建议2:编写pythonic代码
(1)要避免劣化代码
1)避免只用大小写来区分不同的对象
2)避免使用容易引起混淆的名称
3)不要害怕过长的变量名
(2)深入认识python有助于编写pythonic代码
使用PEP8来检查代码规范
pip install -U pep8 (python3改为pip install pycodestyle)
pep8 --first finame
使用--show-source显示每一行错误和警告
pep8 --show-source filename
建议6:编写函数的四个原则
1.函数设计要尽量短小,嵌套层次不宜过深
2.函数声明应该做到合理,简单,易于使用
3.函数参数设计应该考虑向下兼容
4.一个函数只做一件事,尽量保证函数语句粒度一致性
建议七:将常量集中到一个文件
两种方式使用常量:
一、通过命名风格来提醒使用者该变量代表的意义为常量,如常量名所有字母大写,用下划线连接各个单词,然而这种方式并没有实现真正的常量 ,其对应的值仍然可以改变,这是一种约定俗成的风格。
二、通过自定义的类实现常量功能。这要求符合“命名全部为大写“和”值一旦绑定便不可再修改“这两个条件。
class _const: class ConstError(TypeError): pass class ConstCaseError(ConstError): pass def __init__(self): pass def __setattr__(self, key, value): if key in self.__dict__: raise self.ConstError("Can't change const.%s" % key) if not key.isupper(): raise self.ConstCaseError("const name %s is not all uppercase" % key) self.__dict__[key] = value
import sys from pythonic_2day.const.const_demo import _const sys.modules[__name__] = _const() _const.MY_LOVE = "alex" _const.MY = "admin" _const.YOU = "allin"
建议8:利用assert语句来发现问题
x = 1 y = 2 assert x == y, "not ="
断言是有代价的,会对性能产生一定的影响,通常python用断言的方法 是在运行脚本的时候加上-O标志,这种方式带来的影响是它并不优化代码 ,而是忽略与断言相关的语句
如:python -O asserttest.py便可以禁用断言
断言实际是被设计用来捕获用户所定义的约束的,而不是用来捕获程序本身错误的,使用断言需要注意以下几点:
1)不要滥用,这是使用断言最基本的原则,若由于断言引发了异常,通常代表程序中存在BUG,因此断言应该使用在正常逻辑不可到达的地方或正常情况下部是为真的场合;
2)如果Python本身的异常能够处理就不要再使用断言;
3)不要使用断言来检查用户的输入;
4)在函数调用后,当需要确认返回值是否合理时可以使用断言;
5)当条件是业务逻辑继续下去的先决条件时可以使用断言。
建议10:充分利用Lazy evaluation的特性
Lazy evaluation常被译为“延迟计算”或“惰性计算”,指的是仅仅在真正需要执行的时候才计算表达式的值,充分利用Lazy evaluation的特性带来的好处主要体现在以下两个方面:
1)避免不必要的计算,带来性能上的提升。如if x and y,在x为false的情况下y表达式的值将不再计算。
from time import time from gevent._compat import xrange t = time() abbreviations = ['cf.', 'e.g.', 'ex.', 'etc.', 'fig.', 'i.e', 'Mr.', 'vs.'] for i in xrange(1000000): for w in ('Mr.', 'HAT', 'is', 'chasing', 'the', 'black', 'cat', '.'): if w[-1] == '.' and w in abbreviations: # if w in abbreviations: pass print('total run time:') print(time() - t)
如果使用注释行代替第一个if,运行的埋单大约会节省10%。因此在编程过程中,如果对于or条件表达式应该将值为真可能性较高的变量写在or的前面,而and则应该推后。
2)节省空间,使得无限循环的数据结构成为可能。
def fib(): a, b = 0, 1 while True: yield a a, b = b, a + b from itertools import islice print(list(islice(fib(), 5)))
建议12:不推荐使用type来进行类型检查
class UserInt(int): def __init__(self, val=0): super().__init__() self._val = int(val) def __add__(self, other): if isinstance(other, UserInt): return UserInt(self._val + other._val) return self._val + other def __iadd__(self, other): raise NotImplementedError("not support operation") def __str__(self): return str(self._val) def __repr__(self): return "Integer(%s)" % self._val n = UserInt() print(n) m = UserInt(2) print(m) print(n+m) print(type(n) is int)
