一、分布式系统
由多个计算机组成解决同一个问题的系统,提高业务的并发,解决高并发问题。
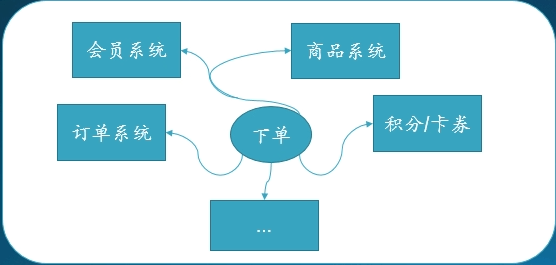
二、分布式环境下常见问题
1.节点失效
2.配置信息的创建及更新
3.分布式锁
三、Zookeeper
1.定义
Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。所谓的分布式协调服务,就是在集群的节点中进行可靠的消息传递,来协调集群的工作。
Zookeeper之所以能够实现分布式协调服务,靠的就是它能够保证分布式数据一致性。所谓的分布式数据一致性,指的就是可以在集群中保证数据传递的一致性。
Zookeeper能够提供的分布式协调服务包括:数据发布订阅、负载均衡、命名服务、分布式协调/通知、集群管理、分布式锁、分布式队列等功能
2.应用场景
配置中心
负载均衡
统一命名服务
共享锁
四、Zookeeper的特点
Zookeeper工作在集群中,对集群提供分布式协调服务,它提供的分布式协调服务具有如下的特点:
- 顺序一致性
从同一个客户端发起的事务请求,最终将会严格按照其发起顺序被应用到zookeeper中
- 原子性
所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的
- 单一视图
无论客户端连接的是哪个zookeeper服务器,其看到的服务端数据模型都是一致的。
- 可靠性
一旦服务端成功的应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直保留下来,除非有另一个事务又对其进行了改变。
- 实时性
zookeeper并不是一种强一致性,只能保证顺序一致性和最终一致性,只能称为达到了伪实时性。
五、基本概念
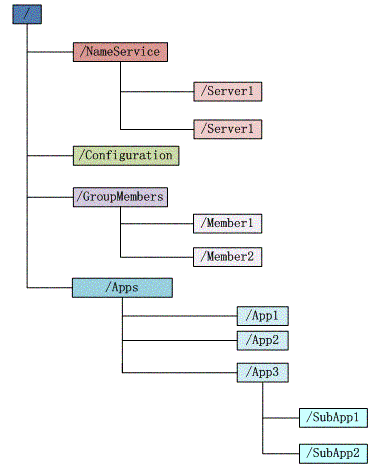
