1.如何度量Zabbix性能
通过Zabbix的NVPS(每秒处理数值数)来衡量其性能。
在Zabbix的dashboard上有一个错略的估值。
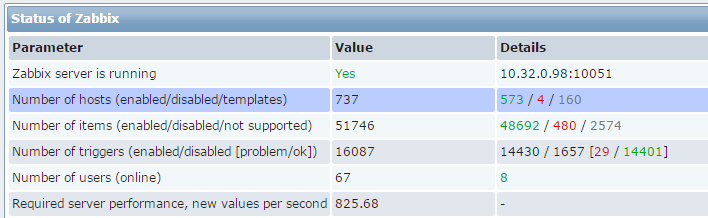
在4核CPU,6GB内存,RAID10(带有写入缓存)这样的配置条件下,Zabbix可以处理每分钟1M个数值,大约每秒15000个
2.性能低下的可见症兆
- zabbix队列中有太多被延迟的item: Administration -> Queue
- zabbix绘图中经常性出现断档,一些item没有数据
- 带有nodata()函数的触发器出现false
- 前端页面无响应
3.哪些因素造成Zabbix性能低下

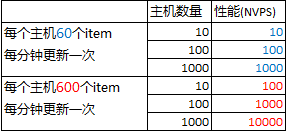
主机数量也是影响性能的主要因素
4.了解Zabbix工作状态
获得zabbix内部状态
zabbix[wcache,values,all]
zabbix[queue,1m] ----延迟超过1分钟的item
获得zabbix内部组件工作状态(该组件处于BUSY状态的时间百分比)
zabbix[process,type,mode,state]
其中可用的参数为:
type: trapper,discoverer,escalator,alerter,etc
mode: avg,count,min,max
state: busy,idel
5.Zabbix调优大的原则性建议
- 确保zabbix内部组件性能处于被监控状态(调优的基础!)
- 使用硬件性能足够好的服务器
- 不同角色分开,使用各自独立的服务器
- 使用分布式部署
- 调整MySQL性能
- 调整Zabbix自身配置
6.Zabbix数据库调优
a.使用专用数据服务器,配置应该较高
给一个参考配置,可以处理NVPS为3000
Dell PowerEdge R610
CPU: Intel Xeon L5520 2.27GHz (16 cores)
Memory: 24GB RAM
Disks: 6x SAS 10k 配置 RAID10
b.每个table一个文件,修改my.cnf
innodb_file_per_table=1
c.使用percona替代MySQL
d.使用分区表,关闭Houerkeeper
关闭Houserkeeper,zabbix_server.conf
DisableHousekeeper=1
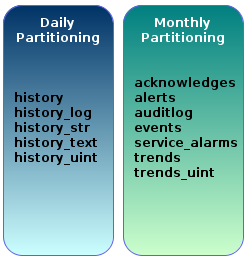
step 1.准备相关表
ALTER TABLE `acknowledges` DROP PRIMARY KEY, ADD KEY `acknowledgedid` (`acknowledgeid`);
ALTER TABLE `alerts` DROP PRIMARY KEY, ADD KEY `alertid` (`alertid`);
ALTER TABLE `auditlog` DROP PRIMARY KEY, ADD KEY `auditid` (`auditid`);
ALTER TABLE `events` DROP PRIMARY KEY, ADD KEY `eventid` (`eventid`);
ALTER TABLE `service_alarms` DROP PRIMARY KEY, ADD KEY `servicealarmid` (`servicealarmid`);
ALTER TABLE `history_log` DROP PRIMARY KEY, ADD PRIMARY KEY (`itemid`,`id`,`clock`);
ALTER TABLE `history_log` DROP KEY `history_log_2`;
ALTER TABLE `history_text` DROP PRIMARY KEY, ADD PRIMARY KEY (`itemid`,`id`,`clock`);
ALTER TABLE `history_text` DROP KEY `history_text_2`;
step2.设置每月的分区
以下步骤请在第一步的所有表中重复,下例是为events表创建2011-5到2011-12之间的月度分区。
ALTER TABLE `events` PARTITION BY RANGE( clock ) (
PARTITION p201105 VALUES LESS THAN (UNIX_TIMESTAMP("2011-06-01 00:00:00")),
PARTITION p201106 VALUES LESS THAN (UNIX_TIMESTAMP("2011-07-01 00:00:00")),
PARTITION p201107 VALUES LESS THAN (UNIX_TIMESTAMP("2011-08-01 00:00:00")),
PARTITION p201108 VALUES LESS THAN (UNIX_TIMESTAMP("2011-09-01 00:00:00")),
PARTITION p201109 VALUES LESS THAN (UNIX_TIMESTAMP("2011-10-01 00:00:00")),
PARTITION p201110 VALUES LESS THAN (UNIX_TIMESTAMP("2011-11-01 00:00:00")),
PARTITION p201111 VALUES LESS THAN (UNIX_TIMESTAMP("2011-12-01 00:00:00")),
PARTITION p201112 VALUES LESS THAN (UNIX_TIMESTAMP("2012-01-01 00:00:00"))
);
step3.设置每日的分区
以下步骤请在第一步的所有表中重复,下例是为history_uint表创建5.15到5.22之间的每日分区。
ALTER TABLE `history_uint` PARTITION BY RANGE( clock ) (
PARTITION p20110515 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-16 00:00:00")),
PARTITION p20110516 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-17 00:00:00")),
