scrapy基本知识
scrapy的整体架构
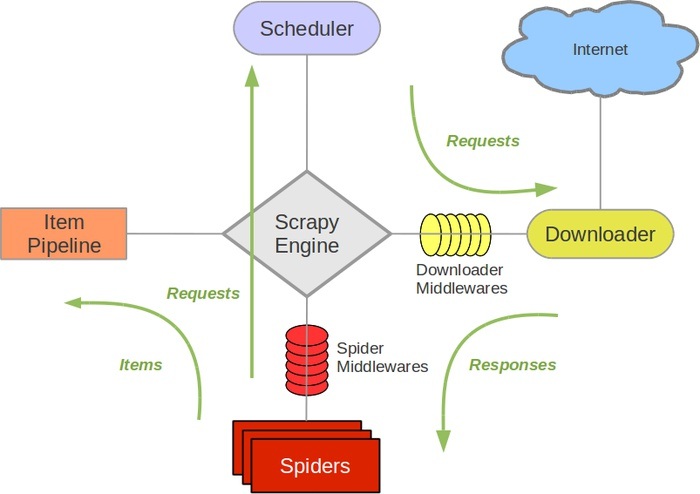
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回
- 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛
- 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站
- 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据
- 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
items
爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy提供 Item 类来满足这样的需求。
Spiders
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方
选择器(Selectors)
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
更多参考scrapy文档 https://docs.scrapy.org/en/latest/intro/tutorial.html
参考http://aljun.me/post/4
创建项目
scrapy startproject doubanread
定义Item
编辑item.py
# -*- coding: utf-8 -*- import scrapy class DoubanreadItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() book_name = scrapy.Field() book_url = scrapy.Field() book_star = scrapy.Field() book_about = scrapy.Field()
编写爬虫
import scrapy import sys from doubanread.items import DoubanreadItem reload(sys) sys.setdefaultencoding('utf8') class DoubanreadSpider(scrapy.Spider): name = "doubanread" allowed_domains = [] start_urls = [ "https://book.douban.com/tag/%E5%8E%86%E5%8F%B2?type=S" ] def parse(self, response): for sel in response.xpath('//li/div[2]'): item = DoubanreadItem() book_name = sel.xpath('h2/a/text()').extract() book_url = sel.xpath('h2/a/@href').extract() book_star = sel.xpath('div[2]/span[2]/text()').extract() book_about = sel.xpath('div[1]/text()').extract() item['book_name'] = [n.encode('utf-8') for n in book_name] item['book_url'] = [url for url in book_url] item['book_star'] = [s for s in book_star] item['book_about'] = [a.encode('utf-8') for a in book_about] yield item
处理数据,保存为json
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import sys import json import codecs reload(sys) sys.setdefaultencoding('utf8') class DoubanreadPipeline(object): def __init__(self): self.file = codecs.open('doubanread.json',mode='wb',encoding='utf-8') def process_item(self, item, spider): # 保存为txt文件 # filename = 'doubanread.txt' # with open(filename,'a') as fp: # for i in range(len(item['book_name'])): # fp.write(item['book_name'][i]+' '+item['book_star'][i]+' '+item['book_about'][i]+' '+item['book_url'][i]) # return item line = 'the new movie list:' + ' ' for i in range(len(item['book_star'])): book_name = {'book_name':str(item['book_name'][i]).replace(' ','')} book_star = {'book_star': item['book_star'][i].replace(' ','')} book_url = {'book_url': item['book_url'][i].replace(' ','')} book_about = {'book_about':str(item['book_about'][i]).replace(' ','').replace(' ','')} line = line + json.dumps(book_name, ensure_ascii=False) line = line + json.dumps(book_star, ensure_ascii=False) line = line + json.dumps(book_url,ensure_ascii=False) line = line + json.dumps(book_about,ensure_ascii=False) +' ' self.file.write(line) def close_spider(self,spider): self.file.close()
在settings.py加上一句:
ITEM_PIPELINES={ 'doubanread.pipelines.DoubanreadPipeline':300, }
访问服务器时可能出现403的代码,原因服务器识别到不是浏览器访问的反爬虫机制
可以在settings.py加上一句:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36
进入项目目录下,执行
scrapy crawl doubanread
生成新文件doubanread.json
