一、主题式网络爬虫设计方案
1、主题式网络爬虫名称:爬取排行榜123网站之2019年上海企业前20强。
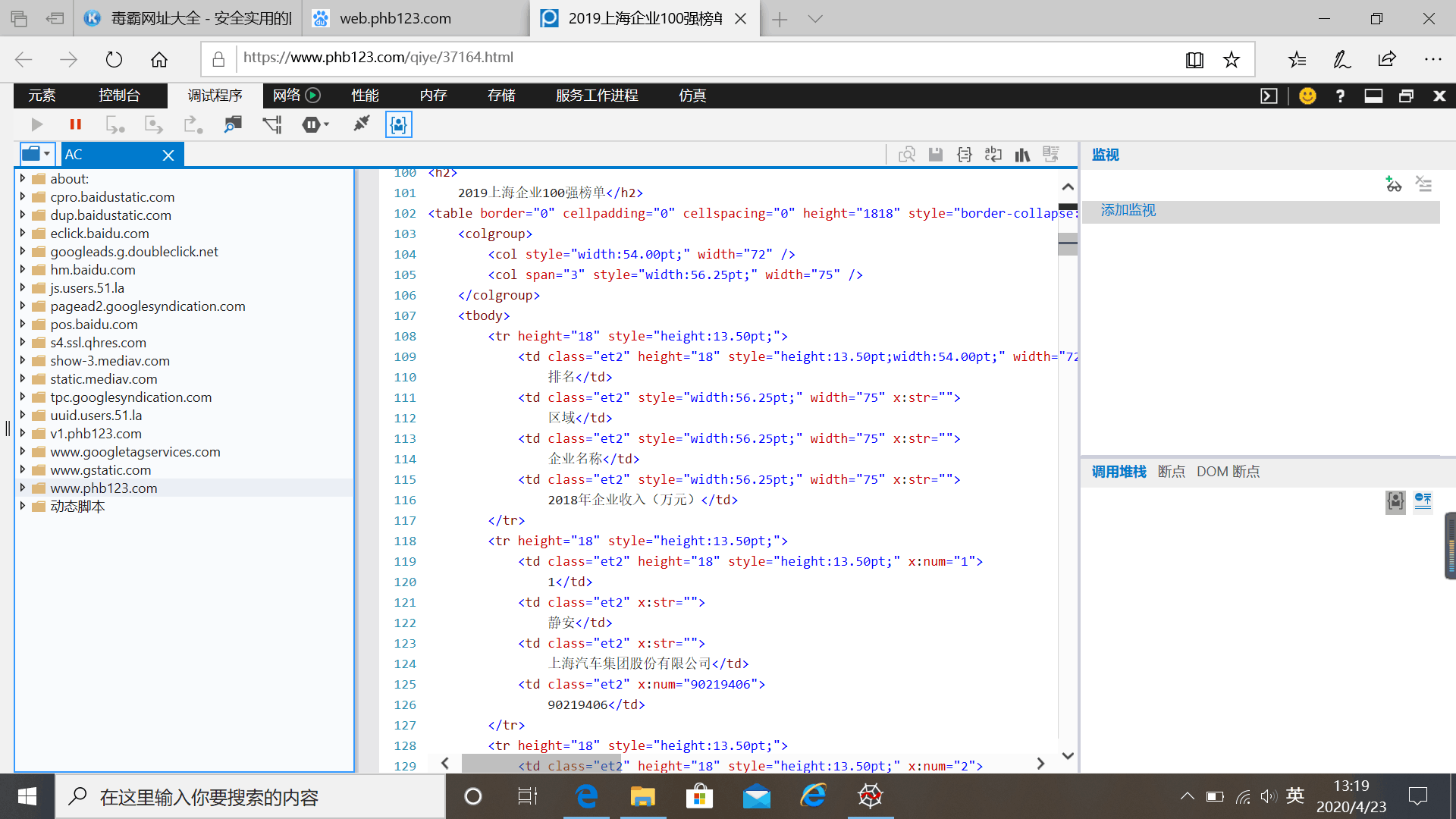
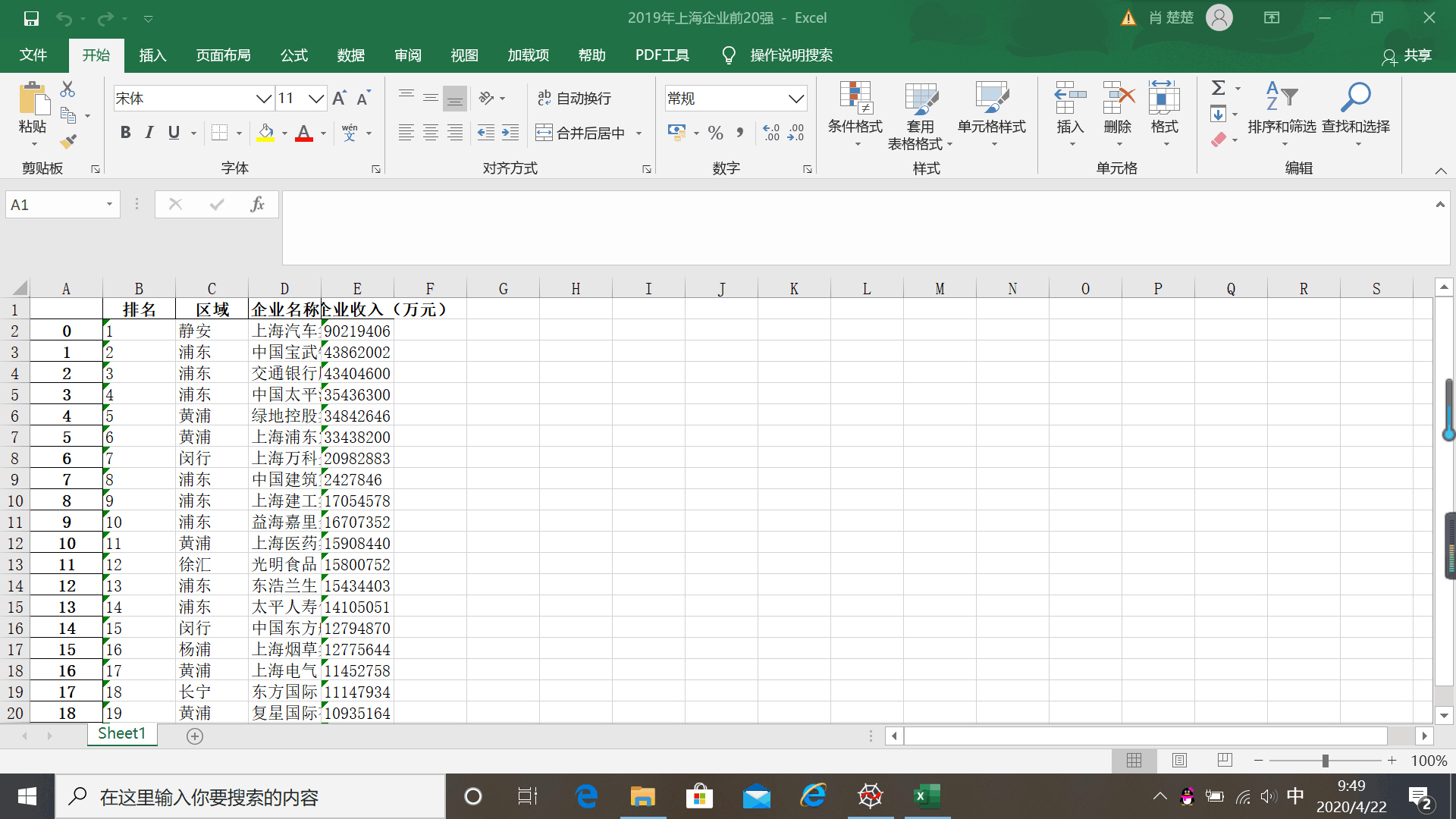
2、主题式网络爬虫爬取的内容:爬取网页2019年上海企业排名,区域,企业名称,2018年企业收入(万元)。
3、主题式网络爬虫设计方案概述:实现思路:选定想要爬取的网页,查看网页源码,找出规律,提取数据,并将数据存入Excel文件中;读取文件数据,对数据进行清洗和处理,进行数据分析与可视化,最后根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,建立回归方程。
技术难点:分析两个变量之间的关系并建立回归方程时,需要删除无效的那一列。
二、主题页面的结构特征分析
三、网络爬虫程序设计
1、数据爬取与采集
import requests from bs4 import BeautifulSoup as bs import pandas as pd class Data: def __init__(self,url): self.url = url self.d = None #把数据下载下来 def fetch_data(self): headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Mobile Safari/537.36' } url = self.url req = requests.get(url,headers=headers) req.encoding = 'utf-8' self.html = req.text return self.html #把数据进行解析,把想要的数据提出来 def parser_data(self): soup = bs(self.html,'html.parser') soup = soup.find_all('tr') import re data = [re.split('\s',i.text) for i in soup] data = [list(filter(lambda x:x!='',i)) for i in data] #把返回的数据变成dataframe格式 d = pd.DataFrame(data[1:]) #取前20行数据 data=data.head(20) print(data) #保存数据至excel文件中 data.to_excel('C:\\P\\2019年上海企业前20强.xlsx')
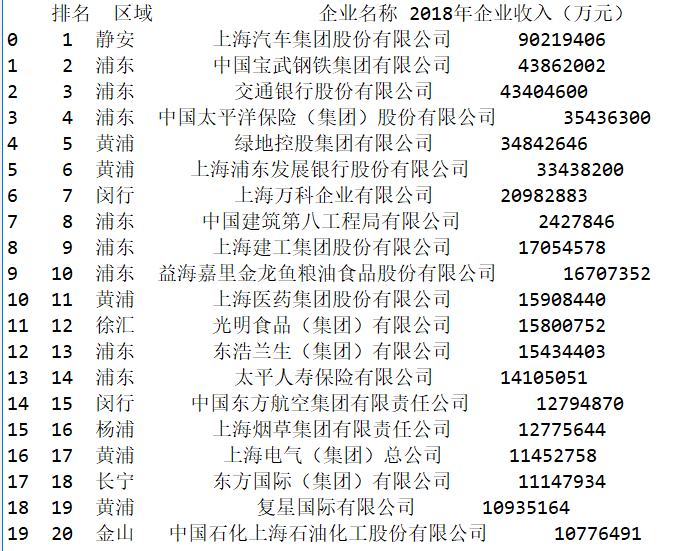

2、对数据进行清洗和处理
