这一章将学习散列机制是如何工作的,以及在使用散列容器时怎么样编写hashCode()和equals()方法。
一、容器分类
先上两张图 来概况完整的容器分类 再细说都为什么会有那些特性。
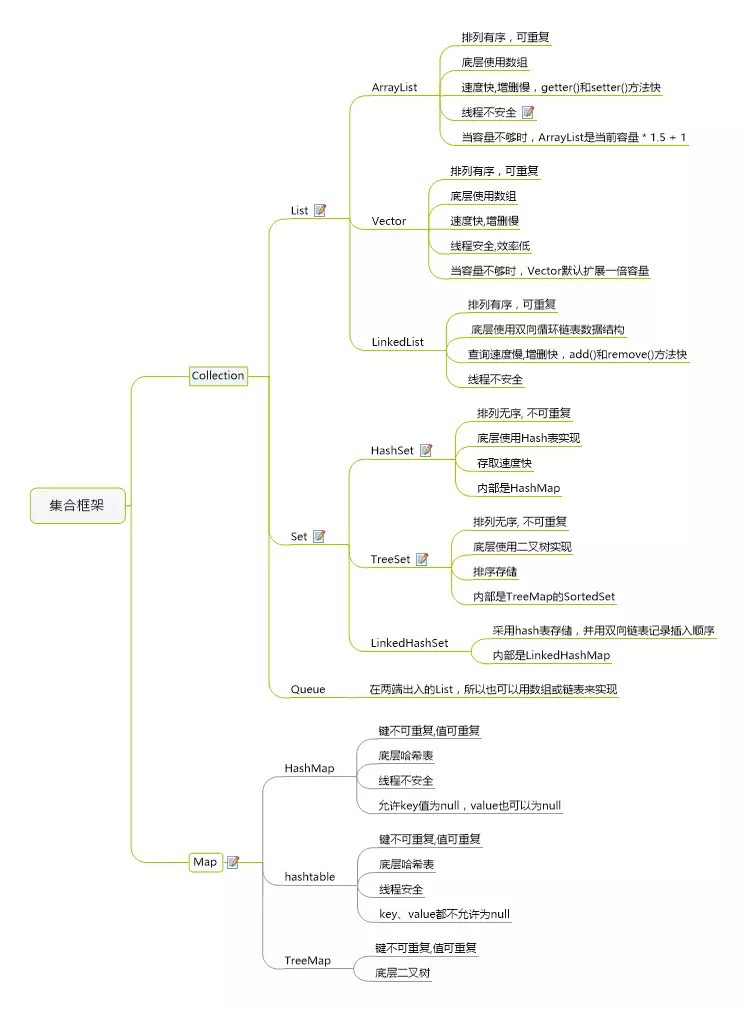
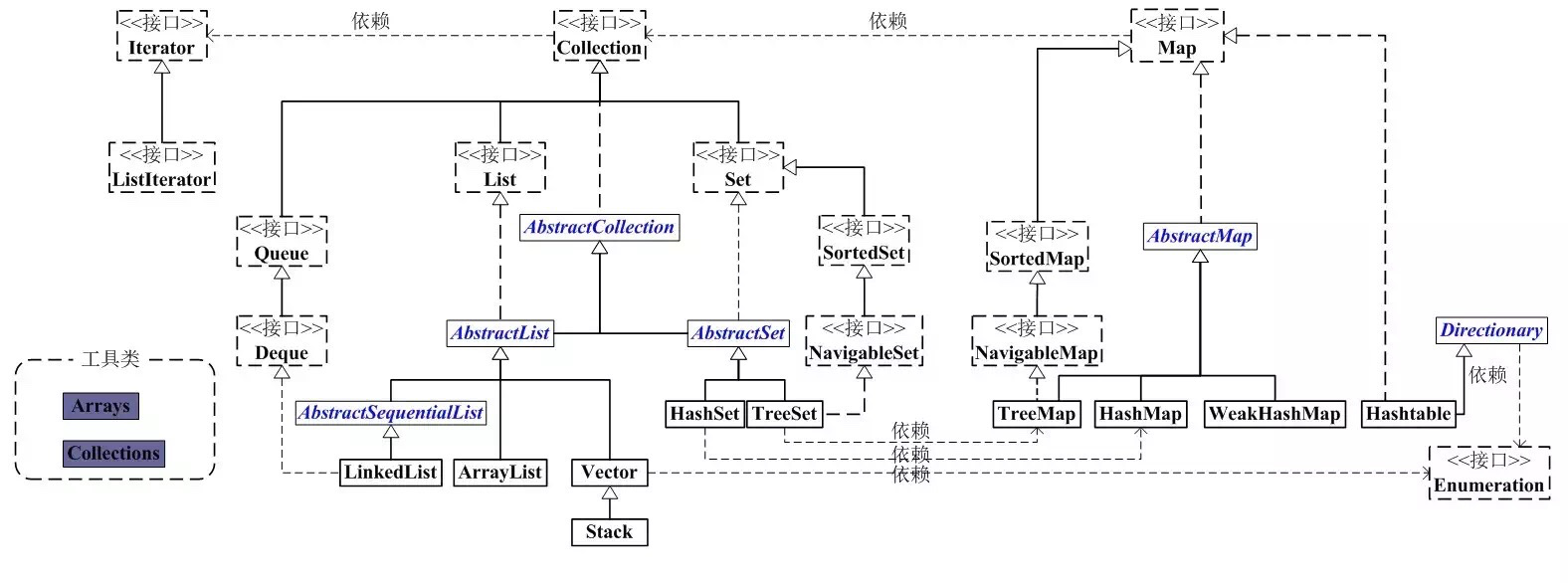
二、Collection的功能方法
int size();容器大小
boolean isEmpty();容器内没有元素,返回true
boolean contains(Object o);容器内含有此参数,返回true
Iterator<E> iterator(); 返回一个Iterator<E> 用于遍历
Object[] toArray();返回一个包含所有容器中元素的数组
<T> T[] toArray(T[] a); 返回一个包含所有容器内元素的数组,但返回类型为T而不简单是Object
boolean add(E e);像容器添加内容添加失败返回false(可选的)
boolean remove(Object o);移除一个元素,成功返回true(可选的)
boolean containsAll(Collection<?> c);若包含参数中的所有元素,返回true
boolean addAll(Collection<? extends E> c);添加参数中所有元素,有任意元素添加成功则返回true(可选的)
boolean removeAll(Collection<?> c);一处参数中所有元素,有任何元素移除则返回true(可选的)
default boolean removeIf(Predicate<? super E> filter) * 1.8新增 移除满足参数参数条件的元素(可选的)
举例:names.removeIf(a->a.startsWith("徐")); 删除开头为徐的名字 strings.removeIf(a->a.equals("hello")); 删除hello这个元素。
boolean retainAll(Collection<?> c);只保存参数中元素,如果Collection发生变化返回true(可选的)
void clear();清空集合(可选的)
boolean equals(Object o);于其他集合对比是否相等
int hashCode();返回集合的哈希值:一个用来进行hash操作的整型代号
default Spliterator<E> spliterator()* 1.8新增 并行遍历迭代器 不影响主线程的遍历器
举例:
public static void main(String[] args) {
List<String> list = new LinkedList<>();
for (int i = 0; i < 20000; i++) {
list.add("" + i);
}
list.spliterator().forEachRemaining(e -> System.out.println(e));
System.err.println("end");
}
输出结果:
![]()
default Stream<E> stream()返回一个顺序流
default Stream<E> parallelStream()返回一个并行流
Java8新增Stream:Java8两大特性(一)——Stream
注意:Collection中不包括随机访问所选元素的get()方法,因为Collection包括Set,而Set是自己维护内部顺序的,这使得随机访问没有意义,因此如果想访问Collection中的元素,就必须使用迭代器。
三、可选方法
执行各种添加和移除操作在Collection中都是可选操作。这意味着实现类并不需要为这些方法提供功能定义。如果一个操作时可选的,编译器仍旧会严格要求你只能调用该接口中的方法,并且将Collection当作参数接受的大部分方法只会从该Collection中读取,而Collection的读取方法都是不可的。
为什么要将方法定义为可选呢?原因很简单 就是防止在设计中出现接口爆炸的情况。
未获支持的操作:
最常见的未获支持操作,都是源于背后有固定尺寸的数据结构支持的容器。比如:Arrays.asList()会生成一个List,它是基于固定大小的数组,仅支持那些不会改变数组大小的操作。任何会引起对底层数据结构的尺寸进行修改的方法 都会产生一个UnsupportedOperationException异常,以表示对未获支持操作的调用。应该把Arrays.asList()的结果作为构造器的参数传递给任何Collection(或者使用addAll())来生成可以使用所有方法的普通容器。
四、List的功能方法
排除Collection已包含的方法外还增加了
boolean addAll(int index, Collection<? extends E> c);从索引位置插入参数中元素
default void replaceAll(UnaryOperator<E> operator) *1.8新增 将几何中元素替换成参数中的 举例:
List<Integer> list = new ArrayList();
list.add(1);
list.add(2);
list.replaceAll(a -> a + 1);//将元素更新为+1的元素
default void sort(Comparator<? super E> c) c:自定义排序规则 举例:
List<User> list = new ArrayList();
list.add(u1);
list.add(u2);
list.sort((o1, o2) -> {
Integer age1 = o1.getAge();
Integer age2 = o2.getAge();
return age1.compareTo(age2);
}); //自定义年龄排序
E get(int index); 获取索引位置的元素
E set(int index, E element); 将元素放入索引位置
void add(int index, E element); 在索引位置增加元素
E remove(int index); 移除索引位置的元素
int indexOf(Object o); 返回元素第一次出现时的索引位置
int lastIndexOf(Object o); 返回元素最后一次出现时的索引位置
ListIterator<E> listIterator(); 迭代器
ListIterator<E> listIterator(int index); 从索引位置迭代
List<E> subList(int fromIndex, int toIndex); 按照索引开始结束位置截取
