Hive 的函数
1.系统内置函数
1)查看系统自带的函数
show functions;
show functions like "*date*";
2)显示自带的函数的用法
desc function upper;
desc function 'current_date' 记住带下划线的需要加上引号
3)详细显示自带的函数的用法
desc function extended upper;
2.常用内置函数
2.1 空字段赋值
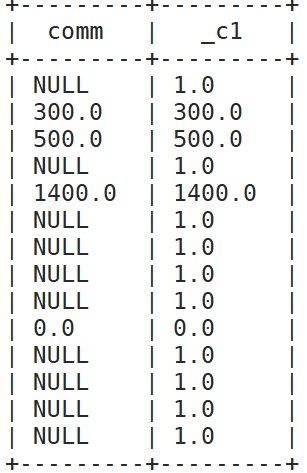
NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则
返回NULL。
例如: select comm,nvl(comm, 1) from emp;
2.2 CASE WHEN
1)数据准备
name dept_id sex
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
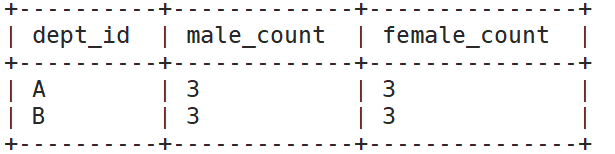
2)需求
求出不同部门男女各多少人。结果如下:
A 2 1
B 1 2
3)创建本地emp_sex.txt,导入数据
vi emp_sex.txt
4)创建hive表并导入数据
create table emp_sex (
name string,
dept_id string,
sex string)
row format delimited fields terminated by " ";
load data local inpath '/opt/module/datas/emp_sex.txt' into table emp_sex;
5)按需求查询数据
select
dept_id,
count(case sex when '男' then 1 else 0 end) male_count,
count(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;

选择第二种方式 因为count(*),count(n) 不管n为几,都要累加,所以看到的都是3 而sum(n) n为0时不累加 为1 时加1
2.3 行转列 列转行
1)相关函数说明 行转列是按照一定的维度进行数据聚合
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
concat(constellation,",",blood_type)
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。
这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
concat_ws("|",collect_list(name))
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
2)数据准备
name constellation blood_type
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
3)需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋|苍老师
4)创建本地constellation.txt,导入数据
vi constellation.txt
5)创建hive表并导入数据
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by " ";