#读取文件中的数据 df=pd.read_excel('C:\\P\\2019年上海企业前20强.xlsx') #“区域”列在分析过程中并不需要,需要删除,使用drop方法进行无效列的处理(axis=1)。 data.drop('区域',axis=1,inplace=True) print(data)

#“企业名称”列在分析过程中并不需要,需要删除,使用drop方法进行无效列的处理(axis=1)。 data.drop('企业名称',axis=1,inplace=True) print(data)

#检查是否有重复值 print(data.duplicated())

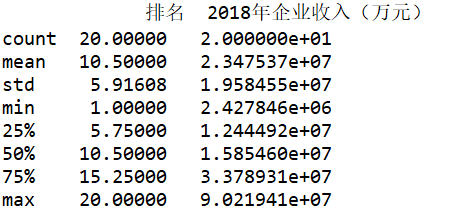
#检查是否有异常值 print(data.describe())
3.数据分析与可视化
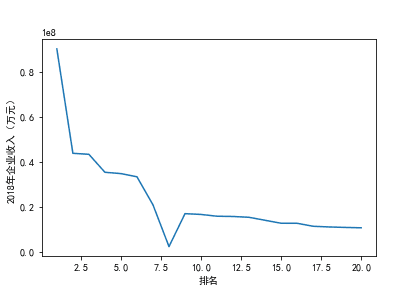
#绘制散点图 import matplotlib as mpl import matplotlib.pyplot as plt #用来正常显示中文标签 mpl.rcParams['font.family'] = 'SimHei' #用来正常显示正负号 mpl.rcParams['axes.unicode_minus'] = False plt.figure(figsize=(8,6)) x=df.loc[:,'排名'] y=df.loc[:,'2018年企业收入(万元)'] size=30 #设置x轴标签 plt.xlabel('排名') #设置y轴标签 plt.ylabel('2018年企业收入(万元)') plt.scatter(x,y,size,color='b') plt.show()

#绘制折线图 def line_diagram(): x=df.loc[:'排名'] y=df.loc[:'2018年企业收入(万元)'] #设置x轴标签 plt.xlabel('排名') #设置y轴标签 plt.ylabel('2018年企业收入(万元)') plt.scatter(x,y) plt.show() line_diagram()
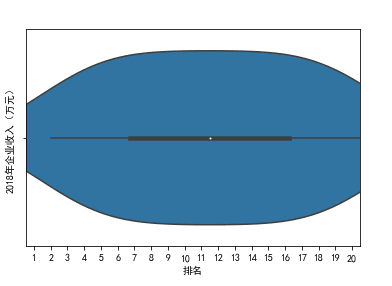
#绘制小提琴图
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.violinplot(df['排名'])
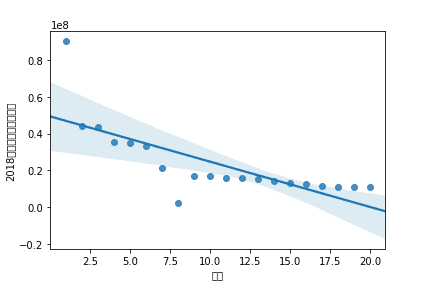
#查找回归系数并绘制回归图 import pandas as pd import numpy as np import matplotlib.pyplot as plt #读取文件数据 df=pd.read_excel('C:\\P\\2019年上海企业前20强.xlsx') from sklearn.linear_model import LinearRegression #删除无效行 X=df.drop("企业名称",axis=1) predict_model=LinearRegression() predict_model.fit(X,df['2018年企业收入(万元)']) #查找回归系数 print("回归系数为:",predict_model.coef_) a=sns.regplot(x='排名',y='2018年企业收入(万元)',data=df) print(a)
