大数据需求衍生出的各种框架
1.
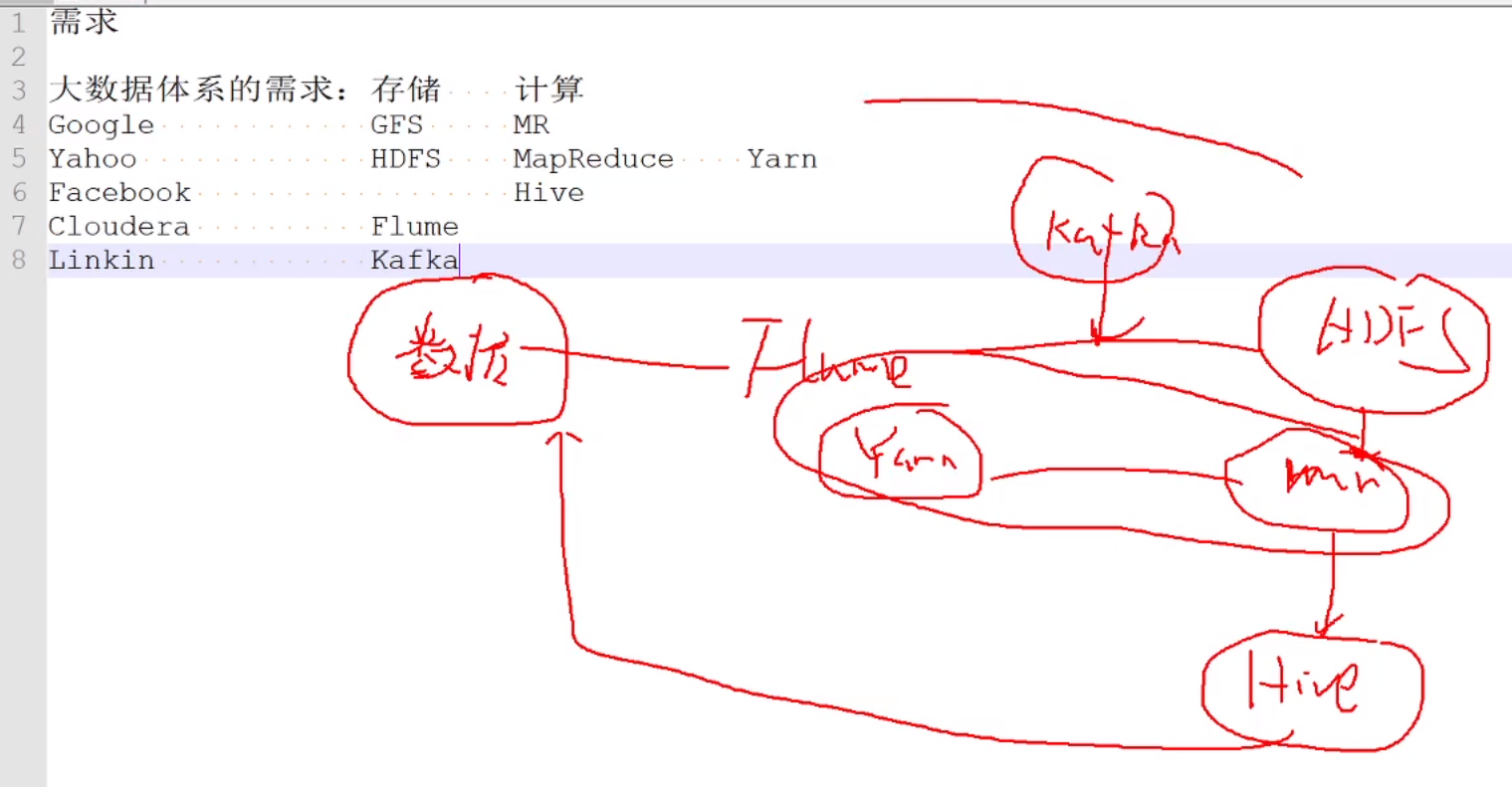
早期的MR 资源分配 计算 后来yarn 引入 作为资源分配
hive 将mr包装成sql 减少代码量
flume 端口 日志 mysql 音频 图片 数据
来源-去向 单独写一段代码 有flume 一个配置文件
kafka
flume-kafka-spark(hdfs)
峰值150 spark 100
不稳定 波峰波谷 蓄水池 消息队列(kafka)
