Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
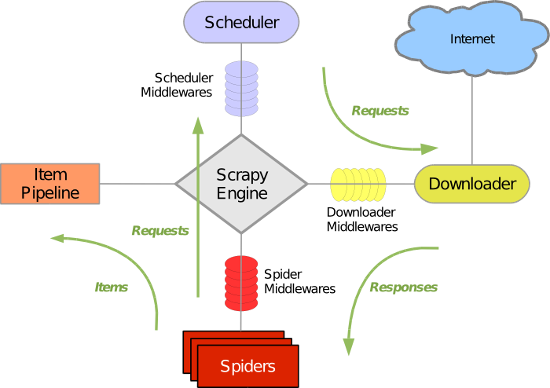
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
windows平台需要依赖pywin32
一、安装
1、安装pywin32
地址:https://nchc.dl.sourceforge.net/project/pywin32/pywin32/Build%20221/pywin32-221.win-amd64-py3.6.exe。
下载完毕之后,点击安装即可
2、Twisted
地址:https://download.lfd.uci.edu/pythonlibs/rqr3k8is/Twisted-17.9.0-cp36-cp36m-win_amd64.whl
cp后面是python版本,amd64代表64位
安装:
pip install C:UsersCRDownloadsTwisted-17.5.0-cp36-cp36m-win_amd64.whl
3、安装Scrapy
pip install scrapy
二、基本使用
1、创建项目
运行命令:
scrapy statproject spide1
自动创建目录:
1 project_name/ 2 scrapy.cfg 3 project_name/ 4 __init__.py 5 items.py 6 pipelines.py 7 settings.py 8 spiders/ 9 __init__.py
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2、编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
1 #!/usr/bin/ python 2 # _*_ coding:utf-8 _*_ 3 4 import scrapy 5 6 class XiaohuaSpider(scrapy.spiders.Spider): 7 name = "xiaohuar" #APP名字 8 start_urls = [ 9 "http://www.xiaohuar.com/hua/", 10 ] 11 12 def parse(self, response): 13 current_url = response.url 14 body = response.body 15 unicode_body = response.body_as_unicode() 16 print(unicode_body)
3、运行
进入project_name目录,运行命令
scrapy crawl xiaohuar --nolog
4、递归访问
以上的爬虫仅仅是爬去初始页,而我们爬虫是需要源源不断的执行下去,直到所有的网页被执行完毕
1 import scrapy 2 import urllib.request as req 3 import os 4 5 class XiaohuaSpider(scrapy.spiders.Spider): 6 name = "xiaohuar" #APP名字 7 start_urls = [ 8 "http://www.xiaohuar.com/hua/", 9 ] 10 11 def parse(self, response): 12 # current_url = response.url 13 # body = response.body 14 # unicode_body = response.body_as_unicode() 15 # print(unicode_body) 16 current_dir = os.path.dirname(os.path.dirname(__file__)) 17 # if os.path.exists(os.path.join(current_dir,'pic')): 18 # pass 19 # else: 20 # current_dir = os.mkdir(os.path.join(current_dir,'pic')) 21 from scrapy.selector import HtmlXPathSelector 22 hxs = HtmlXPathSelector(response) 23 #//div 代表找到所有的div /div 从根目录开始找 @class="item_list infinite_scrol 代表class为item_list infinite_scroll的div
#/div代表前一个div下面的孩子,即子div 24 #items = hxs.select('//div[@class="item_list infinite_scroll"]/div//img/@src').extract() 25 hxs.select('//div[@class="item_list infinite_scroll"]/div[1]').extract() #获取第一个元素 26 items = hxs.select('//div[@class="item_list infinite_scroll"]/div') 27 for i in range(len(items)): 28 srcs = hxs.select( '//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract() 29 names = hxs.select( '//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract() 30 schools = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract() 31 if srcs and names: 32 ab_src = "http://www.xiaohuar.com" + srcs[0] 33 file_name = "%s_%s.jpg" % (schools[0], names[0]) 34 file_path = os.path.join(current_dir,file_name) 35 #print(file_path) 36 req.urlretrieve(ab_src, file_path)
以上代码将符合规则的页面中的图片保存在指定目录,并且在HTML源码中找到所有的其他 a 标签的href属性,从而“递归”的执行下去,直到所有的页面都被访问过为止。