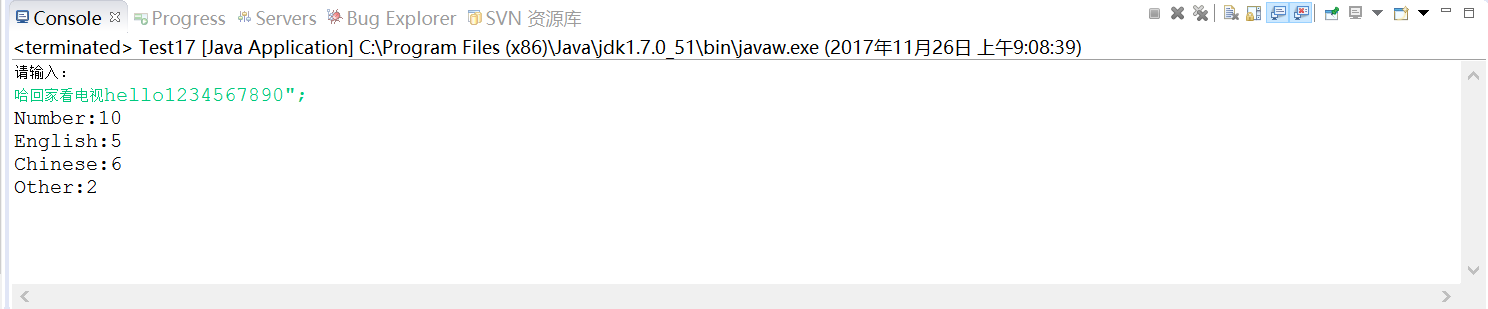
主要用正则表达式在完成对汉字,数字,英文数量的验证。
import java.util.Scanner; /* * 统计汉字,数字,英文,other * */ public class Test { public static int count(String text) { // 正则,这两个unicode值正好是Unicode表中的汉字的头和尾。"[]"代表里边的值出现一个就可以,后边的“+”代表至少出现1次,合起来即至少匹配一个汉字。 String Reg = "^[u4e00-u9fa5]{1}+"; int result = 0; for (int i = 0; i < text.length(); i++) { String b = Character.toString(text.charAt(i)); if (b.matches(Reg)) result++; } return result; } public static void main(String[] args) { System.out.println("请输入:"); Scanner scanner = new Scanner(System.in); String str=scanner.nextLine(); int length = str.length(); int nLen = length - str.replaceAll("\d", "").length();//由两部分组成的,转义符 加d是一个正字表达式,标识所有数字即0-9 int eLen = length - str.replaceAll("[a-zA-Z]", "").length();//标志所有英文 int cLen = count(str); int oLen=length - nLen - eLen - cLen;//其他 System.out.println("Number:" + nLen); System.out.println("English:" + eLen); System.out.println("Chinese:" + cLen); System.out.println("Other:"+oLen); } }
主要理解正则表达式。
输入一系列的字符,打印结果如下: