先说一下几个概念:
架构:简单的说架构就是一个蓝图,是一种设计方案,将客户的不同需求抽象成为抽象组件,并且能够描述这些抽象组件之间的通信和调用。
框架:软件框架是项目软件开发过程中提取特定领域软件的共性部分形成的体系结构,不同领域的软件项目有着不同的框架类型。框架不是现成可用的应用系统。而是一个半成品,提供了诸多服务,开发人员进行二次开发,实现具体功能的应用系统。例如java中的集合框架,就是一些代码,方便你使用。
设计模式:是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结,它强调的是一个设计问题的解决方法。
例子:
三层架构:一种设计软件架构的思想
把软件上从逻辑上分为、表示层(UI)业务逻辑层(BLL)数据访问层(DAL)
目的:低耦合、高内聚、各司其职、达到易更换、修改、可以分散部署、编码。
MVC(框架)
英文Model View Controller、是针对Web开发、已经写好有代码的框架、分别为M模型(model)-V视图(view)-C控制器(controller)三部分
目的:模型和视图分离开、使得一个模型可被多个视图使用、简单说就是同样的一个网站、用手机的视图(界面)和电脑的视图、可以共用一个模型。
传统架构到分布式架构的演变
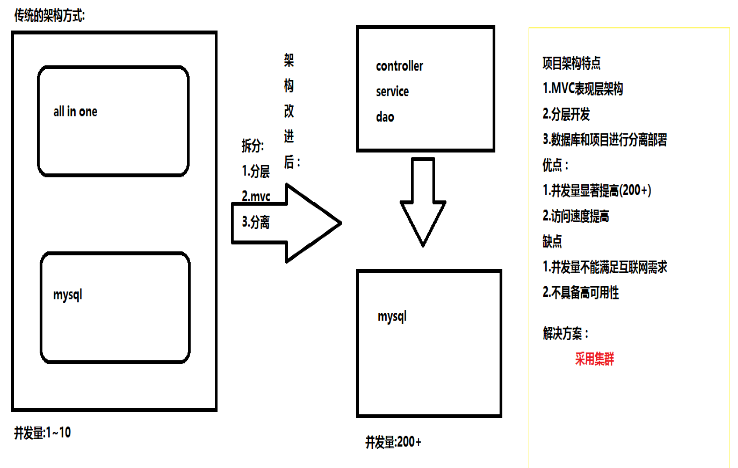
1.传统项目的架构:
特点:
1)all in one(所有模块在一起,技术也不分层),
注:像05年06年那会儿,就是这样,把代码写在jsp里面,那时候还没有分层的概念,把所有的东西都写在一起,这就叫做all in one
2)servlet(jsp)
缺点:
1)并发量差
2)容错性差(不具有高可用性)
注:不具有高可用性的意思是,比如当用户访问时,服务器后台因为一些原因导致服务器崩溃,用户就能直接看到错误页面,服务器也因为错误从而停止运行(宕机),这就叫做不具有高可用性。
解决方案:
1)分层开发(可以提高并发量)
2)mvc架构
3)服务器的分离部署
画图说明:
集群的配置

2,集群架构:
特点:
1.项目采用多台服务器集群部署
2.mysql数据库采用多台服务器集群部署
优势:
1.并发量提高(1000+)
2.容错性提高(具有高可用性)
注:一般的it公司,基本都是采用集群架构,因为这种架构方式已经基本能满足需求了,但是一些大型项目,这种方式就显然是力不从心了,只能采用分布式的架构方式
问题:
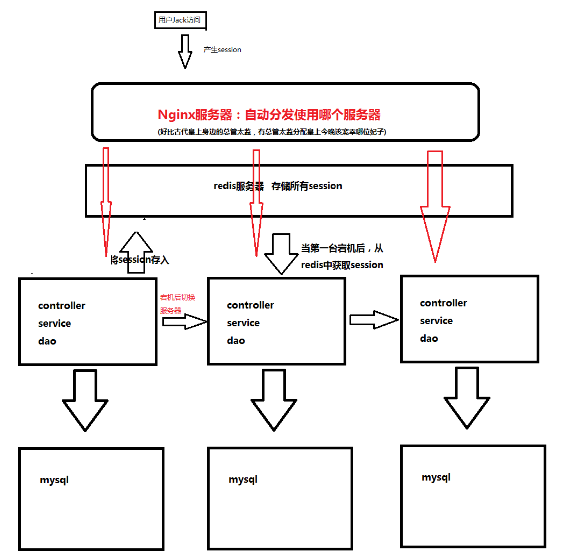
通过上图我们发现这种集群部署存在两个问题,什么问题呢?
1.session如何共享?
我们都知道,session是会话,即一个用户访问服务器的时候,就会产生一个session,这个session会一致伴随着这个用户的访问全程,直到用户关闭浏览器结束这次会话,那么问题来了,如果用户访问服务器时,这台服务器挂掉了(宕机),那么原先保存在这台服务器上的session也肯定挂掉了,那么就会产生一个后果,就是这个用户原本访问好好的,现在突然session没有了,而session没有了就意味着需要用户重新登陆才能进行一些相应操作,这显然是不行的,这样的服务用户体验实在太差了,根本不能满足互联网行业的用户需求,那么这就涉及到一个session共享的问题,即怎么把原有的session从一台服务器转移到另一台服务器上,但是怎么解决呢?有多种方案,但咱们今天先说两种:
第一种解决方案:
用Tomcat集群复制(广播模式)来共享session:
这种解决方案是利用Tomcat来进行集群复制,把每个服务器上的session都共享式的都复制一遍,保证每个服务器上都有着一个用户的session数据
应用场景:在传统项目中一般这么应用,因为传统项目的用户量少,可以承担压力,但当到互联网项目时,这种方式就绝对不可取了,打个比方,比如用户量有100万,那么就需要在每个服务器上都复制这100万个用户的session,这样做显然会极大的消耗系统资源,使系统变得极为臃肿和不稳的,所以在互联网项目里是绝对不会采用这种方式的。
缺点:当有大量用户时,服务器的压力会亚历山大,所以只适合用户访问量小的传统项目。
第二种解决方案:
用第三方redis服务器来存储session
用这种方式来存储session的话,只需当前正在使用的项目把所有session都放在redis里面,当有其他项目需要使用时,就可以直接从redis中直接获取session,从而解决了这个问题。
示例图:

2.这么服务器,请求该往哪发送?
用nginx服务器来分发请求,实现负载均衡。
这种架构的并发量是多少呢?大概是1000+左右,如果服务器更多的话,能达到1000以上,一万以下,但是这能满足互联网的极致要求呢?答案当然是不能了,虽说也可以不断的扩展服务器,但是对于公司的成本和维护成本来说,无疑会达到一个非常高昂的消耗,比如说一台最便宜的服务器的价格大概是3到5万,假如要抵御一万的并发,每台服务器能支持200的并发率,那么需要多少台服务器?50台!这还仅是单击版的,还构建集群呢?比如说构建3台服务器,3*50=150台,服务器构建完了,数据库呢?数据库也需要构建集群呀!,这就又是好几百台,
所以,这种情况下我们就必须对我们的架构来进行优化了,那么如何在服务器只有一定数量的情况下,让我们的项目的成本能达到一定控制,并且让我们的项目达到一个最优化的并发的访问量呢?那么就需要对现有的这种架构进行再次拆分,让我们的项目成为面向服务的分布式架构。
3,面向服务的分布式架构(SOA):
1)webservice

如图所示,第一种方式还是有着明显的缺点的,如服务层的网路抖动或是服务层进程繁忙,可能有人对这两个名词不太理解,这里就解释一下:
网络抖动:当有大量用户访问时,可能会出现service层的延迟现象,而web层因为长期得不到响应,则会抛出时间超出异常
进程繁忙:这个的意思和前边的差不多,都是指service层业务太多,顾不上web层的请求,web层的请求就只能一直在那等着,时间长了也就抛出超时异常了
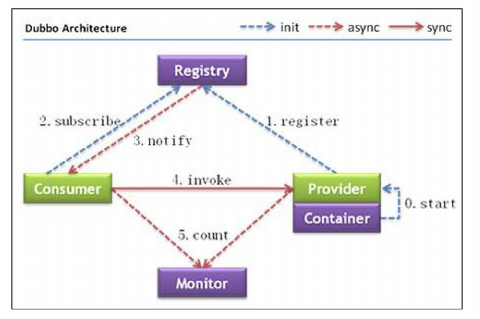
2)服务治理中间件:
dubbo

原理讲解:看了第一种webservice的方法之后,我们采用了第二种方法,即dubbo这种中间件的方式,采用这种方式有什么好处呢?
好处:
当服务器启动时service会把所有的对象通过dubbo注册给zookeeper,而以后每次需要请求获取对象时,就可以直接从dubbo中异步获取,不需要再去访问service层,这样就解决了服务层网络抖动和服务层进程繁忙的弊端。zeekeeper可以看成是一个数据库,用来存储数据的,具体的原理以后会专门开篇文章描述它。
网上淘淘商城的实例:



详细使用参见网上的淘淘商城项目。
当然现在目前还有一种比分布式更火的架构模式,叫做微架构,它是通过服务的原子化拆分,以及微服务的独立打包、部署和升级,可以让小团队的交付周期将缩短,运维成本也将大幅度下降,可以预见,这种架构模式将会越来越受到广大企业的应用与喜爱。
https://www.cnblogs.com/Survivalist/p/8012266.html
https://blog.csdn.net/u014390502/article/details/53573413