1.数据模型
zookeepei中可以保存数据,正是利用zookeeper可以保存数据这一特点,我们的集群通过在zookeeper里存取数据来进行消息的传递。
zookeeper中保存数据的结构非常类似于文件系统。都是由节点组成的树形结构。不同的是文件系统是由文件夹和文件来组成的树,而zookeeper中是由znode来组成的树。
每一个ZNODE里都可以存放一段数据,znode下还可以挂载零个或多个子znode节点,从而组成一个树形结构。(结构如下所示)
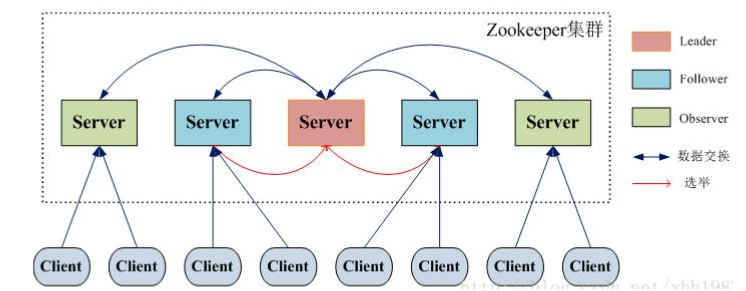
2.集群角色
(1)Leader:接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部数据交换(同步)
(2)Follower:直接为客户端服务并参与提案的投票,同时与Leader进行数据交换(同步)
(3)Observer:直接为客户端服务但不参与提案的投票,同时也与Leader进行数据交换(同步)
3.会话
4.版本号
5.Acl权限控制
六、单机部署
1.下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/,通过
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/zookeeper-3.4.9.tar.gz
下载到Linux
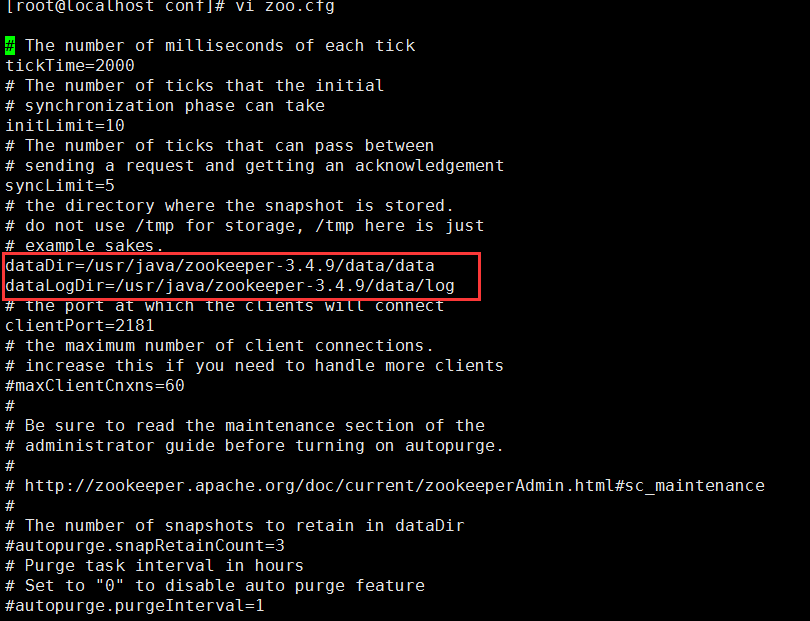
2.将/usr/java/zookeeper/server1/zookeeper-3.4.9/conf下的zoo_sample.cfg文件复制为zoo.cfg,修改zoo.cfg,修改dataDir( 数据快照存储目录) 和 增加dataLogDir(保存Log的目录)
