NIO是对I/O处理的进一步抽象,包含了I/O的基础概念。我是基于网上博友的博客和Ron Hitchens写的《JAVA NIO》来学习的。
NIO的三大核心内容:缓冲区,通道,选择器。
一,buffer缓冲区
1,家谱

除了以上的基础类型对应的buffer之外,还有一种MappedByteBuffer,是ByteBuffer的子类, 专门用于内存映射文件的一种特例。
2,buffer 缓冲区基础
概念上,缓冲区是包在一个对象内的基本数据元素数组。
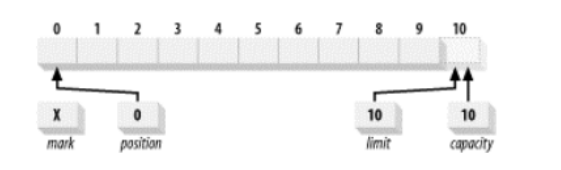
2.1,属性
容量( capacity)
缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能
被改变。
上界(limit)
缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
位置(position)
下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新。
标记(mark)
一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position =
mark。标记在设定前是未定义的(undefined)。
这四个属性之间总是遵循以下关系:
0 <= mark <= position <= limit <= capacity
2.2,buffer 缓冲区 API
package java.nio;
public abstract class Buffer {
public final int capacity( )
public final int position( )
public final Buffer position (int newPositio
public final int limit( )
public final Buffer limit (int newLimit)
public final Buffer mark( )
public final Buffer reset( )
public final Buffer clear( )
public final Buffer flip( )
public final Buffer rewind( )
public final int remaining( )
public final boolean hasRemaining( )
public abstract boolean isReadOnly( );
}
注意:clear()函数一般返回void。isReadOnly()函数用来标记该缓冲区内容是否可改变,因为所有的缓冲区都是可读的,但不一定都是可写的。
2.3,buffer 缓冲区的存取
public abstract class ByteBuffer
extends Buffer implements Comparable
{
// This is a partial API listing
public abstract byte get( );
public abstract byte get (int index);
public abstract ByteBuffer put (byte b);
public abstract ByteBuffer put (int index, byte b);
}
在上文所列出的的 Buffer API 并没有包括 get()或 put()函数。每一个 Buffer 类都有这
两个函数,但它们所采用的参数类型,以及它们返回的数据类型,对每个子类来说都是唯一
的,所以它们不能在顶层 Buffer 类中被抽象地声明。它们的定义必须被特定类型的子类所遵
从。
2.4,翻转
我们已经写满了缓冲区,现在我们必须准备将其清空。我们想把这个缓冲区传递给一个通
道,以使内容能被全部写出。flip()函数将一个能够继续添加数据元素的填充状态的缓冲区翻转成一个准备读出元素
的释放状态。
2.5,批量移动
如果一次只能读取一个字节,那这样的效率太低了,所以buffer有提供批量移动的函数
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public CharBuffer get (char [] dst)
public CharBuffer get (char [] dst, int offset, int length)
public final CharBuffer put (char[] src)
public CharBuffer put (char [] src, int offset, int length)
public CharBuffer put (CharBuffer src)
public final CharBuffer put (String src)
public CharBuffer put (String src, int start, int end)
}
有两种形式的 get( )可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组
作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指
定目标数组的子区间。
3,创建缓冲区
以下API以CharBuffer为例:
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public static CharBuffer allocate (int capacity)
public static CharBuffer wrap (char [] array)
public static CharBuffer wrap (char [] array, int offset,
int length)
public final boolean hasArray( )
public final char [] array( )
public final int arrayOffset( )
}
其中allocate()函数需要指定缓冲区的大小。
4,复制缓冲区
以CharBuffer为例
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public abstract CharBuffer duplicate( );
public abstract CharBuffer asReadOnlyBuffer( );
public abstract CharBuffer slice( );
}
其中Duplicate()函数创建了一个与原始缓冲区相似的新缓冲区。两个缓冲区共享数据元素,拥有同样的容量,但每个缓冲区拥有各自的位置,上界和标记属性。
5,字节缓冲区 ByteBuffer
作为NIO最为重要的ByteBuffer字节缓冲区,只有字节缓冲区能够与NIO通道共用。字节是操作系统及其 I/O 设备使用的基本数据类型。当在 JVM 和操作系统间传递数据时,将其他的数据类型拆分成构成它们的字节是十分必要的。
5.1,字节大小
各个基础类型的字节大小,每个基本数据类型都是以连续字节序列的形式存储在内存中。

在网络传输过程,还会涉及到一个重要的内容:网络字节序。在java代码的网络传输过程中,默认是大端字节顺序。
如果数字数值的最高字节——big end(大端),位于低位地址,那么系统就是大端字节顺序,如果最低字节最先保存在内存中,那么小端字节顺序。


大端字节顺序 小端字节顺序
当Internet的设计者为互联各种类型的计算机而设计网际协议( IP)时,他们意识到了在具有不同内部字节顺序的系统间传递数值数据的问题。因此, IP协议规定了使用大端的网络字节顺序概念 4。所有在IP分组报文的协议部分中使用的多字节数值必须先在本地主机字节顺序和通用的网络字节顺序之间进行转换。