这里还是以课堂派登录的接口为例子。
参考用法requests官方文档地址:https://2.python-requests.org//zh_CN/latest/user/advanced.html#advanced

如上图所示先实例化一个session对象,通过里面的session方法发送post请求,最后打印返回的结果。返回状态码为200,status值为1,证明登录成功。
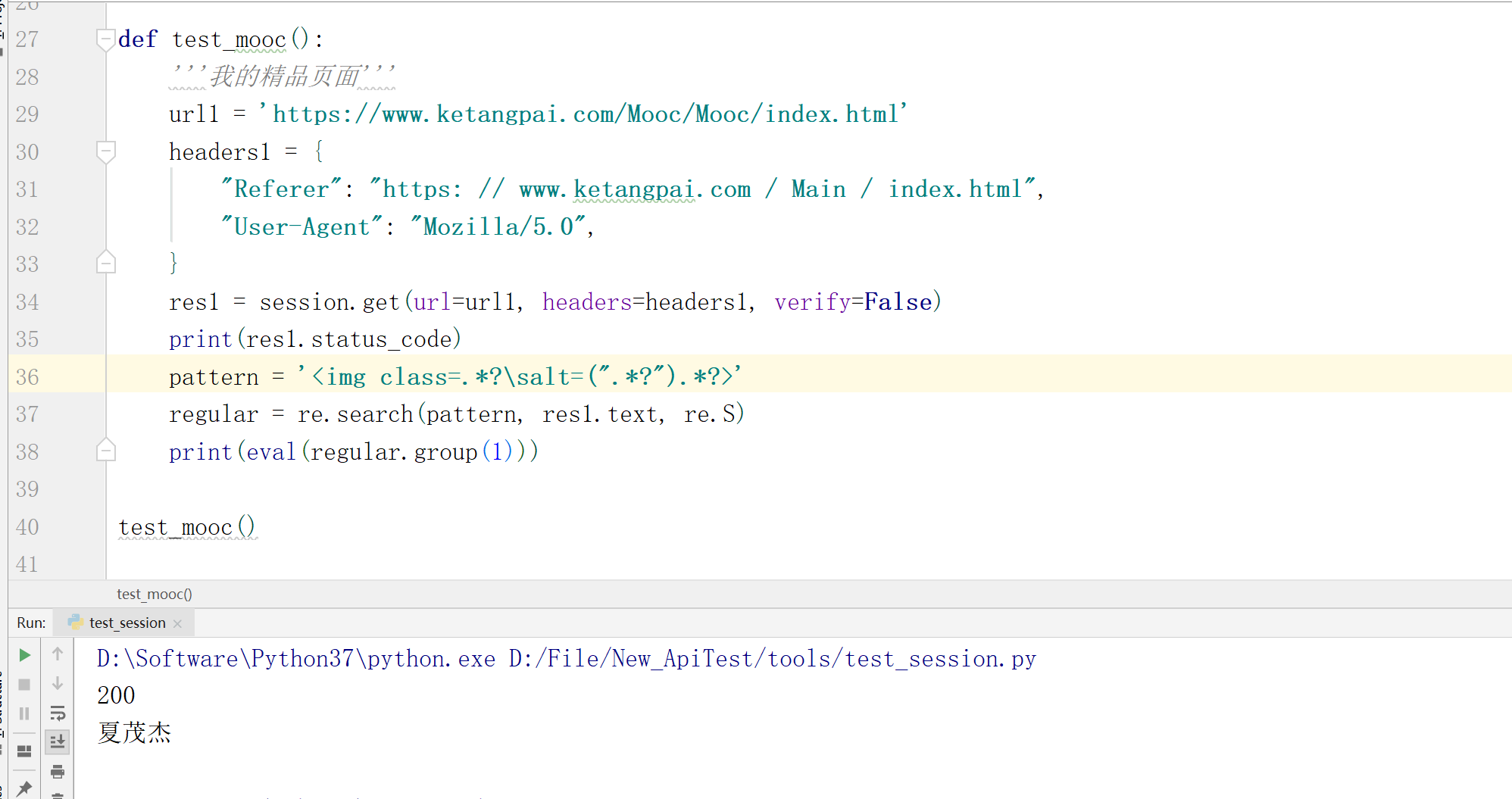
如上图,获取精品页面信息,使用session会话继续发送了一个get请求,在没有使用cookies的情况下,获取页面信息成功,并通过正则匹配出了学生的姓名。
代码如下:
import re import requests import urllib3 urllib3.disable_warnings() session = requests.session() def test_normal_login(): '''正常登录''' url = 'https://www.ketangpai.com/UserApi/login' data = { "email": "1489088761@qq.com", "password": "A123456", "remember": 0} headers = { "User-Agent": "Mozilla/5.0", "Content-Type": "application/x-www-form-urlencoded", } login_res = session.post(url, data, headers, verify=False) # print(login_res.status_code) # print(login_res.json()['status']) # print(login_res.content.decode('utf-8')) test_normal_login() def test_mooc(): '''我的精品页面''' url1 = 'https://www.ketangpai.com/Mooc/Mooc/index.html' headers1 = { "Referer": "https: // www.ketangpai.com / Main / index.html", "User-Agent": "Mozilla/5.0", } res1 = session.get(url=url1, headers=headers1, verify=False) print(res1.status_code) pattern = '<img class=.*?salt=(".*?").*?>' regular = re.search(pattern, res1.text, re.S) print(eval(regular.group(1))) test_mooc()