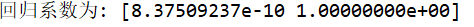
4、数据持久化
5、代码汇总
import requests from bs4 import BeautifulSoup as bs import pandas as pd class Data: def __init__(self,url): self.url = url self.d = None #把数据下载下来 def fetch_data(self): headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Mobile Safari/537.36' } url = self.url req = requests.get(url,headers=headers) req.encoding = 'utf-8' self.html = req.text return self.html #把数据进行解析,把想要的数据提出来 def parser_data(self): soup = bs(self.html,'html.parser') soup = soup.find_all('tr') import re data = [re.split('\s',i.text) for i in soup] data = [list(filter(lambda x:x!='',i)) for i in data] #把返回的数据变成dataframe格式 d = pd.DataFrame(data[1:]) #取前20行数据 data=data.head(20) print(data) #保存数据至excel文件中 data.to_excel('C:\\P\\2019年上海企业前20强.xlsx') #读取文件中的数据 df=pd.read_excel('C:\\P\\2019年上海企业前20强.xlsx') #“区域”列在分析过程中并不需要,需要删除,使用drop方法进行无效列的处理(axis=1)。 data.drop('区域',axis=1,inplace=True) print(data) #“企业名称”列在分析过程中并不需要,需要删除,使用drop方法进行无效列的处理(axis=1)。 