0.展示PTA总分



1.本章学习总结
1.一维数组
- 1.定义和引用
- 一般形式:
类型名 数组名 [数组长度];这里数组长度必须是个常量! - c语言规定,数组名表示该函数所分配连续内存空间中第一个单元的地址,即首地址。数组空间一经分配,在运行过程中就不会再改变,因此<span style="color:red"数组名是一个地址常量,不允许改变。
- 数组下标从0开始,合理取值范围为[0,数组长度-1];
- 一般形式:
- 2.一维数组的初始化
- 一般形式:
类型名 数组名 [数组长度]={初值表},初值表的数据是按顺序依次给数组元素赋初值的; - 定义静态数组,如果没有对该静态数组赋初值,系统会自动赋为0;
- 数组初始化时,如果对全部元素都赋了值,就可以省略数组长度;
- 初始化也可以只针对部分数组,但是这里长度不可省!否则系统会自动认为该数组长度为初值表中的数据个数;
- 一般形式:
2.二维数组
- 1.定义和引用
- 一般形式:
类型名 数组名 [行长度][列长度]; - 行下标的合理取值范围为[0,行下标-1],列下标的合理取值范围是[0,列下标-1];
- 一般形式:
- 2.二维数组的初始化
- 分行赋值一般形式:
类型名 数组名[行长度][列长度]={{初值表0},···,{初值表k},···}; //把初值表k中的元素依次赋给第k行的元素; - 顺序赋值一般形式:```类型名 数组名 行长度][列长度]={初值表};//按数组元素在内存中的存放顺序,把初值表中的数据依次赋给元素;
- 如果对全部元素赋了初值,或分行赋值时,列出了全部行,就可以省略行长度,但是列长度是不可以省略的!
- 分行赋值一般形式:
3.一维字符数组和字符串
- 1.字符串
- 定义:字符串是由有效字符和一个结束标志'�'组成。
- "a"和'a'是不一样的!,前者是字符串常量,包括'a'和'�'两个字符,后者是字符常量,只有一个字符;
- 由于字符串结束符'�'代表空操作,无法输入,所以,输入字符串时,需要事先设定一个输入结束符,一旦输入它,就表示字符串输入结束,并把输入的结束字符转换为字符串结束符'�'.
- 2.初始化
- 设置静态字符数组,如果没有对该字符数组赋初值,系统自动赋为'�'
- 字符数组的初始化还可以用字符串常量,例:```static char s[6]={"hello"},但要注意的是,字符串有一个结束标志'�',将字符串存入字符数组中,数组长度至少是字符串的有效长度+1;
- 3.字符串的输入和输出
- 输入
| 输入函数 | 形式 | 使用范围 |
|---|---|---|
| fgets 函数 | fgets(字符数组名/字符指针, 可读入的字符个数size, stdin) | 可以吸收换行符和空格,但是字符串长度不可超过size-1,因为最后一定会留一个储存位置来储存'�',如果 size 大于字符串的长度,则多余的部分系统会自动用 '�' 填充。 |
| gets函数 | gets(数组名) | 遇到换行符结束,并自动把换行符改成'�'加在末尾。gets() 有一个非常大的缺陷,即它不检查预留存储区是否能够容纳实际输入的数据,换句话说,如果输入的字符数目大于数组的长度,gets 无法检测到这个问题,就会发生内存越界 |
| scanf函数 | scanf("%s",字符数组名) | 遇到换行符和空格就结束,末尾自动加上'�',不吸收换行符合空 |
- 输出
| 输出函数 | 形式 | 使用范围 |
|---|---|---|
| printf函数 | printf("%s",字符数组名) | 遇到'�'就输出结束 |
| puts函数 | puts(数组名) | 遇到'�'就输出结束,但是和printf不一样的一点是,puts输出结束后,会自动换行 |
4.数组中如何查找数据**
- 1.遍历法
这是最简单的方法,从数组中的第一个数一直检索到数组的最后一个数,如果找到用户想要的那个数据就提前退出。
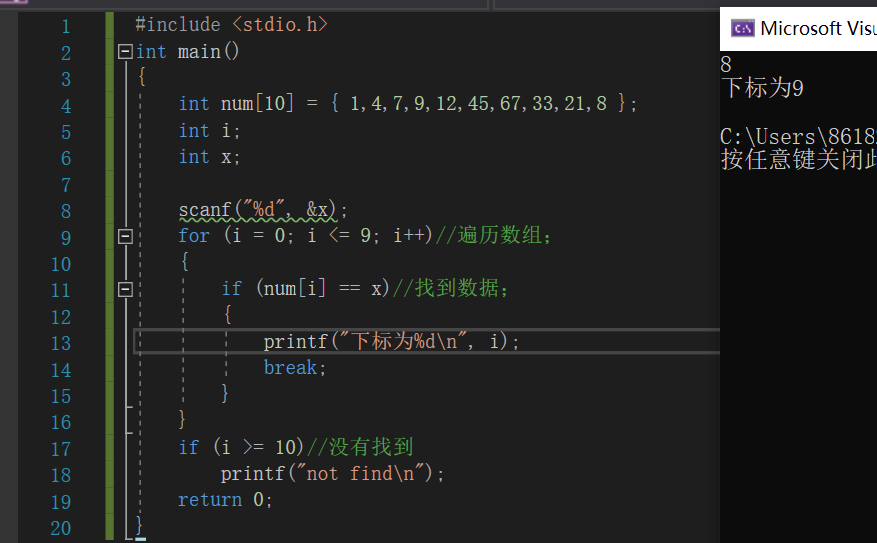
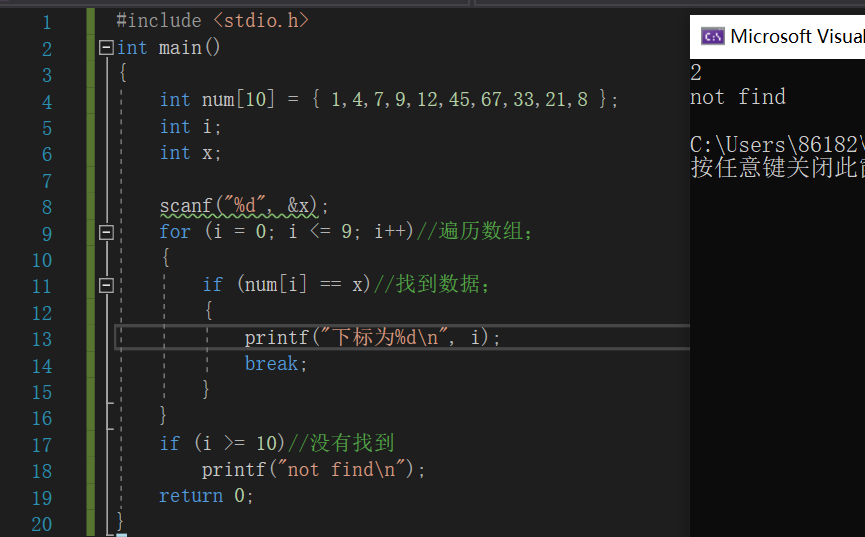
/*在数组num[]中,找到用户输入的那个数据,如果找到请输出该数据在数组中的下标,如果没有找到,就输出"not find"*/
int num[10]={1,4,7,9,12,45,67,33,21,8}; //数组num;
int x;//用户想要找的数据;
输入用户想要找的数据x
for i=0 to 9
if x的值和num[i]的值相等
输出该数字在数组中的下标i的值
break
end if
end for
if i>=10 //说明已经检索到超出数组的范围,没有找到用户需要的数字;
输出"not find"
end if
运行结果:
这种方法的好处是,思路简单,容易操作,但是,如果数组长度较大时,使用这种方法对计算机来说,计算量较大,效率很低,很容易出现运行超时的现象!所以我们还需要利用题目的某些关键条件来优化它,减少计算机的计算量。
- 2.二分查找法(只适用于数组中的元素本就有序的情况)
设n个元素的数组a已经有序,用low和high两个变量来表示查找的区间,即在a[low]~a[high]中去查找用户输入的值x,和区间中间位置的元素a[mid] (mid=(low+high)/2)作比较,如果相等则找到,算法结束;如果是大于则修改区间(数组为升序数列:low=mid+1;数组为降序数列:high=mid-1);如果是小于也修改区间(数组为升序的改为:high=mid-1,;数组为降序数列:low=mid+1);一直到x=a[mid] (找到该值在数组中的位置)或者是low>high(在数组中找不到x的值)时算法终止;

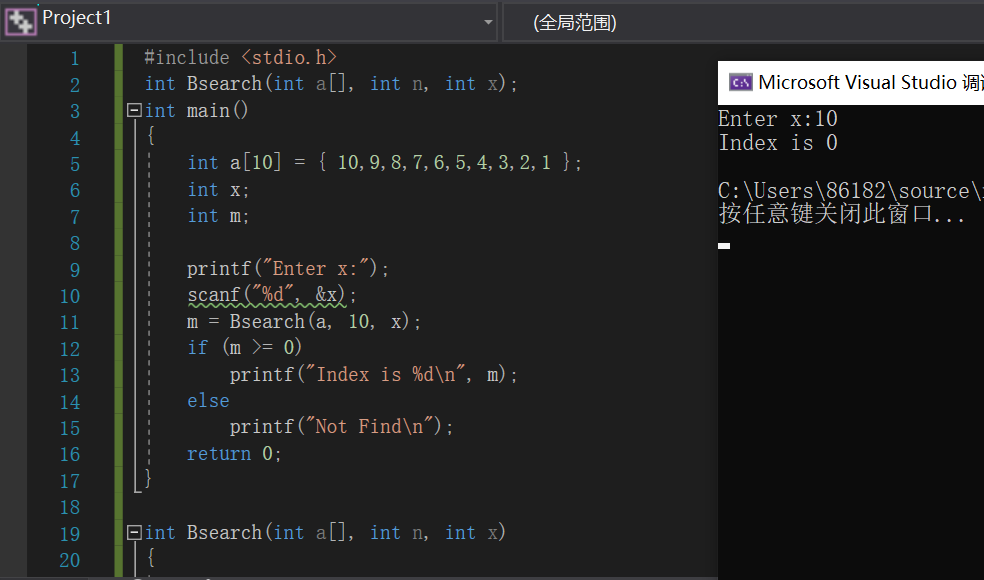
/*在有序数组num中,寻找用户输入的值x*/
自定义二分查找函数int Bsearch(int a[],int n,int x)
主函数main中
int a[10]={10,9,8,7,6,5,4,3,2,1};//有序数组;
int x ;//用户输入的数;
int m ;找到的数所在的下标;
输入用户想要寻找的数;
进入函数Bsearch寻找x的值,把返回的值赋给m
if m大于等于0
说明找到x的位置,输出该值在数组中的下标;
else
说明没有找到x的位置,即,该数组中没有x,输出“not find”;
end if
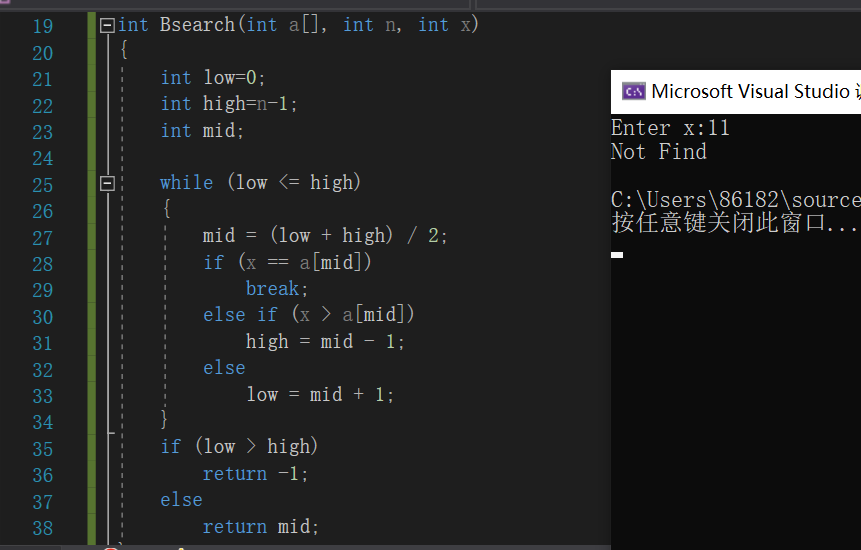
自定义函数Bsearch
int low = 0//查找范围的最小下标,先从数组第一位开始;
int high = n-1//查找范围的最大下标,先从数组的最后一位开始;
int mid; //查找范围的中间位置;
while(low<=high)
mid = (low+high)/2;
if x==a[mid]
说明找到x的位置,break跳出循环;
else if x小于a[mid]
改变查找范围:low=mid+1;
else x大于a[mid]
改变查找范围:high=mid-1;
end if
end while
if low<=high //表示找到x的位置;
返回mid的值;
else //表示没有找到x的位置
返回-1;
end if
运行结果:
使用二分查找法可以大大缩短计算机运行的时间,但唯一不足的就是其只局限于在有序数列中查找数据。
5.数组中如何插入数据
先在数组中找到需要插入的位置,将处于该位置及后面的数据全部都往后移一位,然后把该数据插入。例将一个给定的整数插到原本有序的整数序列中,使结果序列仍然有序(具体题目参加pta题集:插入排序)。大概做法如下:
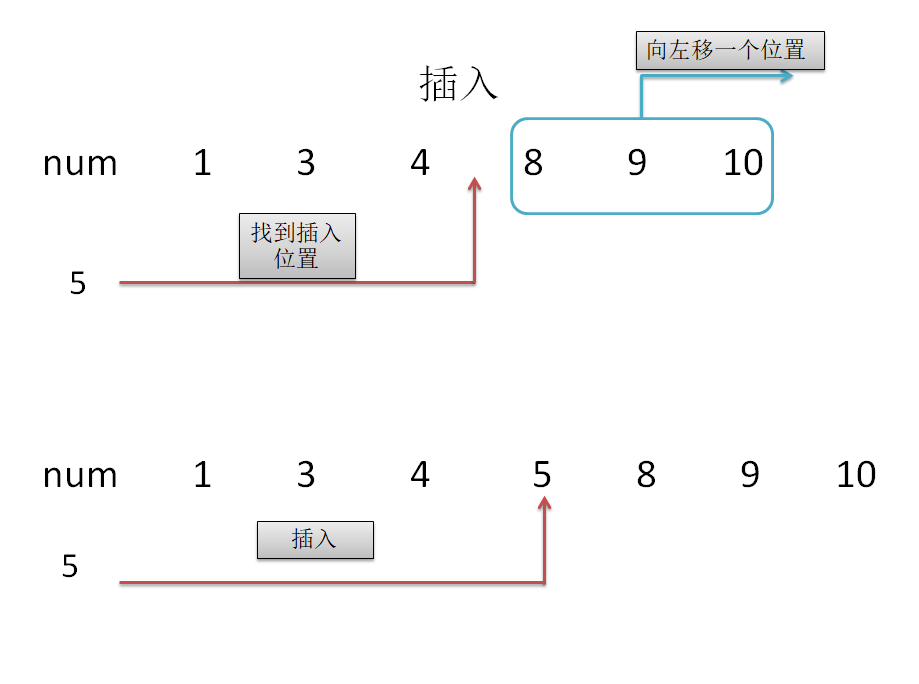
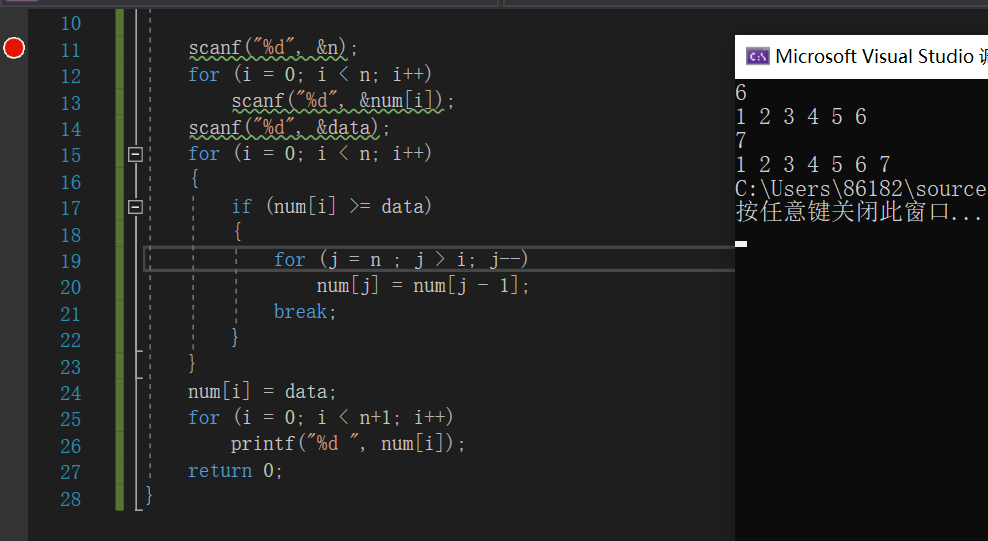
#define N 1000//保证数组长度足够大;
int num[N] ;//有序数组;
int n;//用户想要输入数据的个数;
int data;//插入的数据
输入数据个数n;
for i=1 to n
输入数据,赋给num[i];
end for
输入插入的数据data;
for i=0 to n
if data<=num[i]
for j=n to i //将后面的数据全都往后移一位;
num[j]=num[j-1]
end for
break;//退出循环;
end if
end for
插入数据data,num[i]=data;
输出数组
运行结果:

6.数组中如何删除数据
- 1.建立新函数
顾名思义,就是建立一个新的函数,把删除后的数据按顺序保存到新函数中去。
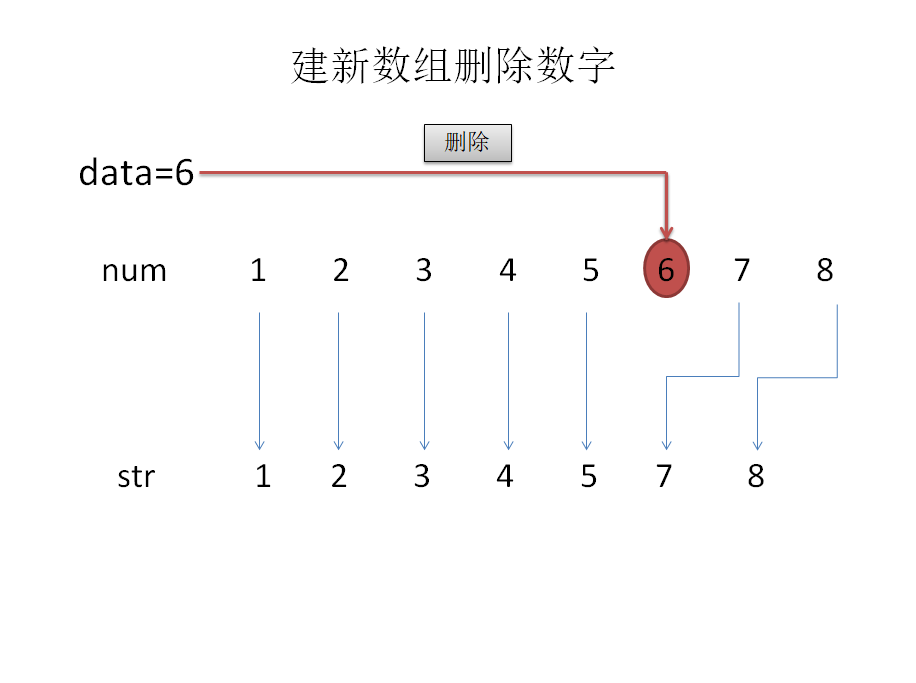
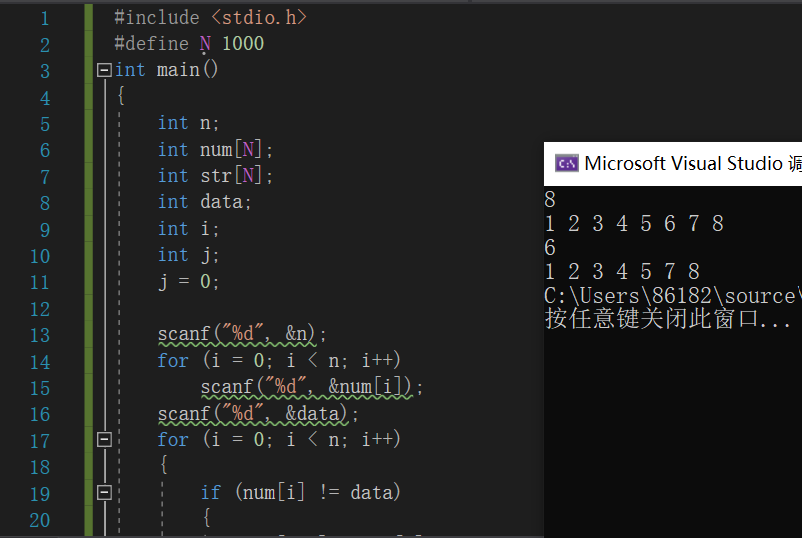
#define N 1000//保证输入的数据不超过1000个;
int num[N];//用户输入的数据;
int n;//用户想要输入的数据个数;
int str;//保存删除后的数组;
int data;//用户想要删除的数据;
输入数据个数n
for i=0 to n
输入数据,赋给num[i]
end for
输入想要删除的数据
for i=0 to n
if num[i]!=data
str[j++]=num[i]
end if
end for
if j!=i
说明找到删除数据,输出删除数据后的数组str[]
else
说明没有找到删除数据。
end if
运行结果:
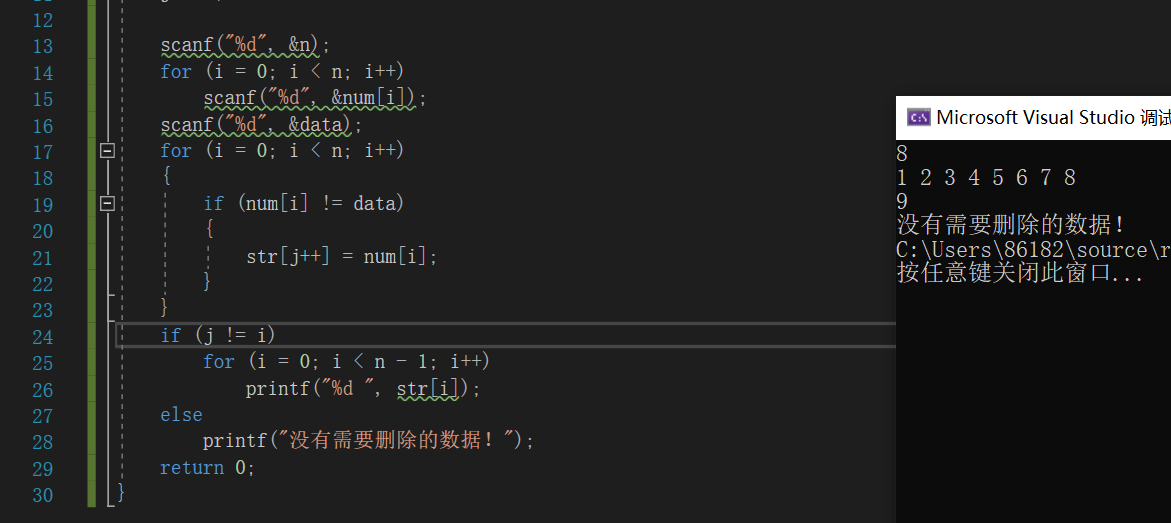
这样的好处是可以保存原来的数组,而且思路简单,容易想到。
- 2.重构数组
这种方法是把原来的数组重构,即直接在原数组上做改动。基本步骤就是

/*删除字符*/
#define N 1000//保证输入的数据不超过1000个;
char str[N];//用户输入的数据;
char letter;//用户想要删除的字母;
输入字符串str[]
输入想要删除的字母letter;
for i=0 to str[i]!='�'||str[i]!='
'
if str[i]!= letter
str[j++]=str[i]
end if
end for
给str数组最后加上结束标志'�'
输入字符串str
运行结果:
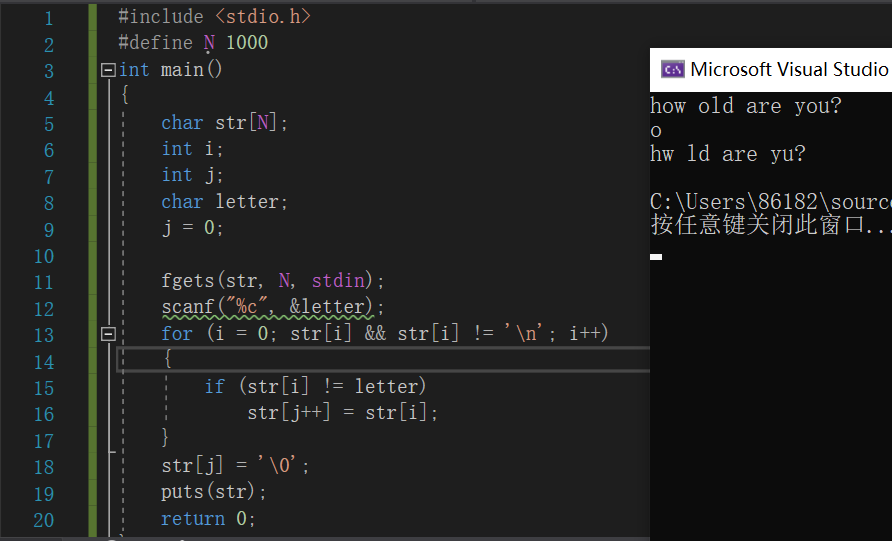
重构数组方法在处理大数据时可以减少占用计算机过多的储存空间,但其缺点就是无法保存原来的数据。
7.排序方法
- 选择排序法
第一趟先选择数组中的第一个数,和后面的数做比较,找到最大/最小的那个数,和第一位数交换,;第二趟然后取第二个数,和第二位后面数作比较,找到除第一个数外的最大/最小的数,和第二位交换位置,第三趟取第三位数···直到第n趟,只剩一个数,排序结束;
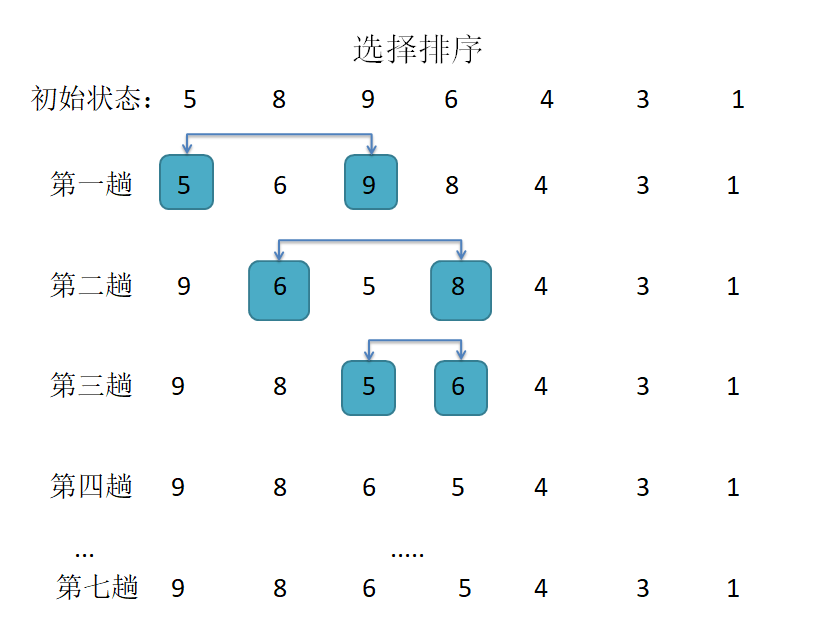
/*从大到小排列*/
for i=0 to n //外循环
index=i;//index用于保存最最大的数据的下标;
for j=i to n //内循环
if num[index]<num[j] //寻找从第i个数据开始往后的最大数据;
index=j;
end if
end for
交换num[index]和num[i]的数据;
end for
运算结果:

{{uploading-image-358528.png(uploading...)}}
思路简单,运用的范围较广;
- 冒泡排序法
这种方法从第一个数开始重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序错误就把他们交换过来。一直重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。

/*数列从大到小排序*/
for i=1 to n //外循环
for j=0 to n-i //内循环
if num[j]<num[j+1]; //交换相邻的两个数;
temp=num[j];
num[j]=num[j+1];
num[j+1]=temp;
end if
end for
end for
运行结果:

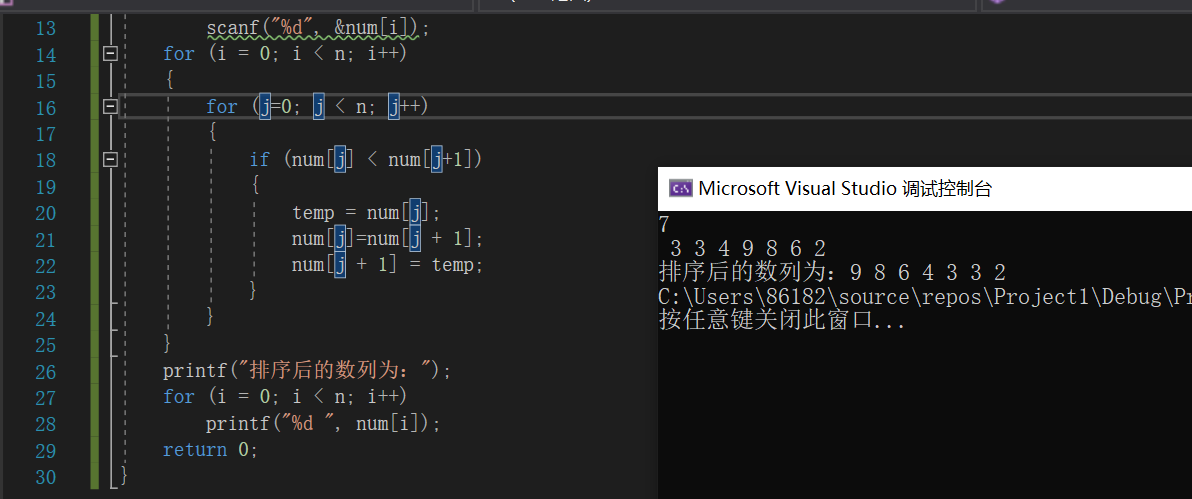
8.数组做枚举用法
- 1.寻找重复数据
有时候我们需要在某个数组a[]中找到重复的某个数据,或者出现次数最多的某个数,这个时候我们可以用下标法,数组的下标做枚举用法,列举出所有可能出现的数字,借助辅助数组hash[]来查找数据,用数列a[]的每个元素作为数组hash[]的下标,以hash[a[i]]的值来查找所需的数据a[i]。

/*查找数组中重复的数据*/
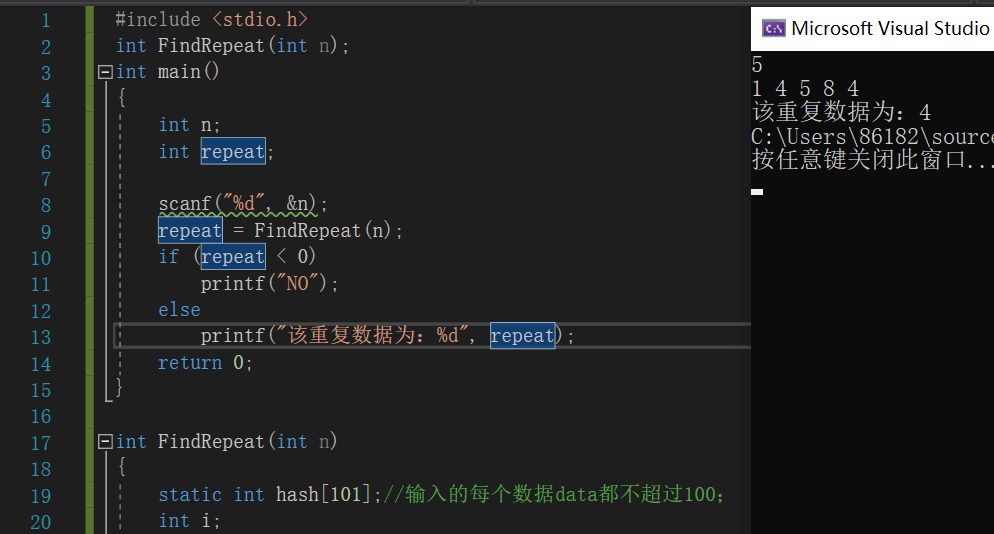
定义查找重复数据的函数FindRepeat(int n)
主函数中
int n;//定义变量n保存数据个数;
输入n的值
if FindRepeat(n)的值小于0
说明没有找到重复的数据,输出"NO";
else
说明找到重复的数据,输出该数据;
end if
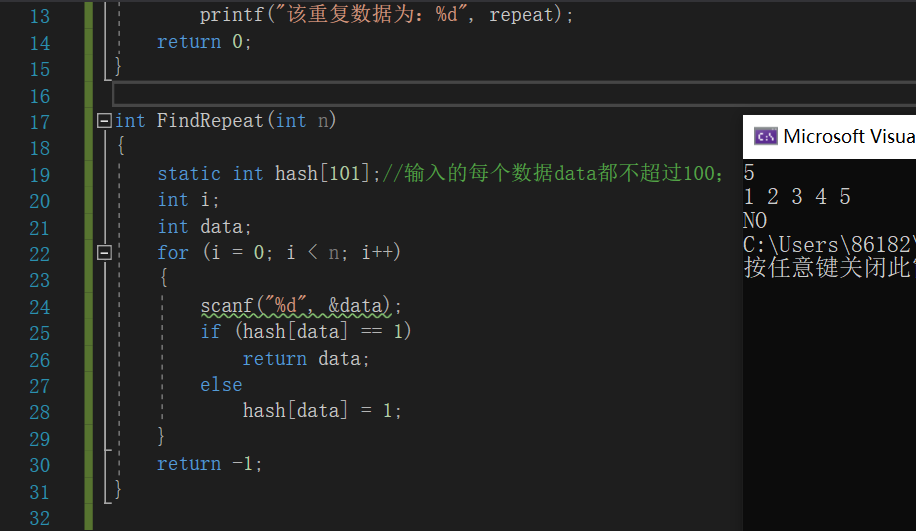
FindRepeat函数中
初始化hash数组为0;//这里一般定义静态数组,来给hash[]中每个元素初始化为0;这里要注意hash的长度,如果data的值为0-n,那么数组hash的长度范围为n+1;
for i=1 to n //n为用户要输入的数的个数;
用户输入一个数data
end for
if hash[data]==1
有重复数据
return data
else
数据data暂时还不是重复数据,hash[data]=1;
end if
end for
没有重复数据
return -1
运行结果:
在这里合理的设置静态辅助数组————hash(哈希)组,可以简化我们的代码,提高运行效率,这种方法在大数据处理中非常好用!但是它也有个局限性,就是只适用于正整数,不适用于负数和小数
- 2.阅览室
1.2 本章学习体会
- 数组让我们进一步的了解到c语言的
可怕魅力,在字符数组这方面,对如何运用合适的输入语句来读取字符串,我还不太熟练,这体现在我的pta题集中,经常出现最长字符串的测试点错误!这点需要注意。学习了数组意味着,我们要学习了更多的题型,如果没有及时复习方法的话,很容易就忘记,应该课后多总结总结,配合老师给的视频和pta题集,多复习巩固。 - 这两周的代码量为:1494
2.PTA实验作业
2.1求矩阵中的最大小值
2.1.1 数据处理
#define N 10
定义数组FindMaxMin(int num[][N],int n,int m)
在主函数main中
定义整型的二维数组num[N][N]
定义变量矩阵的行数n;
定义变量矩阵的列数m;
while(scanf("%d %d",&n,&m)==2) //表示读入两个有效的数字,配合while循环可以重复测试数据;
for i=0 to n
for j=0 to m
输入矩阵
end for
end for
进入FindMaxMin函数寻找最大值和最小值;
end while
在FindMaxMin函数中
定义变量max;
定义变量min;
定义变量最大值max所在的行标maxRow;
定义变量最大值max所在的列表maxCol;
定义变量最小值min所在的行标minRow;
定义变量最小值min所在的列表minCol;
给max和min赋初值为矩阵的第一个数num[0][0];
最大最小值的行标列标都为0;
for i=0 to n
for j=0 to m
if 最大值max小于num[i][j]
max=num[i][j]
maxRow=i;
maxCol=j;
end if
if 最小值大于num[i][j]
min=num[i][j];
minRow=i;
minCol=j;
end if
end for
end for
输出最大值和最小值以及他们所在的位置;
2.1.2 代码截图



2.1.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 3 5 57 30 66 41 98 11 93 54 62 31 49 87 71 70 37 | max=98 row=0 col=4 min=11 row=1 col=0 | 题目给的样例 |
| 10 10 1 ~100 | max=100 row=9 col=9 min=1 row=0 col=0 | 矩阵数据最多 |
| 4 3 1 2 5 6 1 5 8 9 9 5 8 3 | max=9 row=2 col=1 min=1 row=0 col=0 | 有两个最大的数,输出行最小的那个行标和列标 |
| 1 1 9 | max=0 row=0 col=0 min=0 row=0 col=0 | 只有一个数据 |
2.1.4 PTA提交列表及说明
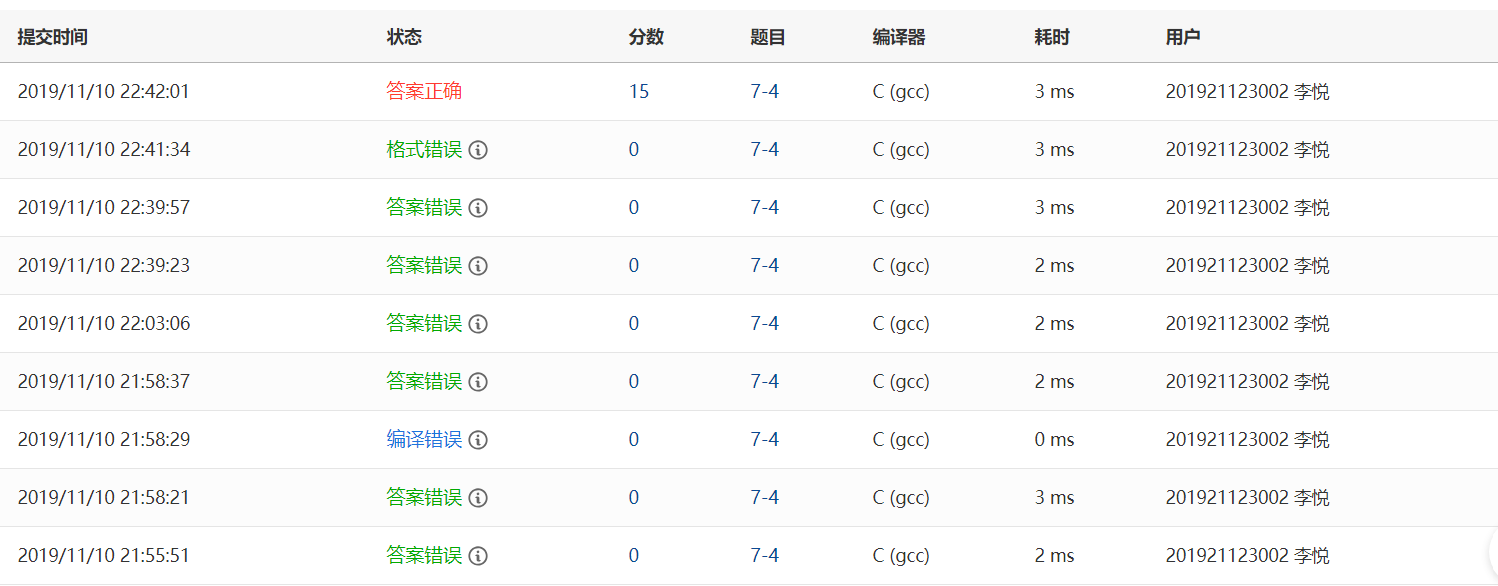
答案错误:错误原因是不可以重复测试数据;
编译错误:我以为是测试点两个最大最小输出前面那个的行标和列标错误,于是在判断大小的前面加上了等号,然后我把等号删掉了;
答案错误:都是无法重复测试数据的原因;
格式错误:在输出最小值及其行标列标的语句中没有加上换行符;
2.2 阅览室
2.2.1 数据处理
#define Max 2000 //1000本书借和还两个操作
定义函数FrequencyTime(int record[Max][3],int end)
在主函数main中
定义二维数组record[Max][3]
定义变量book来保存书号
定义变量hour来保存小时数
定义变量minute来保存分钟数
定义变量days来保存天数
定义变量state来保存书的状态
定义变量k来表示数组的行标,k的值表示一天记录了多少次书的借入和借出;
输入天数
for i=0 to days
k=0
while(1)
输入书号,书的状态,小时数,分钟数;
if book==0//说明一天结束,要计算其平均阅读时间和借书次数
进入FrequencyTime函数
break;
end if
record[k][0]=book;
record[k][1]=state;
record[k][2]=hour*60+minute;//把时间和分钟合成一个数据存放起来,方便计算
k++
end while
end for
在FrequencyTime函数中
定义变量times保存总的借书时间,并初始化为0
定义变量count保存借书次数,并初始化为0
for i=0 to k
if 这本书是借的状态
for j=i+1 to k
if 同一本书,还没有换就又借出去,说明该记录无效
break退出循环
end if
if 同一本书,还回来了
总时间再加上借出的时间;并且借出次数加上1
break;
end if
end for
end if
end for
if count为0
输出"0 0",表示一天都没有借书
else
输出次数和平均每次借书时间
2.2.2 代码截图
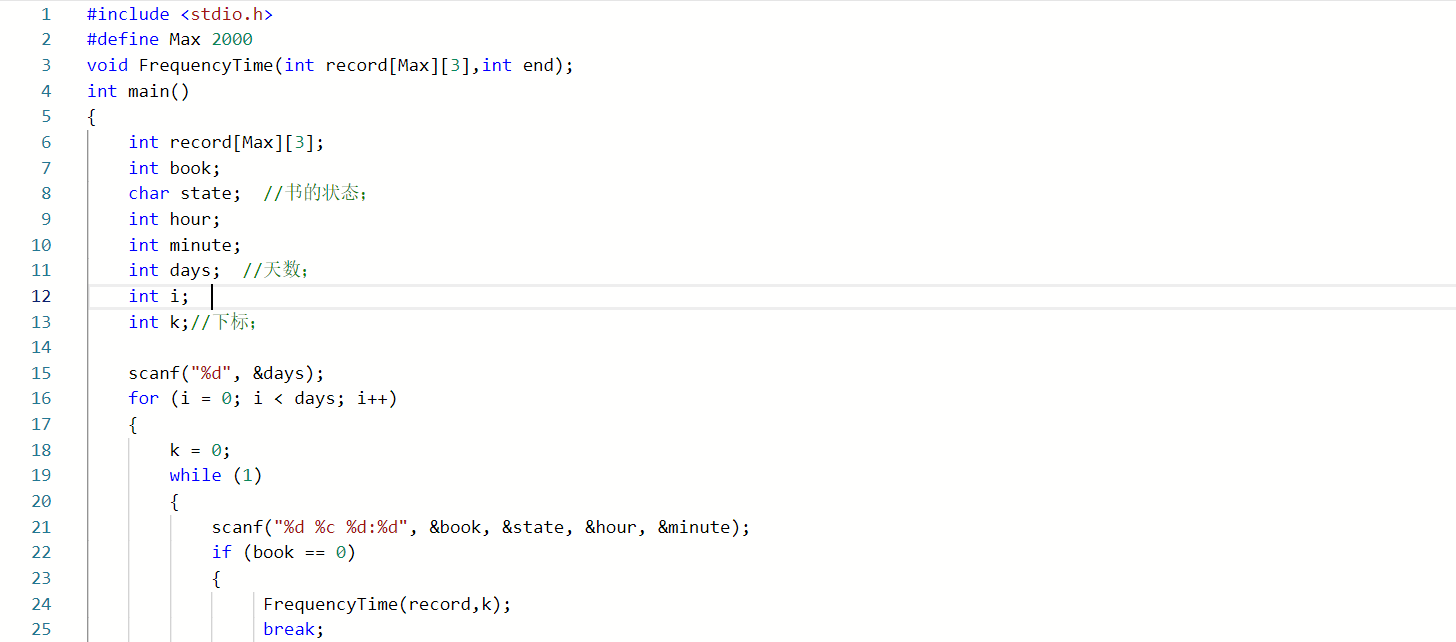
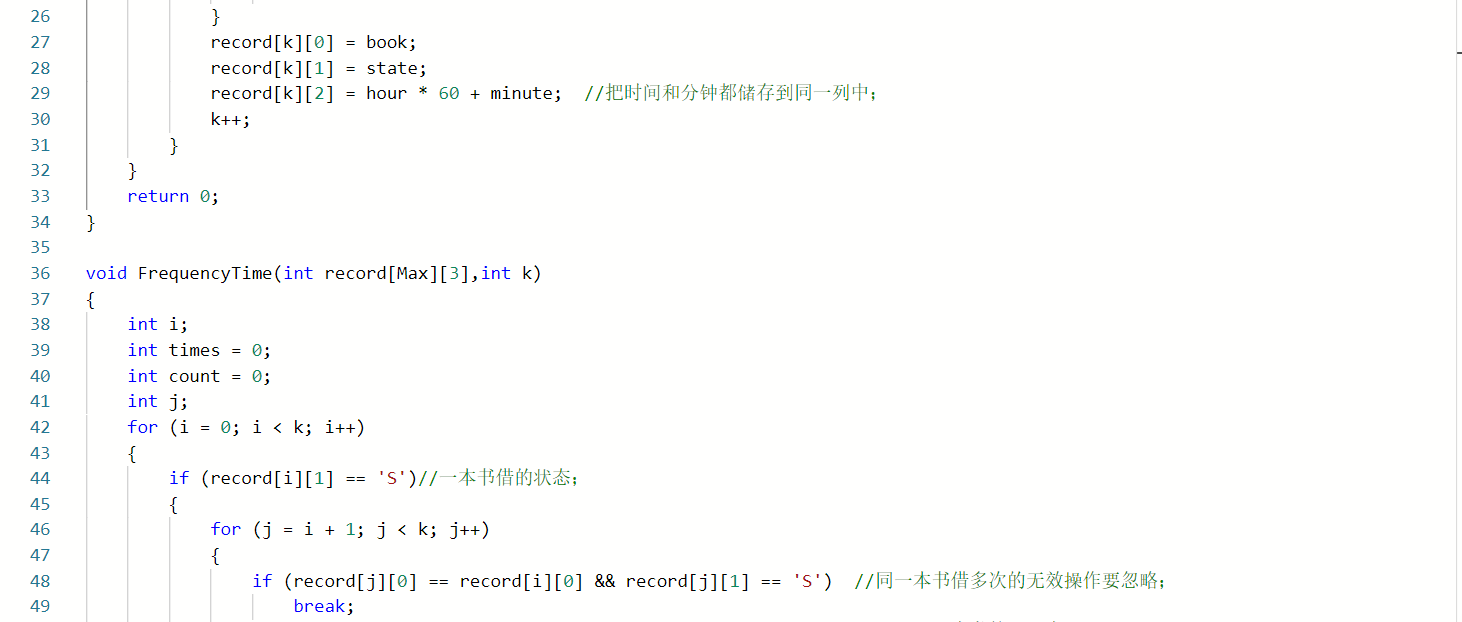

2.2.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 3 1 S 08:10 2 S 08:35 1 E 10:00 2 E 13:16 0 S 17:00 0 S 17:00 3 E 08:10 1 S 08:20 2 S 09:00 1 E 09:20 0 E 17:00 | 2 196 0 0 1 60 | sample等价,结果有舍入,有不匹配,有直接结束 |
| 1 1 S 09:10 1 S 10:10 1 E 13:07 1 E 15:48 0 S 17:00 | 1 177 | 同一本书被借多次,有不匹配 |
| 1 1000 S 00:00 1000 E 24:00 0 S 24:00 | 1 1440 | 书号、时间取到边界值 |
| 1 1000 E 09:56 1000 E 10:11 1000 S 10:30 1000 S 11:56 1000 E 14:37 1000 E 16:27 | 1 161 | 最大数据,有连续S和连续E,有S和E全反 |
2.2.4 PTA提交列表及说明
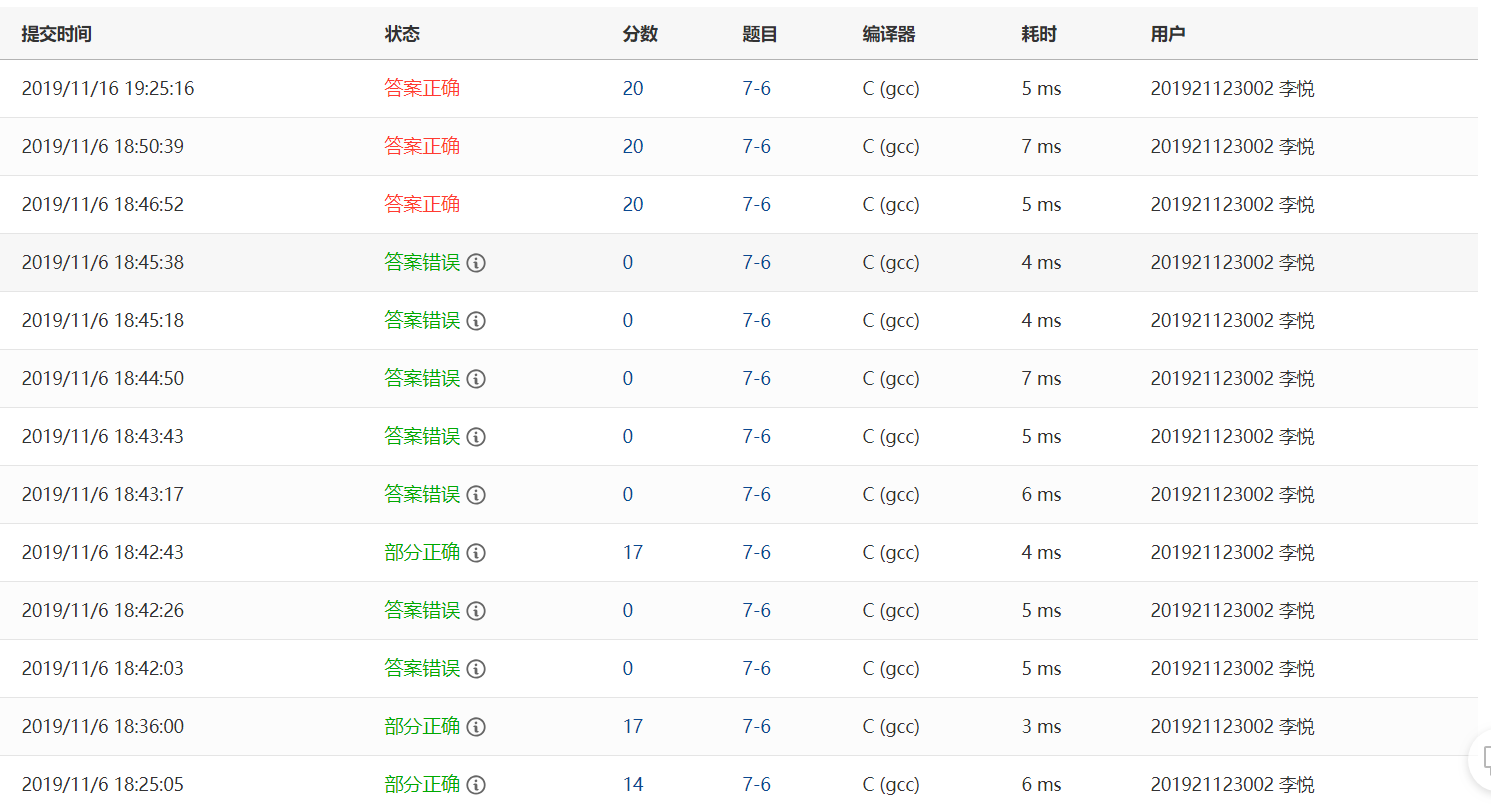
部分正确:只考虑到如果书号相同,两次书的状态不同就可以算记录有效,没有考虑到有重复的S和E,还有同书号E在S前的无效记录;
部分正确:忽略了S和E匹配的问题,以及如果有同书号重复S的问题;
答案错误:for循环如果没有加大括号的话,后面只能跟一个语句,我没有意识到这一点,导致计算次数和平均时间的语句不在for循环内,因而数据无法满足条件,进入if语句进行计算;
部分正确:还是忽略了S重复且和E的不匹配问题;
答案错误:我以为我前面的答案错误的代码是接近答案的然后复制了之前的代码,按照部分正确中的错误进行修正,其实就是计算借书次数和平均时间不在循环体内....
2.3 A-B
2.3.1 数据处理
#define M 10002
定义函数DeleteLetter来完成A-B
在主函数main中
定义字符数组a[M]
定义字符数组b[M]
输入字符串a
输入字符串b
进入函数DeleteLetter
在函数DeleteLetter中
for i=0 to a[i]!='
'
for j=0 to b[j]!='
'
if a[i]==b[j]
说明是需要删除的字符,退出循环
end if
if b[j]=='
'
说明不是需要删除的字符,输出该字符
end if
end for
end for
2.3.2 代码截图
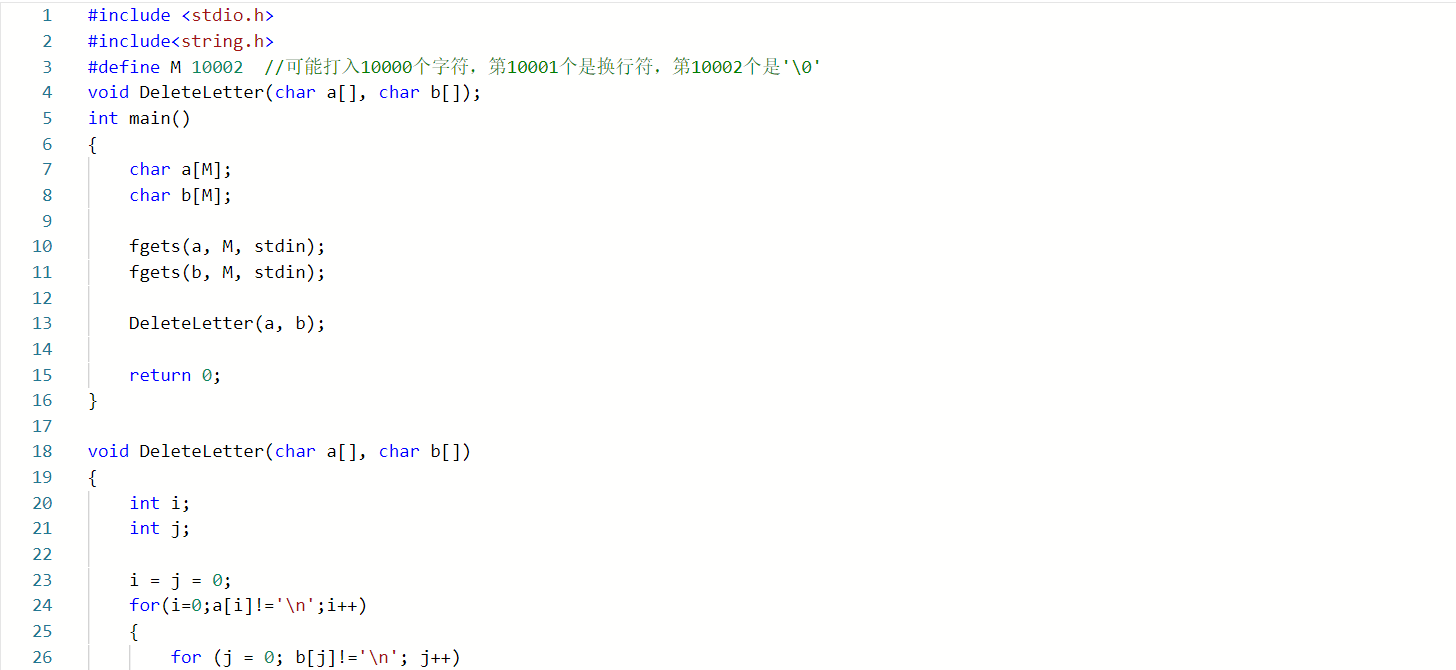

- 在听了老师的建议后,这里补充一个比较简便的做法:
2.3.1 数据处理
定义辅助数组hash[256];
定义字符ch;
定义字符串str[10002];
输入字符串a赋给str
while((ch=getchar())!='
')//输入字符串b中的每个字符;
hash[ch]=1;//整型和字符型本就可以相互转换,这里把ch对应的ASCII的值作为hash的下标,表示需要删除的字符;
end while
while (str[i]!='
') //str[i]是以'
'为结束标志;
if (hash[str[i]]==0) //说明是可以输出的字符
输出字符str[i];
end if
i++;
end while
2.3.2 代码截图

- 这种方法的代码量比我之前的少太多了,而且计算机运行的时间也比之前的要快,效率提高了许多!!
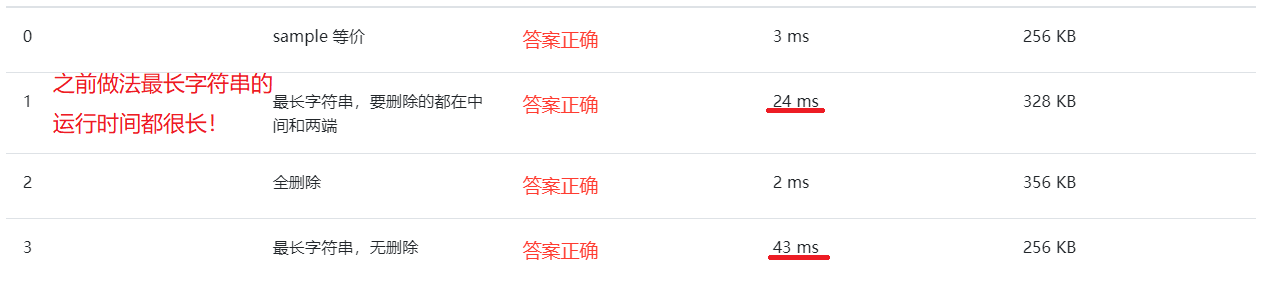

2.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| I love GPLT! It's a fun game! aeiou | I lv GPLT! It's fn gm! | sample 等价 |
| ab ···· bb····ab(总共9996个a,4个b) | a···a(9996个a) | 最长字符串,要删除的都在中间和两端 |
| how old are you how old are you | 全删除 | |
| a···a(10000个) b | a···a(10000个) | 最长字符无删除 |
2.3.4 PTA提交列表及说明
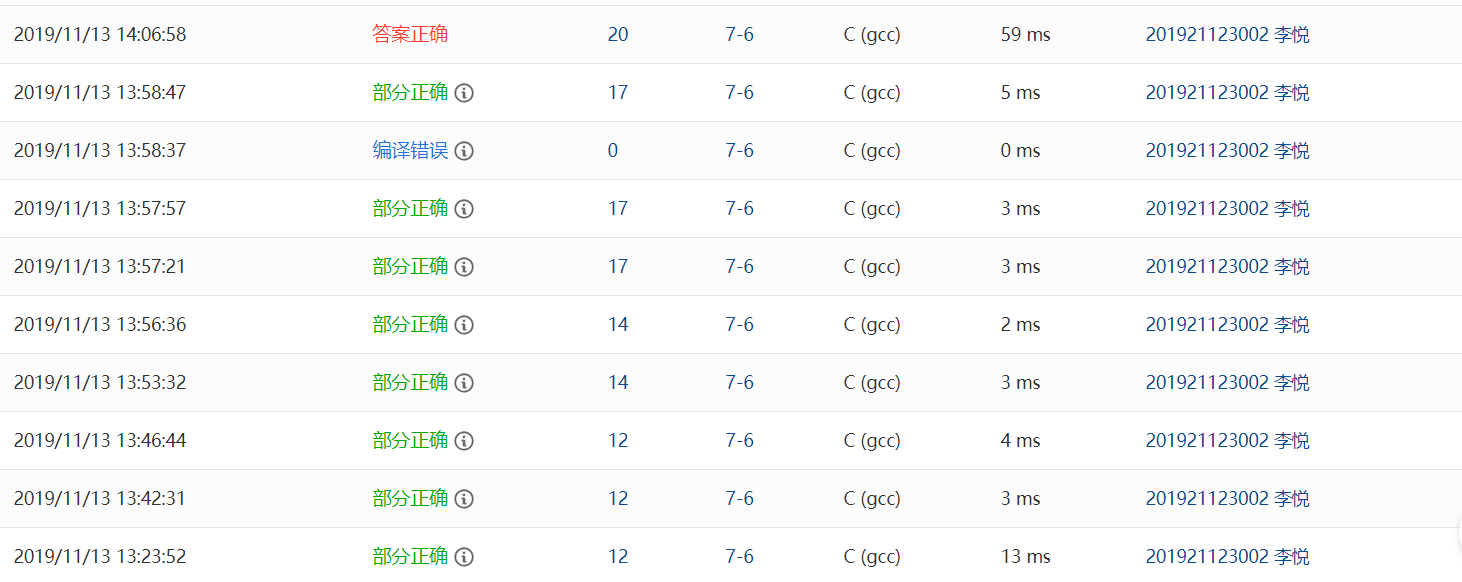
部分正确:字符数组的范围没有考虑好,导致最长字符串的最后一个字符被吞,所以关于长字符串的测试点都错了;还有全删除,如果全删除的话,会输出换行符;
部分正确:在对字符串b的遍历中,for语句的括号中多了不小心被打上去的“j<”,删去;
部分正确:即使把字符串最大的长度修改到10001,也是不行的,因为可能输入了10000个字符,用fgets读取时,第10001个字符自动被赋为'�'导致错误;所以字符长度最大值应该是10002;
编译错误:没有定义变量flag就使用它,定义一下flag;
部分错误:还是字符串的长度没有设置好,最大长度应该是10002。
3.阅读代码





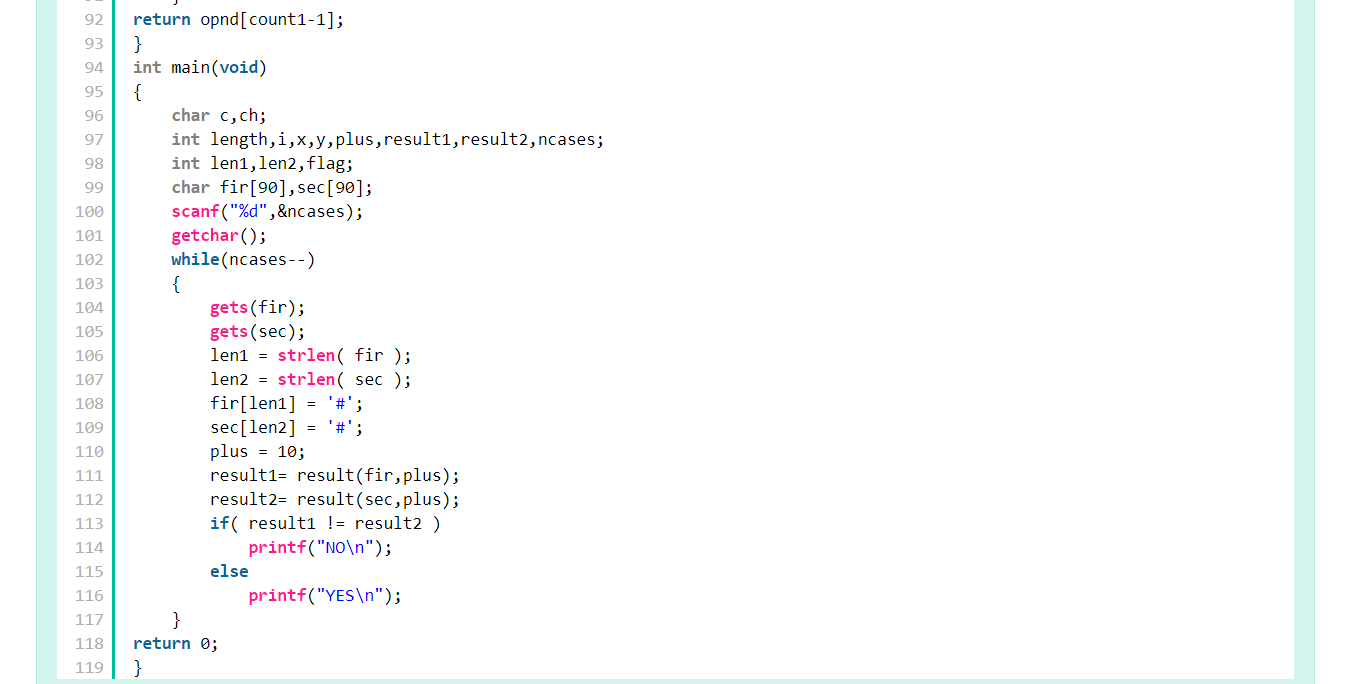
代码功能
输入测试样例数和表达式,判断两个表达式的是否等价,如果等价就输出YES,如果不是则输出NO;
代码的优点
- 1.合理定义全局变量,解决了函数只能返回一个变量的缺点,有利于数据之间的传递;
- 2.分装函数合理清晰,每个函数都有自己的功能,易于修改调试,且函数间的关联性强;
- 3.合理设置二维数组h[][]配合record函数来判断计算机应该要做哪种运算,而不是运用过多的if语句,这样不仅可以减少代码量,配合switch语句还提高了计算机的运行效率,并且,这里也解决了算术表达式中的优先级的问题;
- 4.逻辑思维能力强,代码的构思很巧妙,环环相扣,大佬求抱大腿!!