3.通过bin/zkServer.sh start|stop|restart|status 启动、停止、重启、查询状态

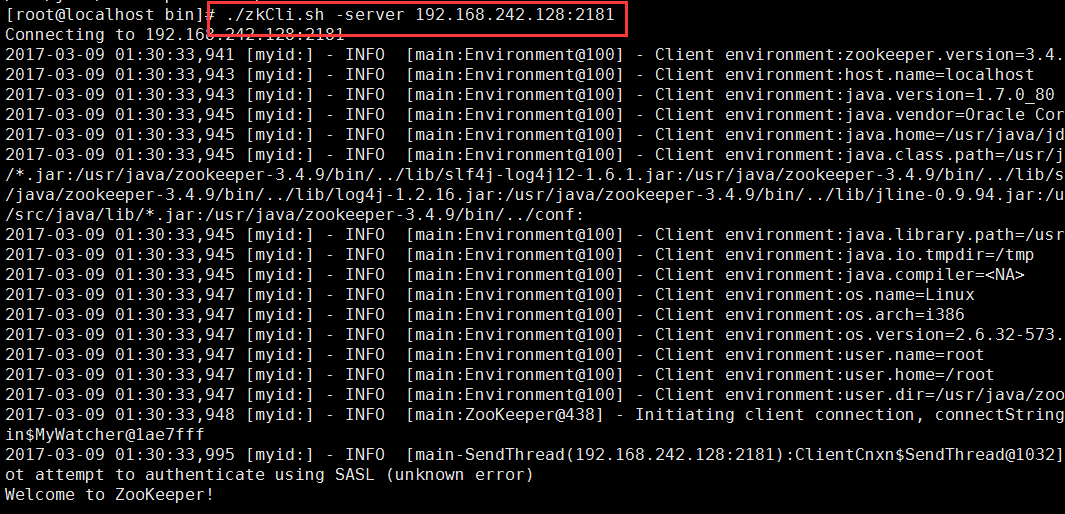
4.通过bin/zkCli.sh [-timeout 0 -r] -server host:port(host即IP地址,peot即端口号)
七、集群部署(这里使用伪集群)
1.在/usr/java中新建zookeeper目录,然后在zookeeper目录下新建 server1,server2,server3目录
mkdir /usr/java/zookeeper/server1 mkdir /usr/java/zookeeper/server1 mkdir /usr/java/zookeeper/server1
2.将下载的tar文件复制到新建的server1,server2,server3中,然后解压到这三个目录下
3.修改zoo.cfg文件
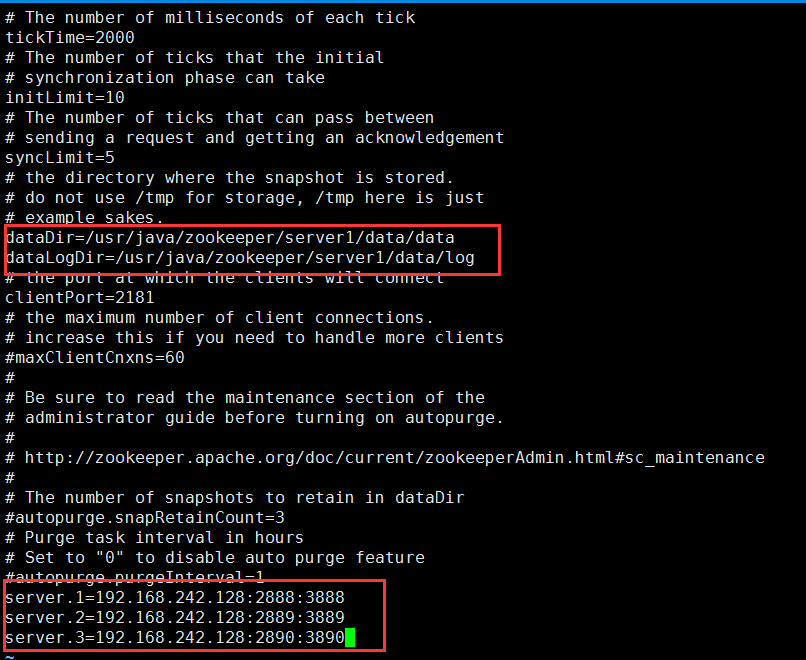
第一个端口号是Leader和Follower之间通讯的端口号,即数据同步的端口号,第二个端口号是Leader选举的端口号
4.分别复制zoo.cfg到server2/zookeeper-3.4.9/conf 和 server3/zookeeper-3.4.9/conf下
5.修改server2/zookeeper-3.4.9/conf下的zoo.cfg,只修改dataDir、dataLogDir和clientPort即可,下图server点后面的数字就是myid,即进程号,用于选举
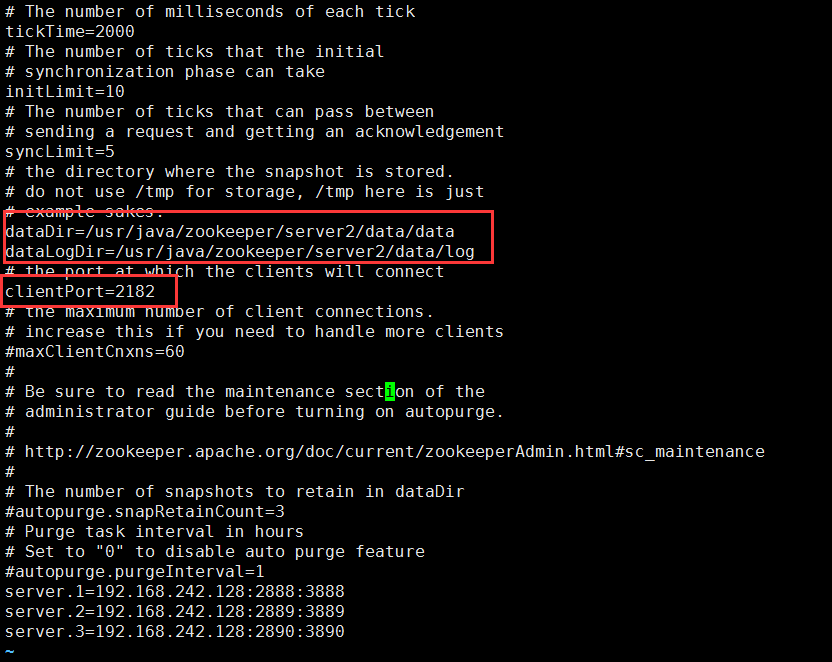
6.同理,修改server3/zookeeper-3.4.9/conf下的zoo.cfg,将dataDir改为server3下面的,将dataLogDir改为server3下的,将clientPort改为2183