PARTITION p20110517 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-18 00:00:00")),
PARTITION p20110518 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-19 00:00:00")),
PARTITION p20110519 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-20 00:00:00")),
PARTITION p20110520 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-21 00:00:00")),
PARTITION p20110521 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-22 00:00:00")),
PARTITION p20110522 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-23 00:00:00"))
);
手动维护分区:
增加新分区
ALTER TABLE `history_uint` ADD PARTITION (
PARTITION p20110523 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-24 00:00:00"))
);
删除分区(使用Housekeepeing)
ALTER TABLE `history_uint` DROP PARTITION p20110515;
step4.自动每日分区
确认已经在step3的时候为history表正确创建了分区。
以下脚本自动drop和创建每日分区,默认只保留最近3天,如果你需要更多天的,请修改
@mindays 这个变量。
不要忘记将这条命令加入到你的cron中!
mysql -B -h localhost -u zabbix -pPASSWORD zabbix -e "CALL create_zabbix_partitions();"
自动创建分区的脚本:
https://github.com/xsbr/zabbixzone/blob/master/zabbix-mysql-autopartitioning.sql
DELIMITER //
DROP PROCEDURE IF EXISTS `zabbix`.`create_zabbix_partitions` //
CREATE PROCEDURE `zabbix`.`create_zabbix_partitions` ()
BEGIN
CALL zabbix.create_next_partitions("zabbix","history");
CALL zabbix.create_next_partitions("zabbix","history_log");
CALL zabbix.create_next_partitions("zabbix","history_str");
CALL zabbix.create_next_partitions("zabbix","history_text");
CALL zabbix.create_next_partitions("zabbix","history_uint");
CALL zabbix.drop_old_partitions("zabbix","history");
CALL zabbix.drop_old_partitions("zabbix","history_log");
CALL zabbix.drop_old_partitions("zabbix","history_str");
CALL zabbix.drop_old_partitions("zabbix","history_text");
CALL zabbix.drop_old_partitions("zabbix","history_uint");
END //
DROP PROCEDURE IF EXISTS `zabbix`.`create_next_partitions` //
CREATE PROCEDURE `zabbix`.`create_next_partitions` (SCHEMANAME varchar(64), TABLENAME varchar(64))
BEGIN
DECLARE NEXTCLOCK timestamp;
DECLARE PARTITIONNAME varchar(16);
DECLARE CLOCK int;
SET @totaldays = 7;
SET @i = 1;
createloop: LOOP
SET NEXTCLOCK = DATE_ADD(NOW(),INTERVAL @i DAY);
SET PARTITIONNAME = DATE_FORMAT( NEXTCLOCK, 'p%Y%m%d' );
SET CLOCK = UNIX_TIMESTAMP(DATE_FORMAT(DATE_ADD( NEXTCLOCK ,INTERVAL 1 DAY),'%Y-%m-%d 00:00:00'));
CALL zabbix.create_partition( SCHEMANAME, TABLENAME, PARTITIONNAME, CLOCK );
SET @i=@i+1;
IF @i > @totaldays THEN
LEAVE createloop;
END IF;
END LOOP;
END //
DROP PROCEDURE IF EXISTS `zabbix`.`drop_old_partitions` //
CREATE PROCEDURE `zabbix`.`drop_old_partitions` (SCHEMANAME varchar(64), TABLENAME varchar(64))
BEGIN
DECLARE OLDCLOCK timestamp;
DECLARE PARTITIONNAME varchar(16);
DECLARE CLOCK int;
SET @mindays = 3;
SET @maxdays = @mindays+4;
SET @i = @maxdays;
droploop: LOOP
SET OLDCLOCK = DATE_SUB(NOW(),INTERVAL @i DAY);
SET PARTITIONNAME = DATE_FORMAT( OLDCLOCK, 'p%Y%m%d' );