对于内建的基本类型来说,也许使用type()进行类型检查问题不大,但在某些特殊场合type()方法并不可靠。可以使用isinstance(obj, classinfo)。
其中classinfo可以为直接或间接类名、基本类型名称或者由它们组成的元组,该函数在classinfo参数错误的情况下会抛出TypeError异常。
建议14:警惕eval()的安全漏洞
如果使用对象不是信任源,应该尽量避免使用eval,在需要使用eval的地方可用安全性更好的ast.literal_eval替代。
建议15:使用enumerate()获取序列迭代的索引和值
for i, e in enumerate(li): print("index: ", i, "element: ", e)
它具有一定的惰性(lazy),每次仅在需要的时候才会产生一个(index, item)对。其函数签名如下:
enumerate(sequence, start=0)
其中sequence为任何可迭代的对象,实际相当于如下代码:
def enumerate(sequence, start=0): n = start for elem in sequence: yield n, elem n += 1
对于字典的迭代循环,enumerate()函数并不适合,虽然在使用上并不会提示错误,但输出的结果与期望的大相径庭,这是因为字典默认被转换成了序列进行处理
建议16:分清==与is的适用场景
is 表示的是对象标示符,而 == 表示的意思是相等,显然两者不是一个东西。is 的作用是用来检查对象的标示符是否一致的,也就是比较两个对象在内存中是否拥有同一块内存空间,它并不适合用来判断两个字符串是否相等,x is b 基本相当于 id(x) == id(y)。而 == 才是用来检验两个对象的值是否相等的。
Python中的string interning (字符串驻留)机制:
对于较小的字符串,为了提高系统性能会保留其值的一个副本,当创建新的字符串的时候直接指向该副本即可。
建议19:有节制地使用from...import语句
使用import的时候注意以下几点:
1)一般情况下尽量优先使用import a 形式,如访问B时需要使用a.B的形式;
2)有节制地使用from a import B形式,可以直接访问B;
3)尽量避免使用from a import *,因为 会污染命名空间,并且无法清晰地表示导入了哪些对象。

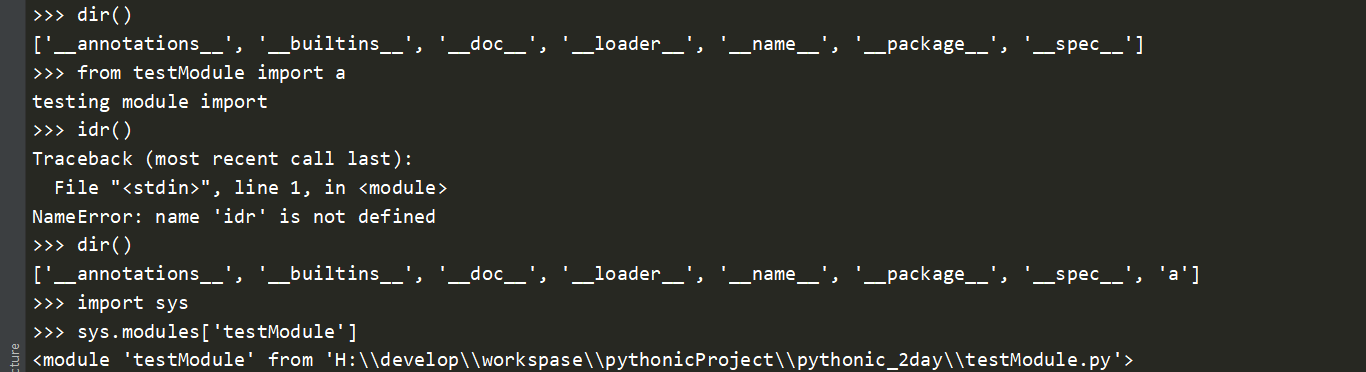
循环嵌套导入的问题:
c1.py
from c2 import g def x(): pass
c2.py
from c1 import x def g(): pass
无论运行上面哪一个文件都会抛出ImportError异常。这是因为在执行c1.py的加载过程中,需要创建新的模块对象c1然后执行c1.py所对应的字节码。此时遇到语句from c2 imort g,而c2在sys.modules也不存在,故此时创建c2对应的模块对象并执行c2.py所对应的字节码。当遇到c2中的语句from c1 import x时,由于c1已经存在,于是便去其对应的字典中查找g,但c1模块对象虽然创建但初始化的过程并未完成,因此其对应的字典中并不存在g对象,此时便抛出ImportError:cannot import name g异常。而解决循环嵌套导入问题的一个方法是直接使用import 语句。
建议22:使用with自动关闭资源
with open('test.txt', 'w') as f: f.write("test")
with语句可以在代码块执行完毕后还原进入该 代码块时的现场,包含有with语句的代码块的执行过程如下:
1)计算表达式的值,返回一个上下文管理对象;
2)加载上下文管理器对象的__exit__()方法以备后用;
3)调用上下文管理器对象的__enter__()方法;
4)如果with语句中设置了目标对象,则将__enter__()方法的返回值赋值给目标对象;
5)执行with中的代码块;
6)如果步骤5中代码正常结束,调用上下文管理器对象的__exit__()方法,其返回值直接忽略;
7)如果步骤5中代码执行过程中发生异常,调用上下文管理器的__exit__()方法,并将异常类型、值及traceback信息作为参数传递给__exit__()方法。如果__exit__()返回值为false,则异常会被重新抛出;如果其返回值为true,,异常被挂起,程序继续执行。
建议26:深入理解None,正确判断对象是否为空
__nonzero__()方法:该内部 方法用于对自身对象进行空值判断,返回 0/1 或 True/False 。如果一个对象没有定义该方法,Python将获取__len__()方法调用的结果来时行判断。__len__()返回值为0则表示为空。如果一个类既没有定义__len__()方法也没有定义__nonzero__()方法,该类的实例用if判断的结果都为True:
class A: def __nonzero__(self): print("testing A.__nonzero__()") return True def __len__(self): print("get length") return False if A(): print("not empty") else: print("empty")
建议27:连接字符串应优先使用join而不是+
join()方法连接字符串的时候,会首先计算需要申请的总的内在空间,然后一次性申请所需内存并将字符序列中的每一个元素复制到内存中去,所以join操作的时间复杂度为O(n);
+执行一次+操作便会在内存中申请一块新的内存空间,并将上一次操作的结果和本次操作的右操作数复制到新申请的空间.....所以+操作的时间复杂度为O(n*n)
建议28:格式化字符串时尽量使用.format方式而不是%
建议31:记住函数传参既不是传值也不是传引用
应该是传对象,或者说传对象的引用。函数传参在传递过程中将整个对象传入,对可变对象的修改在函数外部以及内部都可见,调用者和被调用者之间共享这个对象。而对于不可变对象,由于并不能真正被修改,因此,修改往往是通过生成一个新对象然后 赋值来实现的