判断用户输入的,是否是数字
if entry.isdigit():
# 输入的序号转换为数字
entry_int = int(entry)
# 判断序号是否大于列表长度
if entry_int < len(li):
# 打印商品列表
print(li[entry_int])
else:
print('你输入的序号商品不存在,请重新输入!')
elif entry.upper() == 'Q':
flag = False
print('退出程序')
else:
print('您输入的含有非数字元素')
执行效果同上:
再次优化
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
print('''
|欢迎访问天猫商店|
|序号| |商品名|
''')
while flag:
# 遍历商品列表
for i in li:
# 索引值
index = li.index(i)
# 打印序号和商品名称
print(' ' + str(index), ' ' + i)
#用户输入编号
entry = input('请输入序号:').strip()
# 判断用户输入的,是否是数字
if entry.isdigit():
# 输入的序号转换为数字
entry_int = int(entry)
# 判断序号是否大于列表长度
if entry_int < len(li):
# 打印商品列表
print('您选择的商品是:%s' % li[entry_int])
else:
print('你输入的序号商品不存在,请重新输入!')
#判断用户是否输入q
elif entry.upper() == 'Q':
flag = False
print('退出程序')
else:
print('您输入的含有非数字元素')
执行输出:

调整序号,加1。取值的时候,再减1
li = ["手机", "电脑", '鼠标垫', '游艇']
#标志位
flag = True
print('''
|欢迎访问天猫商店|
|序号| |商品名|
''')
while flag:
# 遍历商品列表
for i in li:
# 索引值
index = li.index(i)
# 打印序号和商品名称,默认是从0开始,这里加1
print(' ' + str(index+1), ' ' + i)
#用户输入编号
entry = input('请输入序号:').strip()
# 判断用户输入的,是否是数字
if entry.isdigit():
# 输入的序号转换为数字
entry_int = int(entry)
# 判断序号是否大于0以及小于等于列表长度
if 0 < entry_int <= len(li):
# 打印商品列表,取值的时候,要减1
print('您选择的商品是:%s' % li[entry_int - 1])
else:
print('你输入的序号商品不存在,请重新输入!')
#判断用户是否输入q
elif entry.upper() == 'Q':
flag = False
print('退出程序')
else:
print('您输入的含有非数字元素')
执行输出:

老师的代码:
li = ["手机", "电脑", '鼠标垫', '游艇']
while True:
for i in li:
print('{} {}'.format(li.index(i)+1,i))
num = input('请输入商品序号: q/Q退出:').strip()
if num.isdigit():
num = int(num)
if num > 0 and num <= len(li):
print(li[num - 1])
else:
print('您输入的选项,超出范围,请重新输入')
elif num.upper() == 'Q':break
else:
print('输入的有非数字,请重新输入')
执行输出:

明日默写内容。
1)字典的增删改查。
dict:
增:
dic['name'] = 'jin'
setdefault() 有则不变,无责添加。
删:
pop 按照键删除键值对
pop('name1',None)
clear 清空字典
del del dic
del dic['name']
popitem() 随机删除,返回删除的元祖形式的键值对
改:
dic['name'] = 'jin'
update
查:
dic['name']
dic.get('name','sb没有此键')
dic.keys() dic.values() dic.items()
li = list(dic.keys())
for i in dic.values():
pass
for k,v in dic.items():
pass
2)过滤敏感字符代码的默写。
li = ["苍老师","东京热","武藤兰","波多野结衣"]
l1 = []
comment = input('请输入评论>>>')
for i in li:
if i in comment:
comment = comment.replace(i,'*'*len(i))
l1.append(comment)
print(l1)