Mtcnn它是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型主要采用了三个级联的网络,采用候选框加分类器的思想,进行快速高效的人脸检测。这三个级联的网络分别是快速生成候选窗口的P-Net、进行高精度候选窗口过滤选择的R-Net和生成最终边界框与人脸关键点的O-Net。和很多处理图像问题的卷积神经网络模型,该模型也用到了图像金字塔、边框回归、非最大值抑制等技术。
01什么是Mtcnn
MTCNN是一个人脸检测算法,英文全称是Multi-task convolutional neural network,中文全称是多任务卷积神经网络,该神经网络将人脸区域检测与人脸关键点检测放在了一起。该算法的网络结构总体可分为P-Net、R-Net、和O-Net三层网络结构。
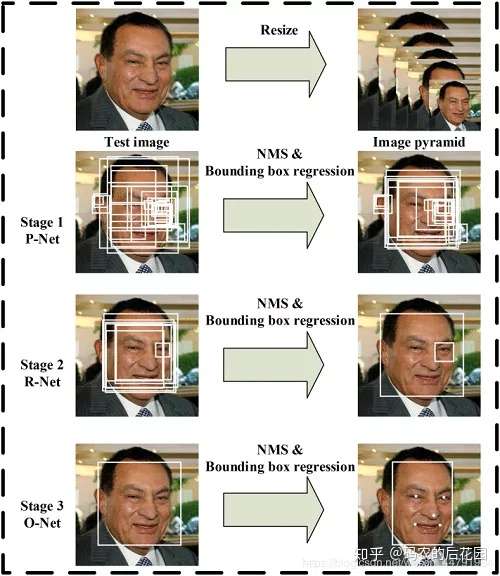
Mtcnn算法结构图
总结:Mtcnn分为四步,分别是图像金字塔先把输入图片进行缩放,缩放完成之后,我们可以提取出大的人脸和小的人脸,使得网络提取的效果更有效。
然后Pnet网络会对图像金字塔得到的图像进行一个粗略的筛选,得到一大堆的人脸粗略框,然后对这些粗略框进行一个非极大值抑制筛选操作得到相对于好一点的框。再把这些相对好一点的粗略框传入到Rnet精修网络中,Rnet会对这些粗略框的内部区域进行物体识别,判断是否是一张人脸,同时对框的长和宽进行修正,然后对调整好的粗略框进行非极大抑制操作筛选出相对上一步更好的框框。
最后这些经过Rnet调整好的相对较好的框框传入到Onet网络中,Onet依旧判断这些框的内部区域是否有人脸,同时对Rnet得到的这些框的长和宽再一次进行精修,使得这个框更好的符合人脸大小,最终再进行非极大值抑制操作,得到最终的人脸预测框,与此同时还会得到人脸的5个特征点的位置。
02mtcnn人脸检测算法实现思路
对于我们而言,输入这样一张人脸图片,我们可以轻易地知道图片中哪里是人脸,哪里不是人脸,下图红色方框的位置就是人脸的部分。
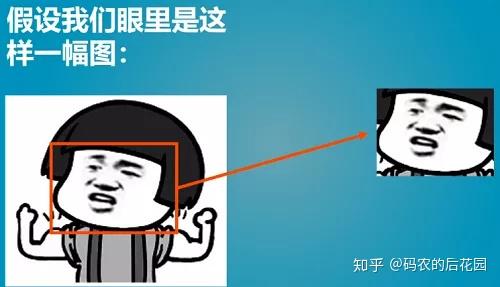
但是计算机时如何识别的呢?mtcnn为计算机提供了一种非常有效的思路:
- 第一步: 首先mtcnn对我们输入的一张图片进行不同尺度的缩放,生成图像金字塔,是为了检测不同大小的人脸。
- 第二步:然后将我们活得的图像金字塔传入Pnet,Pnet会生成一堆相对于原图的人脸候选框,我们利用这些人脸候选框在原图片中截取出一块又一块地区域,把截取出来的图片传入到Rnet中。
- 第三步:当Rnet接受到这些分散的图片之后,会对截取出的图片中是否真正有人脸进行判断和评分,同时对原有的人脸后选框区域进行修正,通过Rnet我们将获得一些相对正确的人脸候选框。但是还要继续进行二次修正。
- 第四步:我们利用Rnet修正后的人脸候选框再次从原图片中截取一块又一块的区域,把截出来的区域图片传入到Onet中,Onet是mtcnn中最精细的网络,它会再次对截取图片内中是否真正存在人脸进行判断和评分,同时把人脸候选框进行修正,Onet输出结果就是我们需要的人脸位置了。
 Mtcnn实现流程图
Mtcnn实现流程图
03Mtcnn具体实现流程
1.构建图像金字塔
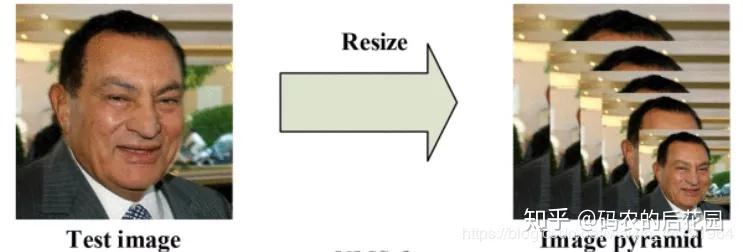
当我们输入一张图片X到mtcnn网络模型进行预测时,首先会对我们的图片进行不同尺度的缩放,构建我们的图像金字塔。
如:上图中的左图。构建过程中图片的不同缩放尺度是由缩放系数factor决定的,通过不同的缩放系数factor对图片进行缩放,每次缩小为原来图片缩放的factor大小。其实就是对我们的原图进行多次缩放,每次缩放的比例是一个确定的数factor=0.709,第一次缩放为原图X尺寸的0.709倍得到0.709X尺寸的图片,第二次对已经缩放的图片再次进行缩放0.709*0.709X尺寸的图片,依次类推,我们将会得到非常多原图的不同尺寸的图片。
这样的缩放的目的是为了能够检测图片中不同大小的人脸,因为我们拍摄一张图片,里面的人脸会有大有小,这样的一个图像金字塔缩放操作,就是为了让我们获得不同大小的人脸的特征。通过这样的一个图像金字塔的构建,我们会获得非常多的图片,缩放截止的点是:当缩放的最后的一张的图片的长或者宽小于12时就停止缩放。构建完图像金子塔之后,我们就带着这一大堆的图片到Pnet网络中。
实现代码:
如下,当一个图片输入的时候,会缩放为不同大小的图片,但是缩小后的长宽最小不可以小于12

