1.SparkSQL
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块
对于开发人员来讲,SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快,Spark SQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象(数据模型),类似Spark Core中的RDD(DataFrame,DataSet)
2.SparkSQL核心编程
Spark Core中,如果想要执行应用程序,需要首先构建上下文环境对象SparkContext,Spark SQL其实可以理解为对Spark Core的一种封装,
不仅仅在模型上进行了封装(DataFrame,DataSet对RDD,底层还是RDD),上下文环境对象也进行了封装(SparkSession-->SparkContext,底层为SparkContext)
2.1DataFrame
2.1.1创建DataFrame
进入spark-shell ./bin/spark-shell
1.val df = spark.read.json("/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
对结果进行展示(直接展示)
2.df.show()
age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------
对结果进行展示(SQL展示 临时视图,只能对当前session有效)
3.df.createOrReplaceTempView("user") //创建临时试图
4.spark.sql("SELECT * FROM user").show //实现全表查询并对结果进行展示
普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.user
对结果进行展示(SQL展示 全局临时视图 )
3.df.createGlobalTempView("user1")
4.spark.newSession().sql("SELECT * FROM global_temp.user1").show() //可以看到新的session中也是有效的
DSL语法
注意:涉及到运算(加减乘除,> <)的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
使用 DSL 语法风格不必去创建临时视图了,直接通过相关sql语句进行查询
1.创建一个DataFrame
val df = spark.read.json("/data/user.json")
2.查看DataFrame的Schema信息
df.printSchema
3.只查看相关列的数据
df.select("name").show()
df.select("age").show()
表中所有数据
df.select("*").show()
4.查看表中多行列数据 比如"name"列数据以及"age+1"数据
df.select($"username",$"age" + 1).show
df.select($"name",$"age" + 1 as "newage").show
5.查看"age"大于"30"的数据
df.filter($"age">30).show
6.按照"age"分组,查看数据条数
df.groupBy("age").count.show
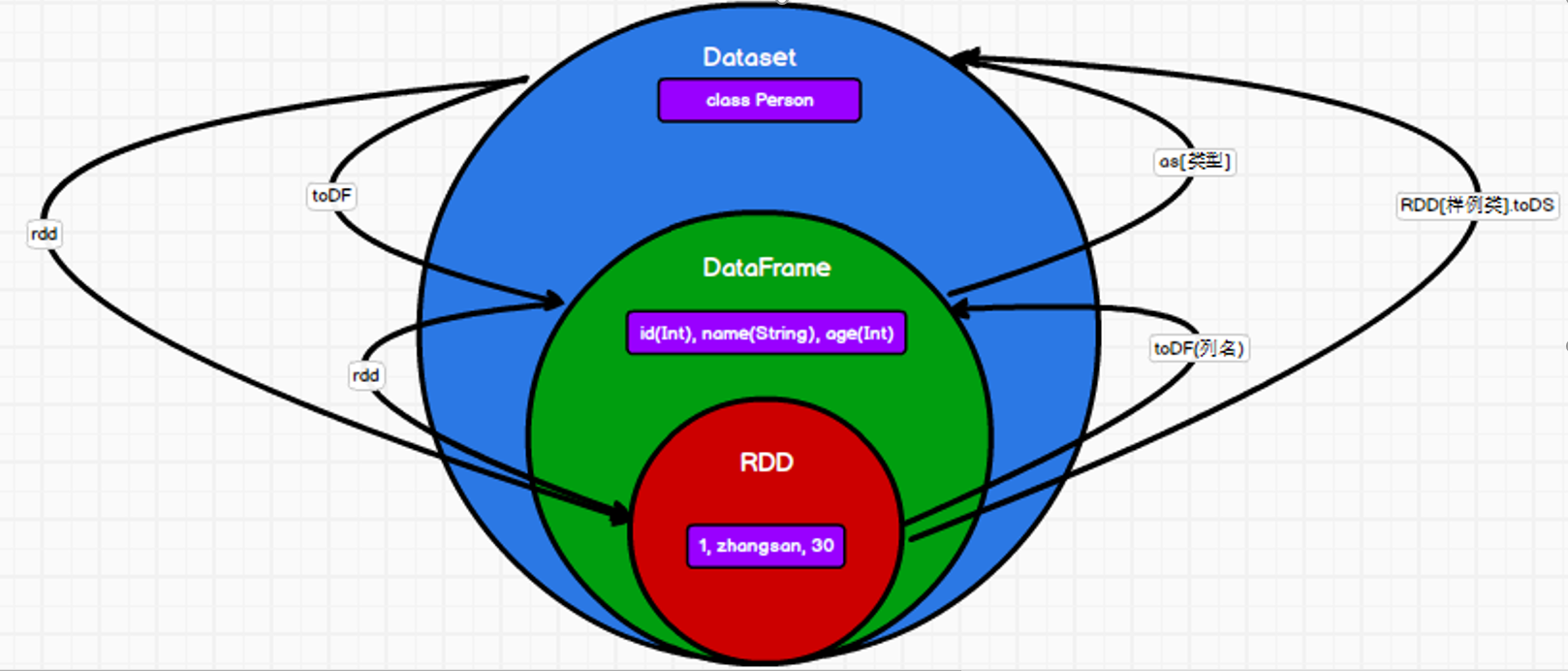
RDD转换为DataFrame 【RDD.toDF("列名")】
在IDEA中开发程序时,如果需要RDD与DF或者DS之间互相操作,那么需要引入 import spark.implicits._
这里的spark指的是创建的sparkSession对象的变量名称,所以必须先创建SparkSession对象再导入。
val rdd2 = sc.makeRDD(List((1,"zahngsan",30),(2,"lisi",33),(3,"wangwu",35)))
rdd2.toDF().show or rdd2.toDF("id","name","age").show
+---+--------+---+
| _1| _2| _3|
+---+--------+---+
| 1|zahngsan| 30|
| 2| lisi| 33|
| 3| wangwu| 35|
