验证码发展历史
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是区分用户是机器或者是人的公共全自动程序。
早期的互联网是没有验证码的,由于搜索引擎的出现和网络营销的兴盛,导致了机器可以通过任何一个网站的注册的程序疯狂注册,通过垃圾邮件或者垃圾评论轰炸网民的眼球。作为免费邮件提供商,它们希望更多用户注册免费邮箱来增加用户注册数量。同时它们的免费邮箱又恰好是垃圾邮件的最爱,每天都耗费大量的资源来阻止的垃圾邮件,都来自自己的服务器。因此如何解决人机辨识的问题就迫在眉睫。
通过专家的设计,验证码应运而生,虫虫营销助手,刚开始计算机的辨识技术还很落后,对于经过扭曲,污染的文字无法识别。而人就能轻松识别。简单而绝妙的设计,计算机产生一个随机字符串,然后经过程序处理把这个字符串生成图像进行污染和扭曲,再在前端显示出来。凡能识别出来的就是人类。
刚开始的验证码比较简单,主要以4个字符串为主,字符串在图片中的位置中规中矩,有些机器通过字符串显示在图片上的一些客观规律,也非常容易破解验证码。由于机器的辨识能力在不断提高。中文验证码,8个字符或者以上的验证码,扭曲和污染非常严重的验证码在各大网站都频频出现(有时候人都不能识别)。小小的验证码也充满无穷商机,目前有些公司提供人工识别验证码服务。客户端的验证码通过api把图片提交给他们公司,公司安排人工(通常找一些人力成本相对低的国家的工人,这样导致一些特殊字符他们识别不了,例如中文等)识别,识别完后通过api返回给客户端。道高一尺,魔高一丈验证码的技术随着网络的发展还在不停地变化,但愿验证码的发展不要通过牺牲用户体验来换取。
验证码为什么要做成有两个单词这样,一个单词不就够了吗?
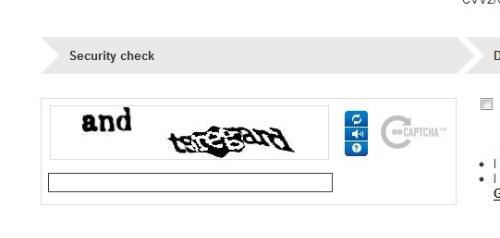
大家可以了解下,有个项目叫reCAPTCHA(http://baike.baidu.com/view/1944705.htm)
“CAPTCHA”的技术在2000年被发明时是为了防止垃圾邮件和不必要的骚扰,后来发明者又寻找到了使人的计算能力得到更有效利用的方法,发送两个单词,其中一个单词用来确认输入结果,另外一个机器无法识别的字符则随机发送给五个人,直到他们都输入正确才确认这个单词。这也是我们有时明明输错了最终也能登陆的原因。2009年谷歌收购了这家做验证码公司reCAPTCHA,并将其技术用于图书扫描项目,自此全世界的网民都沦为谷歌的免费打字员。。(因为众包的力量,这项技术每年能为谷歌省下十多亿美元。