2.Pnet
Pnet的全称为Proposal Network, 作用是给出一些框的一个建议位置。它的基本构造是一个全连接网络FNC,对上一步构建完成的图像金字塔,通过一个全连接网络FCN进行初步特征提取和边框的标定。如下图:
 Pnet网络处理过程
Pnet网络处理过程
初步特征提取和边框标定
当我们将图像金字塔的图片输入到Pnet网络之后,会输出classifier和bbox_regress两个参数。
Pnet的两个输出:
- classifier: 用于判断该网格点上的框的可信度
- bbox_regress: 用于表示该网格点上框的位置
Pnet和yolov3有一定的相似,当我们的图片经过卷积神经网络的卷积之后,它的特征层的长和宽会进行一定的缩小,有可能会是原图的2分之一,4分之一,Pnet是将变为了原来的2分之一,也就是每隔两个像素点会有一个特征点(网格点),这个特征点就负责预测它的右下角这个区域的检测。
classifier就表示这个特征点负责的这个右下角区域有没有人脸,bbox_regression就代表这个右下角区域中有人脸的长和宽的框的位置。我们通过Pnet就获得了这样的一系列的框框,如上图的左图,得到的框框有很多是重叠的,我们就利用非极大抑制操作在每一个区域中挑选出分数最大的一个框,并将这个区域中和这个分数最大的框重合程度大的那些框框进行剔除,只保留这个区域中得分最高的那个框,从而筛选掉一些框框,保留下来一些稍微有精度的一些框,然后我们就带这些的精度的框就传入到Rnet网络中。
Pnet的网络比较简单,实现代码如下:

在完成初步特征提取后,还需要进行Bounding-Box Regression 调整窗口与非极大值抑制进行大部分窗口的过滤。Pnet有两个输出,classifier用于判断这个网格点上的框的可信度,bbox_regress表示框的位置。bbox_regress并不代表这个框在图片上的真实位置,如果需要将bbox_regress映射到真实图像上,还需要进行一次解码过程。
解码过程利用detect_face_12net函数实现,其实现步骤如下(需要配合代码理解):
- 1、判断哪些网格点的置信度较高,即该网格点内存在人脸。
- 2、记录该网格点的x,y轴。
- 3、利用函数计算bb1和bb2,分别代表图中框的左上角基点和右下角基点,二者之间差了11个像素,堆叠得到boundingbox 。
- 4、利用bbox_regress计算解码结果,解码公式为boundingbox = boundingbox + offset*12.0*scale,这个就是框对应在原图上的框的位置。
简单理解就是Pnet的输出就是将整个网格分割成若干个网格点,;然后每个网格点初始状态下是一个11x11的框,这个由第三步得到;之后bbox_regress代表 每个网格点确定的框 的 左上角基点和右下角基点 的偏移情况。
Pnet解码代码:

3.Rnet
Rnet全称为Refine Network, 维/精修神经网络。它的基本构造是一个卷积神经网络,相对于第一层的P-Net网络来说,它增加了一个全连接层,因此对输入的数据筛选会更加严格。当我们的图像金字塔的图片经过P-Net网络之后,会留下许多预测窗口,我们将所有的预测窗口代表的人脸区域从图片中截取出来传入到Rnet网络之中,Rnet会根据截取出来的人脸计算它们的分数以及它们长和宽需要调整的地方。Pnet会给出人脸候选区域的以左上角和右下角形式表示的框的位置,也就是预测窗口,我们就是根据Pnet预测的框的左上和右下角的位置从原图中截取出原图带有人脸的区域再送到Rnet中,Rnet会首先对这个截取出来的区域进行内容的可信度判断,即判断是否是一张人脸,同时会对Pnet预测的粗略的框进行宽和高的修正,使得调整后的框更符合人脸的一个大小。

Rnet也有两个输出classifier和bbox_regress: classifier用于判断这个网格点上的框的可信度,bbox_regress用来辅助调整Pnet获得的粗略框,表示调整后的框的位置。
经过这样调整之后我们就进行非极大值抑制操作进行再次筛选,保留下来比Pnet更优秀的一些框,但是还会存在如上图中右图的那个眼睛部分的那样的小框问题,所以要进入一个比Rnet更严格的神经网络Onet进行修正。
Rnet网络:

最后对Rnet选定的候选框进行Bounding-Box Regression和非极大值抑制NMS进一步优化预测结果。
Rnet的两个输出classifier和bbox_regress,bbox_regresss并不代表这个框在图片上的真实位置,而是调整参数,所以如果需要将bbox_regress映射到真实图像上,还需要进行解码操作:
解码过程需要与Pnet的结果进行结合。 在代码中,x1、y1、x2、y2代表由Pnet得到的图片在原图上的位置,w=x2-x1和h=y2-y1代表Pnet得到的图片的宽和高,bbox_regress与Pnet的结果结合的方式如下:
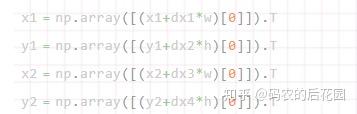
其中dx1、dx2、dy1、dy2就是Rnet获得的bbox_regress,实际上Rnet获得bbox_regress是长宽的缩小比例。
Rnet解码代码

4.Onet
Onet和Rnet的工作流程十分相似,它的全称为Output Network, 基本结构是一个较为复杂的卷积神经网络,相对于Rnet来说多了一个卷积层。Onet的效果与Rnet的区别在于Onet的这一层结构会通过更多的监督来识别面部的区域,而且会对人的面部特征点进行回归,最终输出5个人脸面部特征点。

Onet会对Rnet的输出,也是Onet的输入,进行再次调整以消除像Rnet的输出中眼睛部分的这样的框框。首先我们会对Rnet网络输出结果中的候选框对应的原图中这样的区域截取出来传入到Onet网络中,Onet会首先判断这个截取出来的区域是否真正含有人脸,然后对这个区域的Rnet的候选框的长和宽进行调整,与此同时识别出人脸面部的5个特征点。
因此Onet会有3个输出:classifier、bbox_regress、landmark_regress
- claassifier: 这个网格点上框的可信度
- bbox_regress: 这个网格点上框调整的一个范围
- landmark_regress: 表示人脸上的5个标志点
Onet网络:


最后对Onet网络选定的候选框进行Bounding-Box Regression和NMS进一步优化预测结果。
Onet有三个输出,classifier用于判断这个网格点上的框的可信度,bbox_regress表示框的位置,landmark_regress表示脸上的五个标志点。
bbox_regress并不代表这个框在图片上的真实位置,如果需要将bbox_regress映射到真实图像上,还需要进行一次解码过程。
解码过程需要与Rnet的结果进行结合。在代码中,x1、y1、x2、y2代表由Rnet得到的图片在原图上的位置,w=x2-x1和h=y2-y1代表宽和高,bbox_regress与Rnet的结果结合的方式如下:
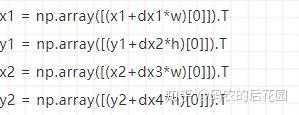
其中dx1、dx2、dy1、dy2就是Onet获得的bbox_regress,实际上Onet获得bbox_regress是长宽的缩小比例。
Onet解码过程:


04 论文和代码下载
在后台回复关键字:项目实战,获取Mtcnn论文和项目源码。
05环境配置
- Windows10
- Anaconda + Pycharm
- tensorflow-gpu==1.15.0
- keras-gpu==2.1.5
06Mtcnn预测结果


人脸检测是实现人脸识别的第一步,下期就讲解如何借助Mtcnn人脸检测算法和facenet算法搭建人脸识别平台,代码下载:更多有关python、深度学习和计算机编程和电脑知识的精彩内容,可以关注微信公众号:码农的后花园 , 如果觉得不错的话,请给号主一个点赞吧! 感谢!