------LinkLIst独有的方法-------
public void addFirst(E e) 在首位增加
public void addLast(E e) 在尾部增加
public E removeFirst(E e) 移除首位
public E removeLast(E e) 移除尾部
这四个方法的合理利用可以利用LinkList实现栈(先进后出)和队列(先进先出)
五、Set和存储顺序
不同的Set实现具不同的行为,并且对于在特定的Set中放置的元素类型也有不同的要求。
Set(interface): 存入Set的每个元素都必须是唯一的,因为set不保存重复元素。加入Set的元素必须定义equals()方法以确保对象的唯一性。Set和Collection有完全一样的接口。Set接口不保证维护元素的次序。
HashSet *:为快速查找而设计的Set。存入HashSet的元素必须定义hashCode()。因为速度所以首选,神秘的排序。
TreeSet:保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。元素必须实现Comparable接口。
LinkedHashSet:具有HashSet的查询速度,且内部使用链表维护元素顺序(插入顺序)。于是在使用迭代器遍历Set时,结果会按元素插入顺序显示,元素也必须实现hashCode()方法。
必须为Set创建equals()方法,只有HashSet和LinkHashSet需要hashCode()方法。但是良好的编程风格应该是重写equals()时跟着重写hashCode()。
如何为Set创建自定义元素类型:
class SetType {
Integer i;
String str;
@Override
public boolean equals(Object o) {
return o instanceof SetType && (i.equals(((SetType) o).i)) && (str.equals(((SetType) o).str));
}
}
class HashType extends SetType {
/**
* 这里涉及到如何重写hashCode:
* 1.取一个初始值17
* 2.对每一个重要字段(equals()方法里面比较的字段)进行一下操作:
* a.filedHashValue = filed.hashCode();
* b.result = result*31+filedHashValue;
*/
@Override
public int hashCode() {
int result = 17;
result = 31 * result + (i == null ? 0 : i.hashCode());
result = 31 * result + (str == null ? 0 : str.hashCode());
return result;
}
}
class TreeType extends SetType implements Comparable<TreeType> {
/**
* compare要指定比较字段
*/
@Override
public int compareTo(TreeType arg) {
return (arg.i < i ? -1 : (arg.i.equals(i) ? 0 : 1));
}
}