python爬取微信小程序(实战篇)
一、背景介绍
近期有需求需要抓取微信小程序中的数据分析,与一般的网页爬虫类似,主要目标是获取主要的URL地址进行数据爬取,而问题的关键在于如何获取移动端request请求后https加密的参数。本文从最初的抓包到获取URL、解析参数、数据分析及入库等,一步步进行微信小程序的数据爬取。
此次爬取的目标是微信小程序“财神股票”中的已受理科创版公司名单数据,如下:
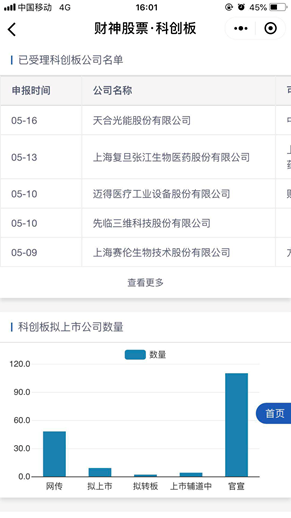
注:抓包、分析、爬取等全过程几乎通用于微信小程序,可以类似的爬取其他小程序测试,原理大同小异。
二、环境配置
具体的环境配置参考:Python爬取微信小程序(Charles)
移动端:iPhone;
PC端:Windows 10;
软件:Charles
注:网络要求较高,请确保网络访问无限制。
三、Charles抓包
Charles相关的配置与说明在此前的一篇文章( Python爬取微信小程序(Charles))中有详细说明,此间不再赘述,强调一点就是移动端证书确保始终信任状态:

1. 设置移动端网络代理;
2. 打开Charles,关闭Windows proxy;
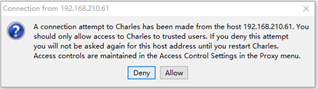
3. 打开微信小程序,Charles提示如下说明正常连接:
4. 点击微信小程序后,在Charles中显示如下:

5. 为了避免过度链接干扰,点击清除按键,清理后,点击“科创版专题”,Charles抓取链接如下:

6. 点击https://nujump.tigerobo.com,在右端contents中可以看到请求的详细内容(为什么是这个链接而不是别的?我也是一个个点开尝试的…)。

7. 在右侧的overview中,可以看到URL的value:https://nujump.tigerobo.com/HB_Jumper/ztjump.ashx?topic=8&aris_data=kcb_1_announced_corp&pageIndex=1&pageSize=5
看到这个链接有木有很熟悉的感觉呢?Method对应的值是GET,也就是说此链接是通过GET方法进行获取与展示数据,在主链接https://nujump.tigerobo.com/HB_Jumper/ztjump.ashx 后采用key与value拼接的方式发送请求,最后两个参数pageIndex=1与pageSize=5,对应第一个页面展示的5条数据,在Charles右侧的contents中,下方选择JSON Text,可以看到对应返回的response如下:

此处的 ”count”: 110 对应目前共有110条与科创版公司相关的数据。
8. 在拿到overview中的目标URL之后,直接修改pageSize的值为110,在浏览器中访问链接:https://nujump.tigerobo.com/HB_Jumper/ztjump.ashx?topic=8&aris_data=kcb_1_announced_corp&pageIndex=1&pageSize=110 后显示如下:

此数据即为小程序中展示的数据,也就是我们此次爬取的对象。
四、数据分析及入库
拿到目标URL后,可以采用python的requests库进行数据爬取:

详情代码此间不再赘述,完整代码参考GitHub:GitHub
注:
- 数据清洗的过程中,剔除了港股股票;
- 通过爬取东方财富网获取每家上市公司的股票代码,详情参考GitHub代码;
- 上市公司与科创版公司的对应关系为多对多的关系,即一家上市公司可能对应多家科创版公司,一家科创版公司可能对应多家上市公司;
- 由于科创版公司目前暂无股票代码等详细信息,故数据的存储方式采用上市公司对应科创板公司的方式存储,具有一定的冗余;
- 由于目前所有的数据均存在变化(如新加科创版公司、上市公司又与新的科创版公司相关联、科创版公司又与新的上市公司相关联等),所以最好每次都清空之前的数据,不要只在之前数据的基础上新增。
五、问题总结
1. 小程序内容加载缓慢或网络异常:
在测试时,发现Charles获取一些财经类小程序(新闻联播、财神行情等)均显示正常,抓包等也无问题,但是对于一些电商小程序(京东购物、当当等),移动端有时候可能会显示网页打不开或无法加载,经测试发现与网络关系较大,可能由于网络本身的原因、移动端代理设置等问题导致。