今天呢,完成了爬取相关数据到数据库,热词目录,热词,热词解释,以及热词相关的文章标题和链接,我把它爬取到三个表中。这样在写后台就方便提取数据。


import requests from lxml import etree import time import pymysql import datetime import urllib import json import jieba import pandas as pd import re import os from collections import Counter conn = pymysql.connect( host="localhost", user="root", port=3306, password="123456", database="hotwords") #将热词插入数据库 def dbinsertwords(k,indexname): cursor = conn.cursor() cursor.execute( "INSERT INTO hotwords (name,newstype) VALUES (%s,%s);", [k, indexname]) conn.commit() cursor.close() def dbgetWordsName(): cursor =conn.cursor() cursor.execute("select name from hotwords;") datas = cursor.fetchall() data = [] for row in datas: data.append(row[0]) return data cursor.close() conn.commit() conn.close() def dbgetWordsId(): cursor = conn.cursor() cursor.execute("select * from hotwords;") datas = cursor.fetchall() data = [] for row in datas: data.append(row[0]) return data cursor.close() conn.commit() conn.close() def dbinsertExplain(id,word,explain): print(id) print(word) print(explain) cursor = conn.cursor() sql ="update hotwords set wordexplain='"+explain+"'where wordsid= "+str(id) print(sql) cursor.execute(sql) # cursor.close() conn.commit() # conn.close() def dbgethotwords(): cursor = conn.cursor() cursor.execute("select * from hotwords;") datas = cursor.fetchall() data = [] data2 = [] for row in datas: data.append(row[1]) data2.append(row[2]) return data,data2 cursor.close() conn.commit() conn.close() def dbinsertHref(title,url,name,type): cursor = conn.cursor() cursor.execute( "INSERT INTO title_href (title,href,wordname,newstype) VALUES (%s,%s,%s,%s);", [title, url,name,type]) conn.commit() cursor.close() def loopNewsType(): for i in range(1101,1111): if i == 1104 or i ==1105 or i ==1106 or i ==1107 or i ==1108 or i ==1109: i = i+5 elif i == 1110: i = 1199 #遍历页数 getDiffPage(i) def getDiffPage(i): if i == 1199: #86页数据 for page in range(0, 5): #得到每页信息 type = '其他' getEachPage(page,i,type) else: #100页数据 for page in range(0, 5): # 得到每页信息 type = '一般' getEachPage(page,i,type) def getEachPage(page,i,type): url = "https://news.cnblogs.com/n/c" + str(i) +"?page=" +str(page) r = requests.get(url) html = r.content.decode("utf-8") html1 = etree.HTML(html) href = html1.xpath('//h2[@class="news_entry"]/a/@href') title = html1.xpath('//h2[@class="news_entry"]/a/text()') indexname1 = html1.xpath('//div[@id = "guide"]/h3/text()') indexname = indexname1[0].replace(' ', '').replace('/','') #indexname为热词新闻类型 print(indexname) file = open("middle/"+indexname+".txt", "a+", encoding='utf-8') print(len(href)) for a in range(0, 18): print(href[a],title[a]) #得到标题和链接 #getDetail(href[a], title[a]) file.write(title[a]+ ' ') print("页数:"+str(page)) if type == '一般' and page ==4: print("函数里") file = open("middle/" + indexname + ".txt", "r", encoding='utf-8') getKeyWords(file,indexname) if type == '其他' and page == 4: file = open("middle/" + indexname + ".txt", "r", encoding='utf-8') getKeyWords(file, indexname) #分析词频,得到热词 def getKeyWords(filehandle,indexname): print("getKeyWords") mystr = filehandle.read() #print(mystr) seg_list = jieba.cut(mystr) # 默认是精确模式 print(seg_list) stopwords = {}.fromkeys([line.rstrip() for line in open(r'stopwords.txt')]) c = Counter() for x in seg_list: if x not in stopwords: if len(x) > 1 and x != ' ': c[x] += 1 print(' 词频统计结果:') for (k, v) in c.most_common(10): # 输出词频最高的前两个词 print("%s:%d" % (k, v)) dbinsertwords(k,indexname) #print(mystr) filehandle.close(); def wordsExplain(): # for root, dirs, files in os.walk("final"): # print(files) # 当前路径下所有非目录子文件 # print(len(files)) # for i in range(0,len(files)): # # filename = files[i].replace(".txt","") # #热词名称 # print(files[i]) # getExpalin(files[i]) # #break words = dbgetWordsName() ids =dbgetWordsId() print(len(words)) print(len(ids)) for i in range(0,len(words)): #print(words[i]) explain = climingExplain(words[i]) #print(explain) if ids[i] == None: pass else: dbinsertExplain(ids[i],words[i],explain) def getExpalin(filename): lines =[] for line in open("final/"+filename,encoding='utf-8'): explain = climingExplain(line) line = line +" "+explain print(explain) print("line:"+line.replace(" ","")) lines.append(line.replace(" ","")) #f = open("final/"+filename, 'w+',encoding='utf-8') # f.write(line + " ") f = open("final/"+filename, 'w+',encoding='utf-8') for i in range(0, len(lines)): f.write(lines[i] + " ") f.close() #爬取解释 def climingExplain(line): line1=line.replace(' ','') #print(line1) url = "https://baike.baidu.com/item/"+str(line1) #print(url) head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36', 'cookie':'BAIDUID=AB4524A16BFAFC491C2D9D7D4CAE56D0:FG=1; BIDUPSID=AB4524A16BFAFC491C2D9D7D4CAE56D0; PSTM=1563684388; MCITY=-253%3A; BDUSS=jZnQkVhbnBIZkNuZXdYd21jMG9VcjdoanlRfmFaTjJ-T1lKVTVYREkxVWp2V2RlSVFBQUFBJCQAAAAAAAAAAAEAAACTSbM~Z3JlYXTL3tGpwOTS9AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACMwQF4jMEBed; pcrightad9384=showed; H_PS_PSSID=1454_21120; delPer=0; PSINO=3; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; __yjsv5_shitong=1.0_7_a3331e3bd00d7cbd253c9e353f581eb2494f_300_1581332649909_58.243.250.219_d03e4deb; yjs_js_security_passport=069e28a2b81f7392e2f39969d08f61c07150cc18_1581332656_js; Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1580800784,1581160267,1581268654,1581333414; BK_SEARCHLOG=%7B%22key%22%3A%5B%22%E7%96%AB%E6%83%85%22%2C%22%E6%95%B0%E6%8D%AE%22%2C%22%E9%9D%9E%E6%AD%A3%E5%BC%8F%E6%B2%9F%E9%80%9A%22%2C%22mapper%22%5D%7D; Hm_lpvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581334123' } r = requests.get(url,headers = head) #print(r.status_code) html = r.content.decode("utf-8") #print(html) html1 = etree.HTML(html) #print(html1) content1 = html1.xpath('//div[@class="lemma-summary"]') #print(content1[0]) if len(content1)==0: #custom_dot para-list list-paddingleft-1 content1 =html1.xpath('string(//ul[@class="custom_dot para-list list-paddingleft-1"])') print(content1) if len(content1)==0: print('未找到解释') content1 = '未找到解释' return content1 else: content2 =content1[0].xpath ('string(.)').replace(' ','').replace(' ','') return content2 print(content2) def words_href(): # print(dbgethotwords()) data = dbgethotwords() name = data[0] type = data[1] print(name) #遍历新闻,然后与这些热词比对,记得带上type一起插入数据库 for i in range(0, 50): print(i) page = i + 1 url = "https://news.cnblogs.com/n/page/" + str(page) r = requests.get(url) html = r.content.decode("utf-8") html1 = etree.HTML(html) href = html1.xpath('//h2[@class="news_entry"]/a/@href') title = html1.xpath('//h2[@class="news_entry"]/a/text()') for a in range(0,30): getHref(href[a],title[a],name,type) # print(len(href)) def getHref(href,title,name,type): print(title) url = "https://news.cnblogs.com" + href for i in range(0,len(name)): m = title.find(name[i]) if m != -1: dbinsertHref(title,url,name[i],type[i]) else: pass if __name__=='__main__': #遍历得到不同新闻类型链接尾部数字 #loopNewsType() #热词解释 #wordsExplain() #热词引用链接 words_href()
这个代码整合了我之前用到的很多片段化的方法。然后得到的数据如下:

newstype表:
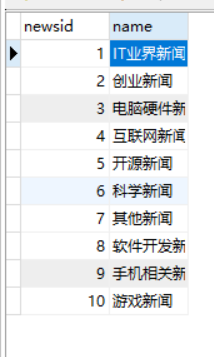
howwords表:

title_href表:

嗯。在调用界面获取相关的新闻目录下的具体热词遇到了问题,获取的热词总数巨大,目前还没解决。目前能看的只有这个。

嗯。浏览了很多别人的博客,感觉差距还是有的,我想说的是,虽然我现在不强,但不代表我以后不强,毕竟也是要在这一行混很久的男人。一点点的积累,一点点的成长。
虽然以前态度不太端正,落下了不少,不过没关系,我相信我可以慢慢的补回来然后更厉害!没事,能多学点就多学点。就这样吧,晚安,The World