data.drop('企业名称',axis=1,inplace=True) print(data) #检查是否有重复值 print(data.duplicated()) #检查是否有异常值 print(data.describe()) #绘制散点图 import matplotlib as mpl import matplotlib.pyplot as plt #用来正常显示中文标签 mpl.rcParams['font.family'] = 'SimHei' #用来正常显示正负号 mpl.rcParams['axes.unicode_minus'] = False plt.figure(figsize=(8,6)) x=df.loc[:,'排名'] y=df.loc[:,'2018年企业收入(万元)'] size=30 #设置x轴标签 plt.xlabel('排名') #设置y轴标签 plt.ylabel('2018年企业收入(万元)') plt.scatter(x,y,size,color='b') plt.show() #绘制折线图 def line_diagram(): x=df.loc[:'排名'] y=df.loc[:'2018年企业收入(万元)'] #设置x轴标签 plt.xlabel('排名') #设置y轴标签 plt.ylabel('2018年企业收入(万元)') plt.scatter(x,y) plt.show() line_diagram() #绘制小提琴图 import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns sns.violinplot(df['排名']) #查找回归系数并绘制回归图 import pandas as pd import numpy as np import matplotlib.pyplot as plt #读取文件数据 df=pd.read_excel('C:\\P\\2019年上海企业前20强.xlsx') from sklearn.linear_model import LinearRegression #删除无效行 X=df.drop("企业名称",axis=1) predict_model=LinearRegression() predict_model.fit(X,df['2018年企业收入(万元)']) #查找回归系数 print("回归系数为:",predict_model.coef_) a=sns.regplot(x='排名',y='2018年企业收入(万元)',data=df) print(a)
四、结论
1、利用好python网络爬虫我们可以很好地提取所需的网站信息,进行数据可视化使我们更清晰明了的看清楚所提取数据的特点。
2、小结:在python网络爬虫程序设计中,我通过书本、老师的教学视频以及知乎等寻找解决此次任务中不懂问题的方法,又掌握了一些新知识,也深刻意识到了自己的不足。进行数据可视化绘图时,我发现纵坐标都是小数,但纵坐标上方出现了“1e8”,经过百度查找得知“1e8“等于10的八次方,这是我学习到的一个新知识。此次网络爬虫程序设计,我收获了许多,希望在今后的日子里自己的编程能力可以有所提高。