load data local inpath "/opt/module/datas/constellation.txt" into table person_info;
6)按需求查询数据
select
concat(constellation,",",blood_type) xzxx,
concat_ws("|",collect_list(name)) people
from
person_info
group by constellation,blood_type;

列转行
1)函数说明
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。 split 可以使字符串变成array类型的数据,常常配合使用
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2)数据准备
movie category
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
3)需求
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
4)创建本地movie.txt,导入数据
vi movie.txt
5)创建hive表并导入数据
create table movie_info(
movie string,
category string)
row format delimited fields terminated by " ";
load data local inpath "/opt/module/datas/movie.txt" into table movie_info;
6)按需求查询数据
select
m.movie,
tbl.cate
from
movie_info m
lateral view
explode(split(category, ",")) tbl as cate;

2.4.窗口函数
不是孤立使用的,结合其他函数使用
1.为聚合函数提供操作的窗口 (案例 1,2,3)
2.配合一些其他函数使用(有序窗口 即需要排序) (案例 4,5) 两套写法分区排序 partition by ... order by ... distribute by ... sort by ...
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
必须是有序窗口 即 必须包含 order by
准备数据
vi business.txt
name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
创建hive表并导入数据
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/datas/business.txt" into table business;
(1)查询在2017年4月份购买过的顾客及总人数
select
distinct name,
count(distinct name) over() total
from
business
where
substring(orderdate,1,7) = '2017-04';
或者
select name,count(*) over ()
from business
where substring(orderdate,1,7) = '2017-04'
group by name;
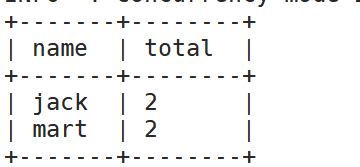