+---+--------+---+
or
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zahngsan| 30|
| 2| lisi| 33|
| 3| wangwu| 35|
+---+--------+---+
实际开发中,一般通过样例类将RDD转换为DataFrame
case class User(id:Int,name:String, age:Int)
val rdd3 = sc.makeRDD(List((1,"zahngsan",30),(2,"lisi",33),(3,"wangwu",35)))
rdd3..map(t=>User(t._1, t._2,t._3)).toDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zahngsan| 30|
| 2| lisi| 33|
| 3| wangwu| 35|
+---+--------+---+
DataFrame转换为RDD 【df.rdd】
DataFrame其实就是对RDD的封装,所以可以直接获取内部的RDD
对上述的df进行一下操作即可
df.rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
注意:此时得到的RDD存储类型为Row
array(0)
res28: org.apache.spark.sql.Row = [zhangsan,30]
array(0)(0)
Any = zhangsan
array(0).getAs[String]("name")
res30: String = zhangsan
RDD转换为DataSet【rdd[样例类].toDS】
SparkSQL能够自动将包含有case类的RDD转换成DataSet,case类定义了table的结构,
case类属性通过反射变成了表的列名。Case类可以包含诸如Seq或者Array等复杂的结构
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
DataSet转换为RDD 【dS.rdd】
DataFrame转换为DataSet val ds = df.as[User]
DataSet转换为DataFrame val df = ds.toDF
RDD中只有数据 DataFrame有结构 DataSet有类型

3.spark与Hive交互
3.1内嵌Hive应用
内嵌Hive,元数据存储在Derby数据库。
直接输入./bin/spark-shell 即可使用
spark.sql("show tables").show
执行完后,发现多了$SPARK_HOME/metastore_db和derby.log,用于存储元数据
spark.sql("create table user(id int, name string)")
执行完后,发现多了$SPARK_HOME/spark-warehouse/user,用于存储数据库数据
然而在实际使用中,几乎没有任何人会使用内置的Hive,因为元数据存储在derby数据库,不支持多客户端访问。
3.2外部Hive应用
Spark要连接外部的hive,需要以下步骤
1.开启dfs和yarn并保证hive是正常工作的
start-dfs.sh start-yarn.sh bin/hive
2.需要把hive-site.xml拷贝到spark的conf/目录下
3.把MySQL的驱动copy到Spark的jars/目录下
4.如果hive中配置了metastore,得需要启动metastore服务 hive --service metastore 启动之后会占用一个窗口 如果没有,省略这一步
5.启动hiveserver2服务,hive --service hiveserver2
4.启动spark-shell(Hive on Spark)
1.开启dfs和yarn并保证hive是正常工作的
start-dfs.sh start-yarn.sh bin/hive
2.需要把hive-site.xml拷贝到spark的conf/目录下
3.把MySQL的驱动copy到Spark的jars/目录下
4.如果hive中配置了metastore,得需要启动metastore服务 hive --service metastore 如果没有,省略这一步
5.启动start-thriftserver.sh,在$SPARK_HOME/sbin目录下
4.启动spark-shell(SparkSql)