学号 20194123《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1941
姓名: 向海飞
学号:20194123
实验教师:王志强
实验日期:2020年6月13日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
选择:爬虫
2. 实验过程及结果
需要用到 bs4 、正则表达式、requests 的知识
找到网址http://zuihaodaxue.cn/ARWU2015.html
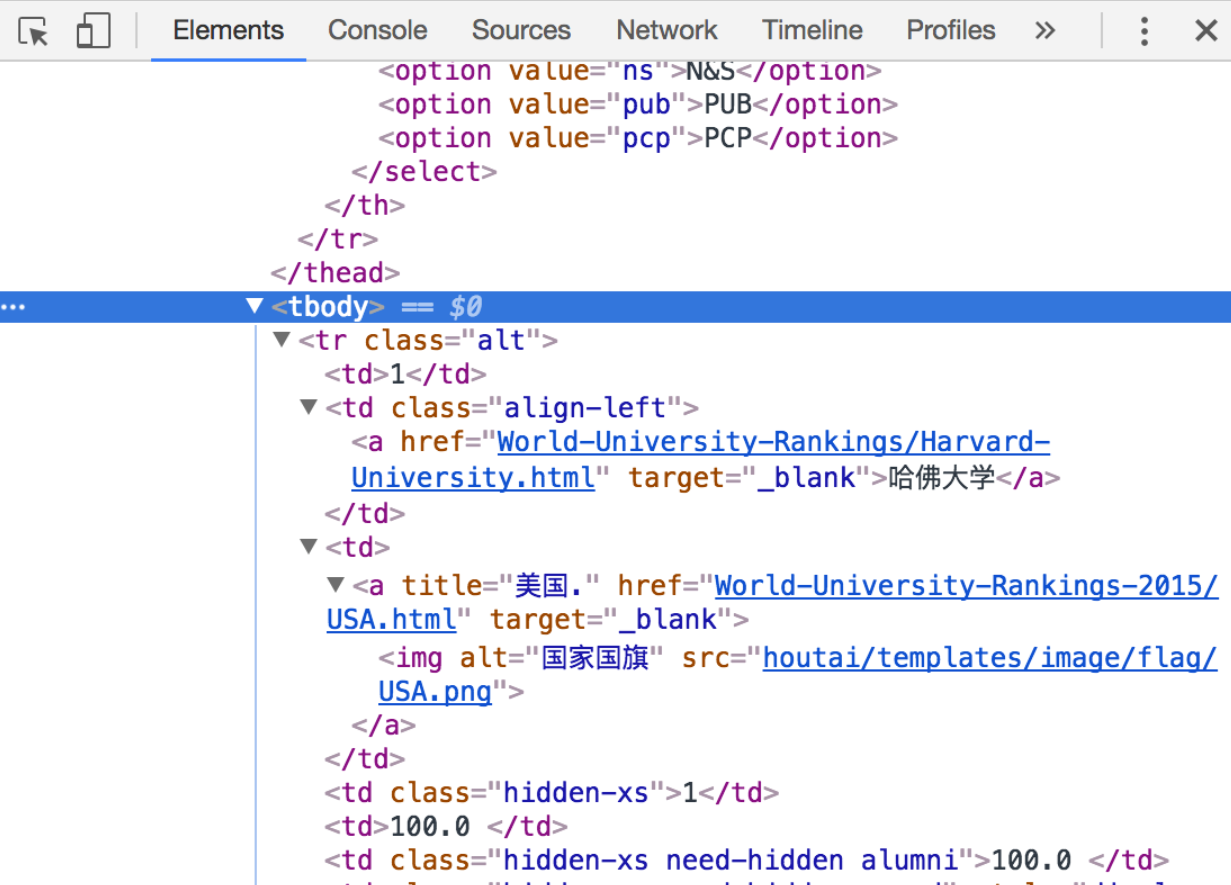
如图知数据块是 tbody,分析得html 中一行对应一个tr,世界排名、国家排名、总分可以直接通过 tr[‘td’] 获得,而学校需要通过 tr[‘td’].a.string 获得,国家/地区需要通过 tr[‘td’].a[‘title’] 获得
过程如下:
导入相关库:
import requests
from bs4 import BeautifulSoup
import bs4
获取网页数据
ef getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
解析网络数据
ef fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([ tds[0].string, tds[1].a.string, tds[2].a['title'], tds[3].string, tds[4].string ])
显示数据
def printUnivList(ulist, num):
tplt = "{0:10} {1:44} {2:16} {3:16} {4:^16}"
print(tplt.format("世界排名", "学校名称", "国家/地区", "国家排名", "总分"), chr(12288))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]), chr(12288))
def main():
uinfo = []
url = 'http://zuihaodaxue.cn/ARWU2015.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 80) # 20 univs
if name == 'main':
main()
结果如下图:

3. 实验过程中遇到的问题和解决过程
- 问题1:requests安装失败
- 问题1解决方案:因为用户名包含中文,所以安装失败,在安装目录 ,找到mimetypes.py文件,添加代码,完成后保存,在cmd中执行pip install requests,如下图所示,关于ascii的问题解决
其他(感悟、思考等)
学习python已经有一学期了,我在本学期中学会了python的语言基础,流程控制语句,其中for和while循环是最让我花时间得,,后来得序列,函数都还好,但到了面向对象程序设计后就有些跟不上了。说实话对我来说有些困难,我原本以为我就算一时间不会的话也可以多花时间练习,但后来逐渐发现自己一天的课和作业下来就没多长时间了,所以我学习python主要是在周三上课的时候,有时周末也会找云班课学习一下。虽然有很多知识点都没有很搞懂,但总的来说,这学期收获还是很多的,因为以前选的文科,总觉得自己也应该尝试新的领域,所以学习python也算是得偿所愿吧。