(2)查询顾客的购买明细及月购买总额
select
*,
sum(cost) over (partition by substring(orderdate,1,7)) month_total
from
business;
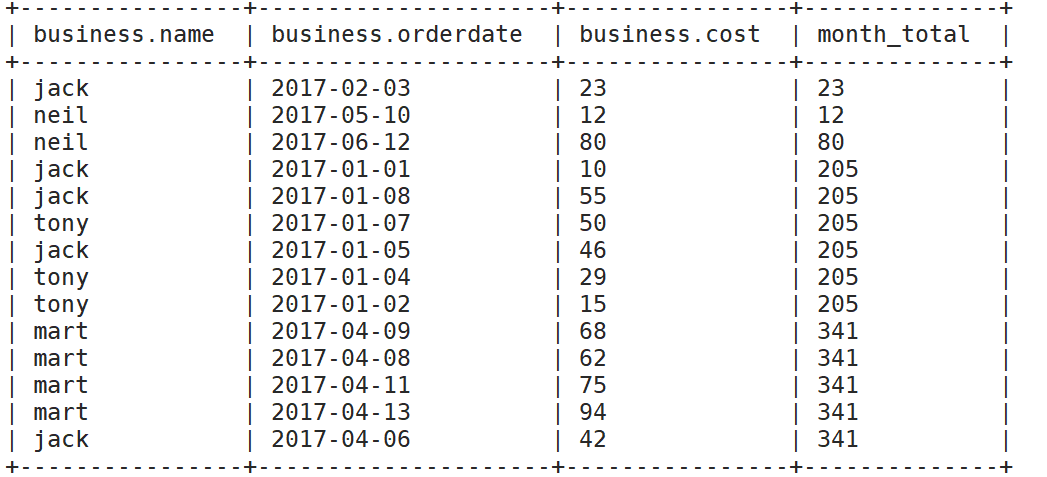
(3)上述的场景, 将每个顾客的cost按照日期进行累加
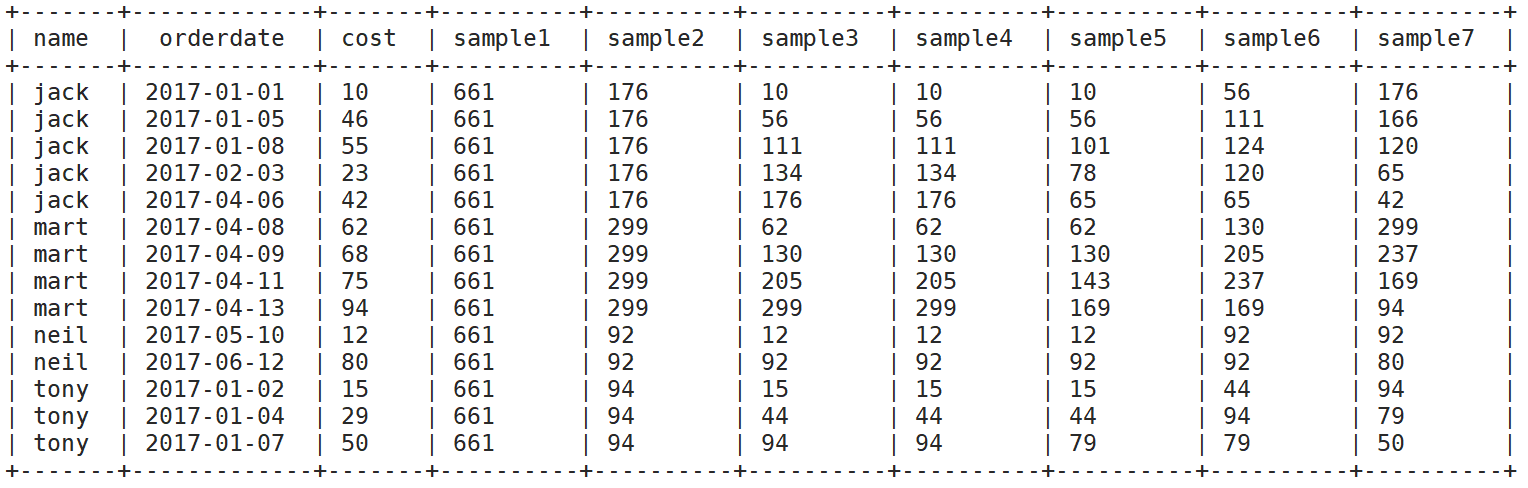
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
最后的窗口是分区排过序的 因为在hive中窗口函数是最后执行的,在select中把前面的先选出来,然后再一列一列的执行窗口函数,每增加一个窗口函数,会给job增加一个mapreduce,上述列
子就会增加三个mapreduce,三个窗口函数先算第一个,依次计算,一共三个,最后结果按照最后一个为准 ,因为最后一个是安装分区排序的。
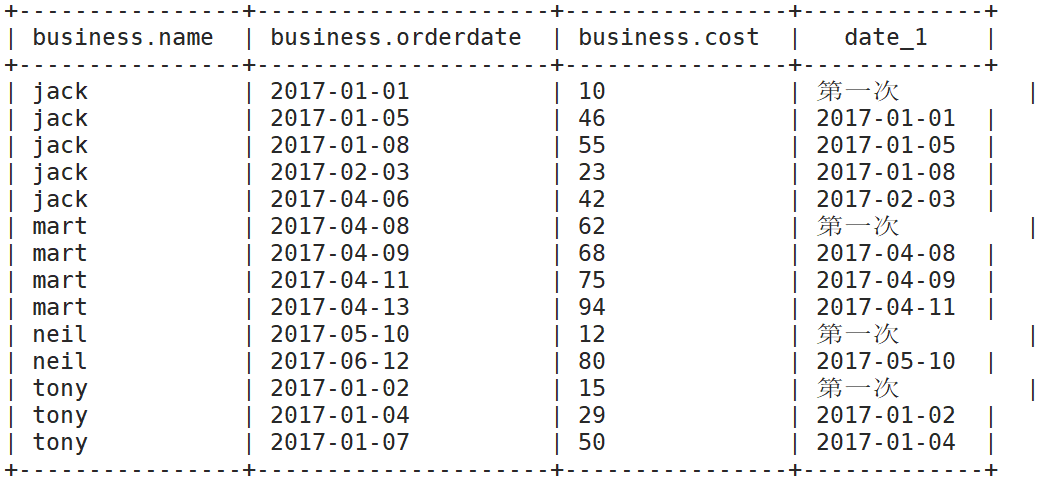
(4)查看顾客上次的购买时间
select
*,
LAG(orderdate,1,'第一次') over (partition by name order by orderdate ) date_1
lead(orderdate,1,'最后一次') over (partition by name order by orderdate ) next_date_1//案例时不需要 补充
from
business;
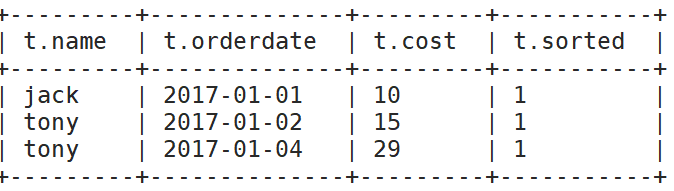
(5)查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
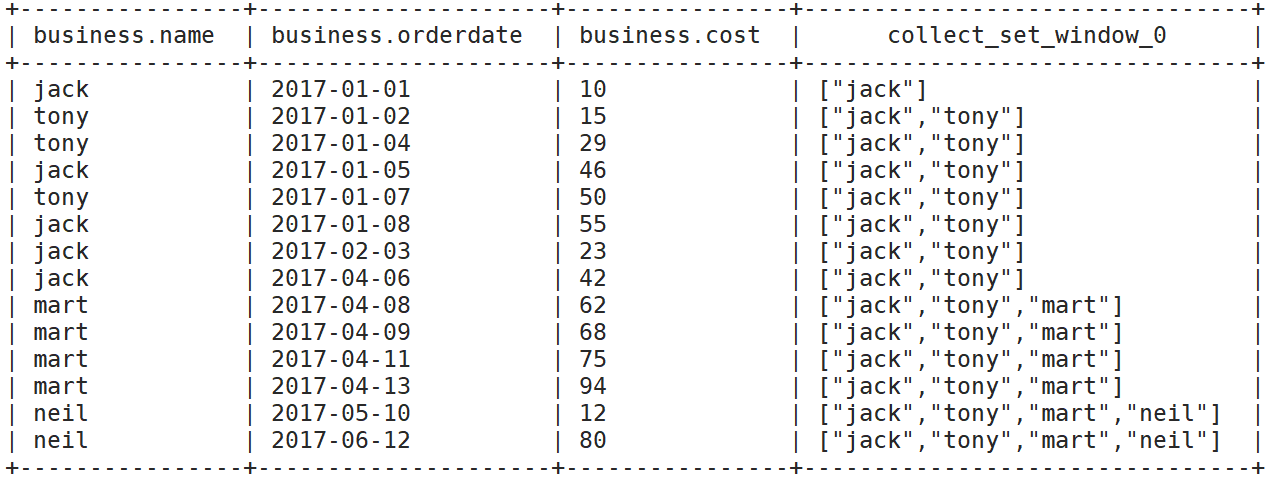
(6)将营业额数据按日期顺序排好之后,求截止到每一天光顾过的所有顾客
select
*,
collect_set(name) over(order by orderdate rows between unbounded preceding and current row)
from
business;
2.5.RANK (必须针对有序窗口进行rank)
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
percent_rank() 0-1区间 求17%的订单信息 参考上述第5题 假如一共10行数据,中间就会有9个空当,也就是说会怎加9次到1 每次会增加1/9 如果遇到相同数据 处理方式和rank 一样
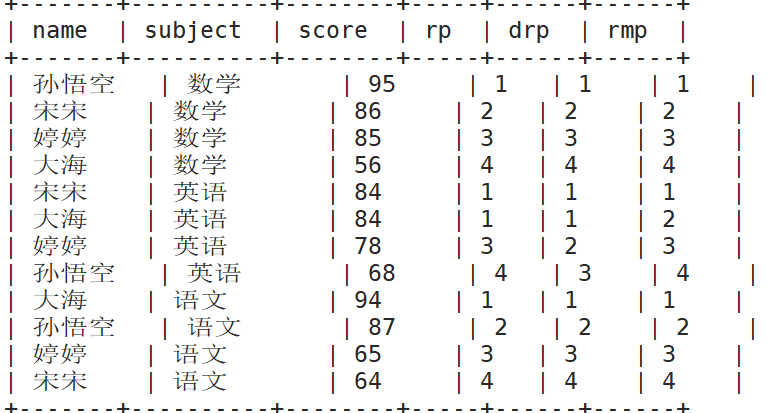
1)数据准备
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
vi score.txt
2)创建hive表并导入数据
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by " ";
load data local inpath '/opt/module/datas/score.txt' into table score;
3)计算每门学科成绩排名。
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp,
percent_rank() over(partition by subject order by score desc) pr
from score;