zookeeper 为去中心的框架 作为协调中心 kafka HA
HDFS 解决了存储的问题 思路:分布式存储(一台计算机存不下,多台存)namenode 存储元数据 block映射文件的位置 保存文件到块的映射 datanode 存储具体数据 分布式存储到block中
分布式计算 分布式计算框架(mapreduce spark) 将一个计算任务 拆分成多个计算任务 分布式资源调度框架(yarn)
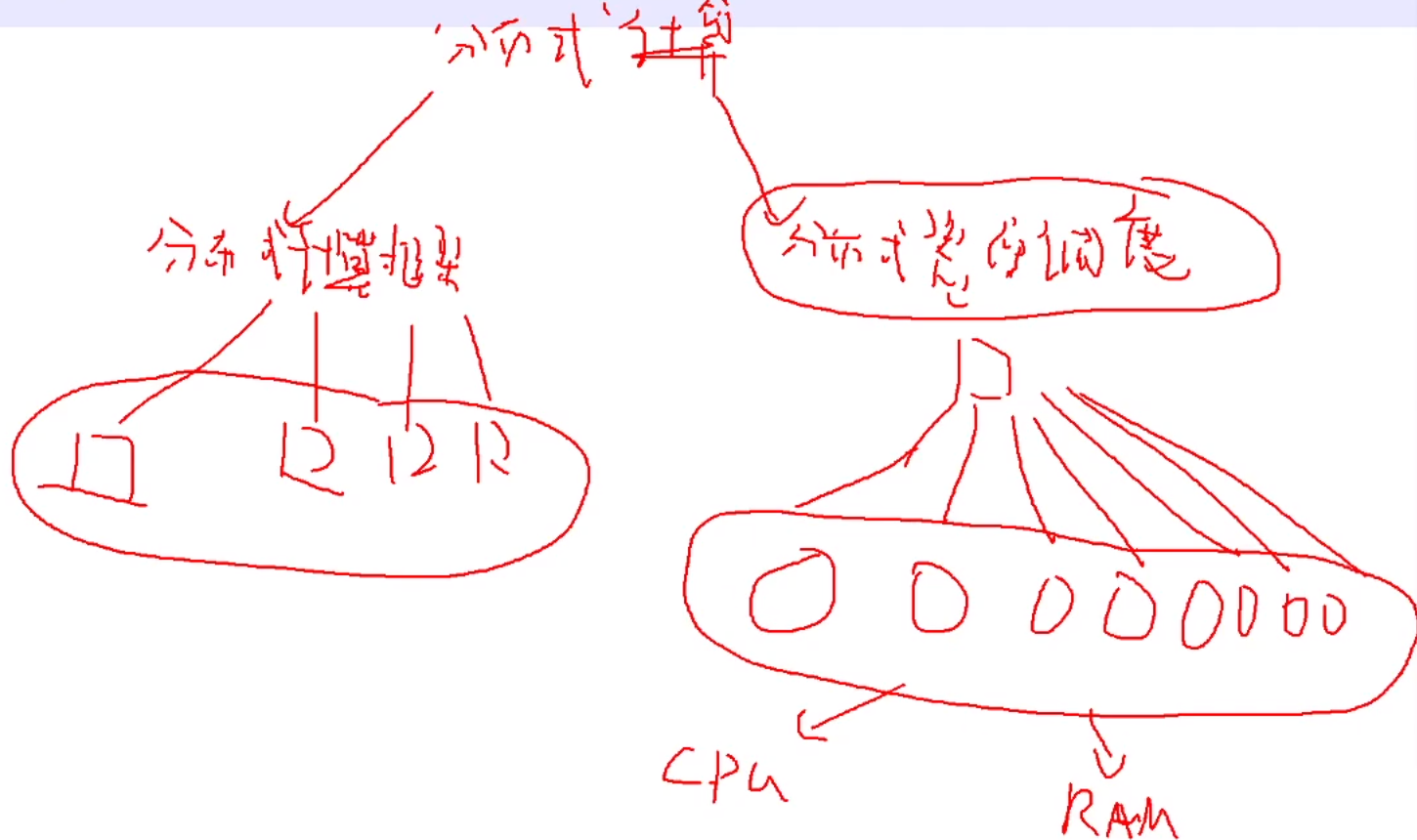
nodemanage负责管理每个节点的资源 resorucemanage 负责汇总每个节点的资源情况
hadoop 第三章 fileInputFormat切片机制
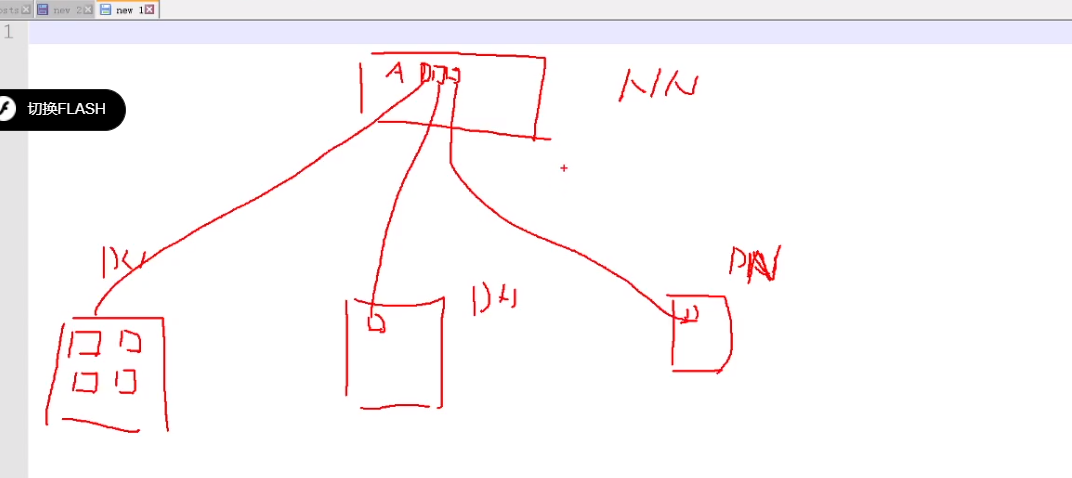
maptask 如何拆分任务
1GB 切片 分成多个计算任务
reducetask如何拆分任务
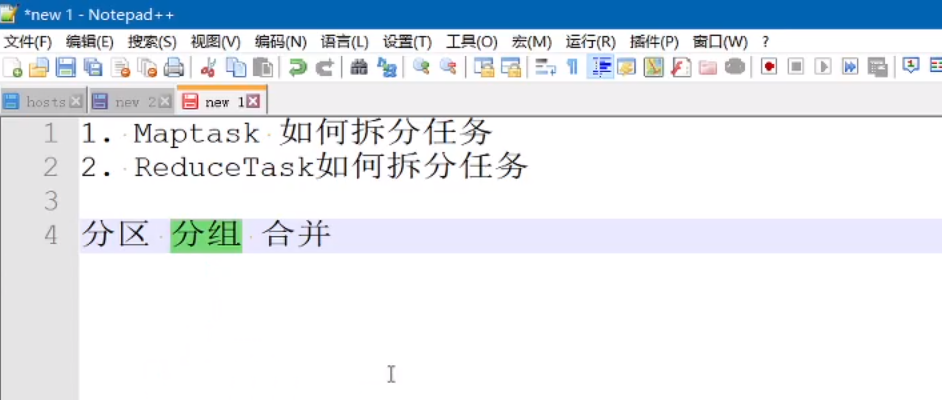
分区