关于爬虫程序的418+403报错。
1.按F12打开“开发者调试页面“
如下图所示:按步骤,选中Network,找到使用的接口,获取到浏览器访问的信息。
我们需要把自己的python程序,伪装成浏览器。
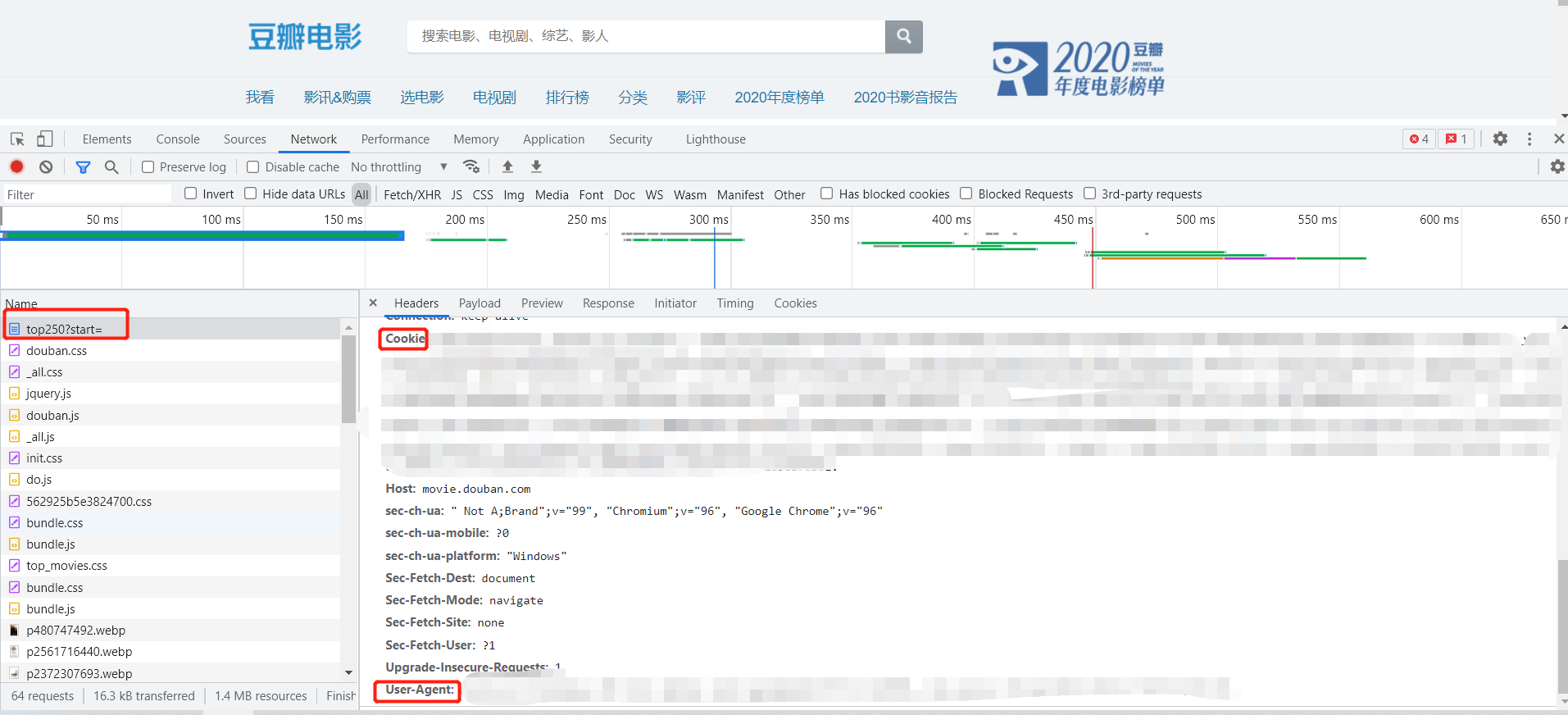
第一个user—agent
第二个就是cookie信息(简单理解就是我们的登陆信息。)
1.在head信息加入 user—agent可以模拟浏览器访问
不加此信息,会报418错误。
长期访问会有403报错。
2.在head中加入cookie信息,然后调用,(为的是模拟我们用户的登陆)
关于爬虫程序的418+403报错。
1.按F12打开“开发者调试页面“
如下图所示:按步骤,选中Network,找到使用的接口,获取到浏览器访问的信息。
我们需要把自己的python程序,伪装成浏览器。
第一个user—agent
第二个就是cookie信息(简单理解就是我们的登陆信息。)
1.在head信息加入 user—agent可以模拟浏览器访问
不加此信息,会报418错误。
长期访问会有403报错。
2.在head中加入cookie信息,然后调用,(为的是模拟我们用户的登陆)