7.在server1,server2,server3中新建data目录,并且在data目录下新建data和log目录
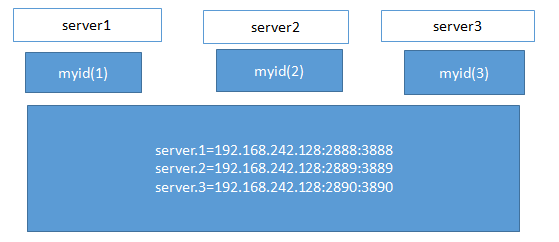
8.在server1/data/data下编辑myid文件,即 vi myid,在里面写1,
在server2/data/data下编辑myid文件,即 vi myid,在里面写2,
在server3/data/data下编辑myid文件,即 vi myid,在里面写3,
这里对应上图中server点后面的数字,即进程号。
9.启动server1,
cd /usr/java/zookeeper/server1/zookeeper-3.4.9/bin
./zkServer.sh start
,启动成功后,然后通过客户端连接:./zkCli.sh -server localhost:2181,可以看到如下:
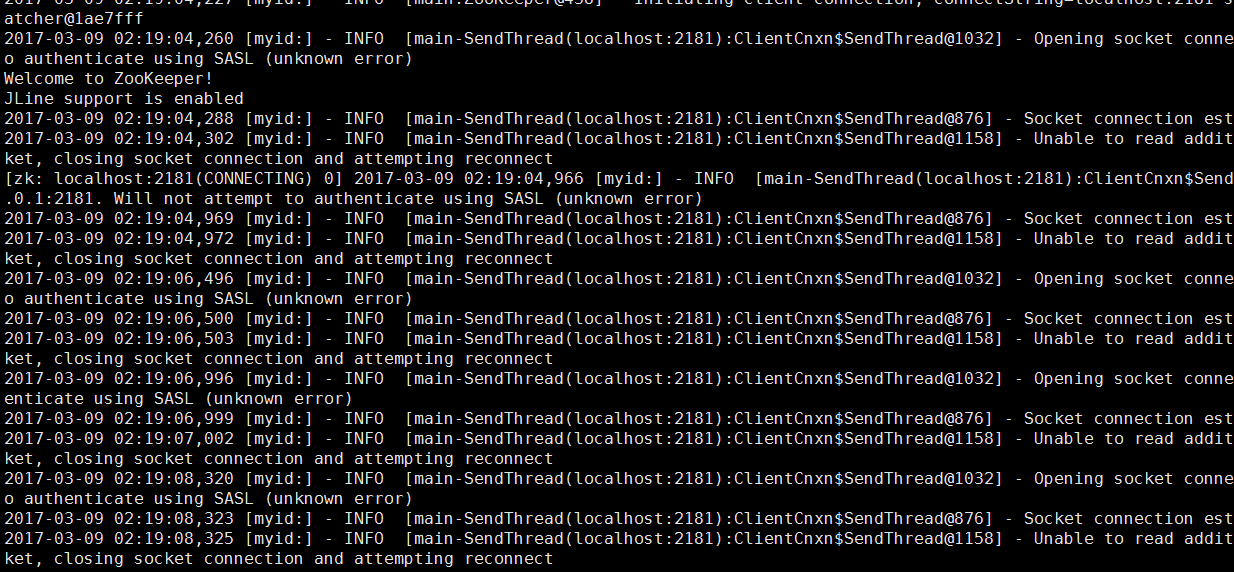
说明错误了。在集群中,必须有一半的服务正常,客户端才可以正常连接。
10.先关闭客户端,然后启动server2,再重新连接
cd /usr/java/zookeeper/server2/zookeeper-3.4.9/bin (进入server2的目录) ./zkServer start (启动server2)
./zkCli.sh -server localhost:2181(客气客户端,连接服务端)
可以看到如下,则说明成功。
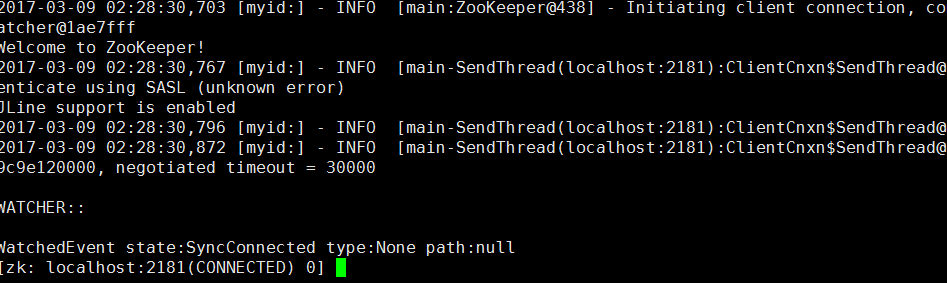
11.再启动server3,用客户端测试连接。OK,则集群成功。
12.查看哪一个是Leader,哪一个是Follower,进入zookeeper的bin目录下,输入zkServer.sh status即可查看