CALL zabbix.drop_partition( SCHEMANAME, TABLENAME, PARTITIONNAME );
SET @i=@i-1;
IF @i <= @mindays THEN
LEAVE droploop;
END IF;
END LOOP;
END //
DROP PROCEDURE IF EXISTS `zabbix`.`create_partition` //
CREATE PROCEDURE `zabbix`.`create_partition` (SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
DECLARE RETROWS int;
SELECT COUNT(1) INTO RETROWS
FROM `information_schema`.`partitions`
WHERE `table_schema` = SCHEMANAME AND `table_name` = TABLENAME AND `partition_name` = PARTITIONNAME;
IF RETROWS = 0 THEN
SELECT CONCAT( "create_partition(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE `', SCHEMANAME, '`.`', TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DROP PROCEDURE IF EXISTS `zabbix`.`drop_partition` //
CREATE PROCEDURE `zabbix`.`drop_partition` (SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64))
BEGIN
DECLARE RETROWS int;
SELECT COUNT(1) INTO RETROWS
FROM `information_schema`.`partitions`
WHERE `table_schema` = SCHEMANAME AND `table_name` = TABLENAME AND `partition_name` = PARTITIONNAME;
IF RETROWS = 1 THEN
SELECT CONCAT( "drop_partition(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE `', SCHEMANAME, '`.`', TABLENAME, '`',
' DROP PARTITION ', PARTITIONNAME, ';' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DELIMITER ;
e.使用tmpfs存储临时文件
mkdir /tmp/mysqltmp
修改/etc/fstab:
tmfs /tmp/mysqltmp tmpfs rw,uid=mysql,gid=mysql,size=1G,nr_inodes=10k,mode=0700 0 0
修改my.cnf
tmpdir=/tmp/mysqltmp
f.设置正确的buffer pool
设置Innodb可用多少内存,建议设置成物理内存的70%~80%
修改my.cnf
innodb_buffer_pool_size=14G
设置innodb使用O_DIRECT,这样buffer_pool中的数据就不会与系统缓存中的重复。
innodb_flush_method=O_DIRECT
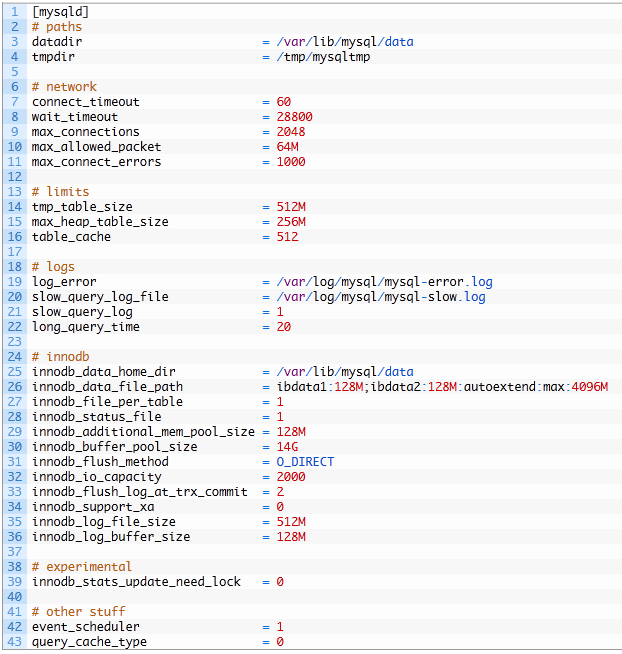
以下给一个示例my.cnf,物理内存大小为24G:
g.设置合适的log大小
zabbix数据库属于写入较多的数据库,因此设置大一点可以避免MySQL持续将log文件flush到表中。
不过有一个副作用,就是启动和关闭数据库会变慢一点。
修改my.cnf
innodb_log_file_size=64M
h.打开慢查询日志
修改my.cnf
log_slow_queries=/var/log/mysql.slow.log
i.设置thread_cache_size
这个值似乎会影响show global status输出中Threads_created per Connection的hit rate
当设置成4的时候,有3228483 Connections和5840 Threads_created,hit rate达到了99.2%
Threads_created这个数值应该越小越好。
j.其他MySQL文档建议的参数调整
query_cache_limit=1M
query_cache_size=128M
tmp_table_size=256M
max_heap_table_size=256M
table_cache=256
max_connections = 300
innodb_flush_log_at_trx_commit=2
join_buffer_size=256k
read_buffer_size=256k
read_rnd_buffer_size=256k
7.调整zabbix工作进程数量,zabbix_server.conf
StartPollers=90
StartPingers=10
StartPollersUnreacheable=80
StartIPMIPollers=10
StartTrappers=20
StartDBSyncers=8
LogSlowQueries=1000
参考文档:
http://www.slideshare.net/xsbr/alexei-vladishev-zabbixperformancetuning
http://zabbixzone.com/zabbix/mysql-performance-tips-for-zabbix/
http://zabbixzone.com/zabbix/partitioning-tables/
http://linux-knowledgebase.com/en/Tip_of_the_day/March/Performance_Tuning_for_Zabbix
http://sysadminnotebook.blogspot.jp/2011/08/performance-tuning-mysql-for-zabbix.html