usage:
import unittest from ddt import ddt,data,unpack test_data=[15826276815,'mg123456'],[5,6] @ddt class TestStudyDdt(unittest.TestCase): # todo 单个参数参数化 @data(*test_data) def test_print_data1(self,data): print('数据如下:',data) # todo 多个参数参数化 @data(*test_data) @unpack def test_print_data2(self,data,data1): print('数据1如下:',data) print('数据2如下:',data1) if __name__ == '__main__': unittest.main()
打印结果如下:

字典参数化:
import unittest from ddt import ddt,data,unpack # 字典参数化 test_data = {'phone':1582627815,'pawd':'mg123456'},{'phone':158262768151,'pawd':'mg1234561'} @ddt class TestDdt(unittest.TestCase): @data(*test_data) @unpack # todo 字典格式使用unpack必须test_data数据里面的key,value对应 def test_print_data2(self, phone, pawd): print('数据1如下:', phone) print('数据2如下:', pawd) if __name__ == '__main__': unittest.main()
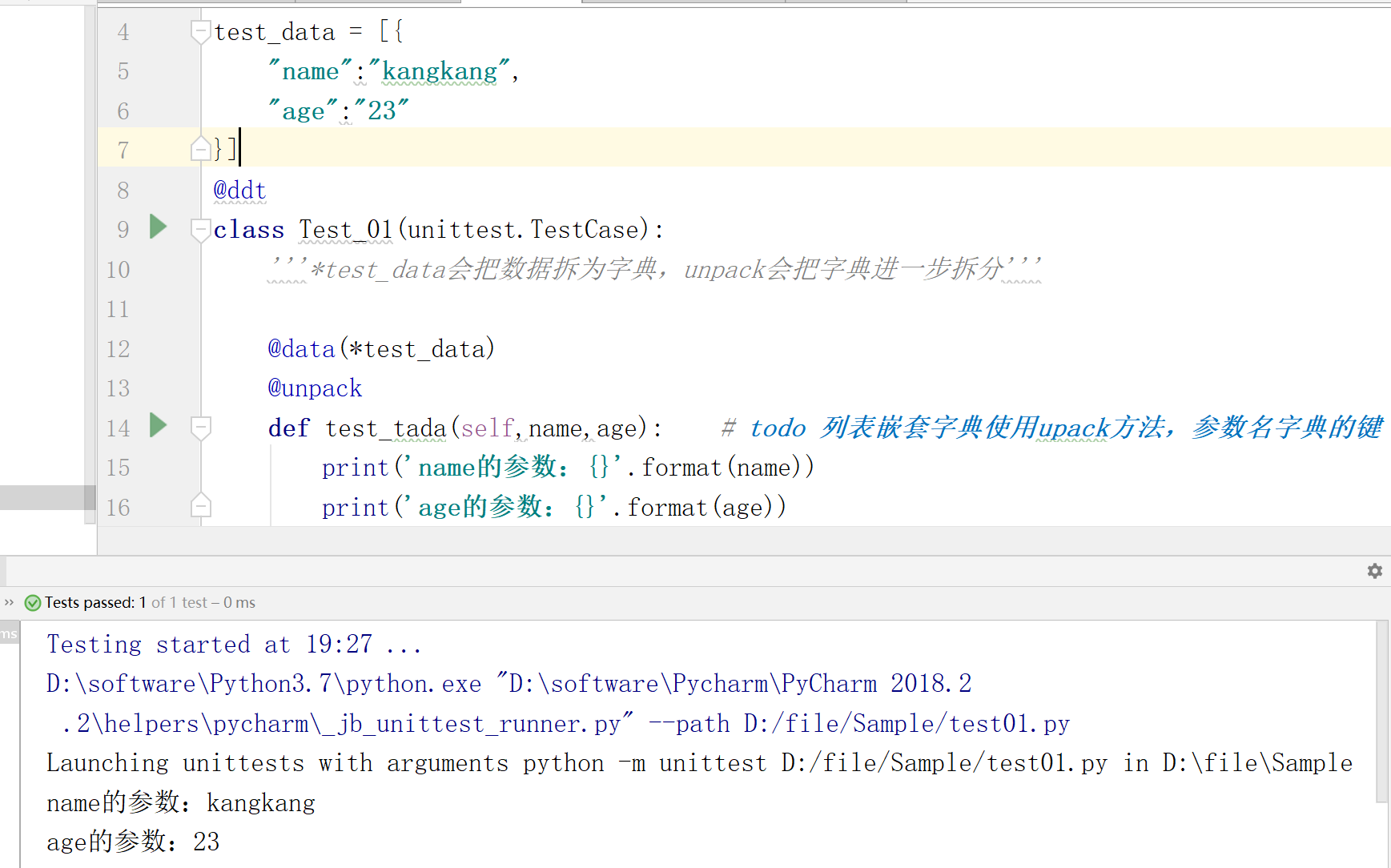
import unittest from ddt import ddt,data,unpack test_data = [{ "name":"kangkang", "age":"23" }] @ddt class Test_01(unittest.TestCase): '''*test_data会把数据拆为字典,unpack会把字典进一步拆分''' @data(*test_data) @unpack def test_tada(self,name,age): # todo 列表嵌套字典使用upack方法,参数名字典的键 print('name的参数:{}'.format(name)) print('age的参数:{}'.format(age))
结果如图: