python基础复习(一)
一、编程语言的分类
1.1机器语言:
用二进制代码0和1描述的指令称为机器指令,由于计算机内部是基于二进制指令工作的,所以机器语言是直接控制计算机硬件。
用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码以及代码的含义,然后在编写程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。这是一件十分繁琐的工作。编写程序花费的时间往往是实际运行时间的几十倍或几百倍。而且,编出的程序全是些0和1的指令代码,直观性差,不便阅读和书写,还容易出错,且依赖于具体的计算机硬件型号,局限性很大。除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。
机器语言是被微处理器理解和使用的,存在有多至100000种机器语言的指令,下述是一些简单示例
#指令部份的示例
0000 代表 加载(LOAD)
0001 代表 存储(STORE)
...
#暂存器部份的示例
0000 代表暂存器 A
0001 代表暂存器 B
...
#存储器部份的示例
000000000000 代表地址为 0 的存储器
000000000001 代表地址为 1 的存储器
000000010000 代表地址为 16 的存储器
100000000000 代表地址为 2^11 的存储器
#集成示例
0000,0000,000000010000 代表 LOAD A, 16
0000,0001,000000000001 代表 LOAD B, 1
0001,0001,000000010000 代表 STORE B, 16
0001,0001,000000000001 代表 STORE B, 1[1]
机械语言的优点以及缺点:
优点:编写的程序可以呗计算机无障碍理解,直接运行,执行效率高。
缺点:编写复杂,不适合程序员编程操作,开发效率极低,不符合人的编程方式不便于编程交流,且其更加依赖具
体的硬件,跨平台性差。
1.2汇编语言
汇编语言讲英文便签代表一组二进制指令,这大大的方便了程序员的编译操作,能够更好的理解以及编译,但汇编
语言的本质依旧是直接操作硬件,与计算机硬件贴近且依旧属于比较底层的语言
汇编语言的实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用了英文缩写的标识符,更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。汇编程序的每一句指令只能对应实际操作过程中的一个很细微的动作。例如移动、自增,因此汇编源程序一般比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识,但汇编语言的优点也是显而易见的,用汇编语言所能完成的操作不是一般高级语言所能够实现的,而且源程序经汇编生成的可执行文件不仅比较小,而且执行速度很快。
汇编的hello world,打印一句hello world, 需要写十多行,如下
; hello.asm
section .data ; 数据段声明
msg db "Hello, world!", 0xA ; 要输出的字符串
len equ $ - msg ; 字串长度
section .text ; 代码段声明
global _start ; 指定入口函数
_start: ; 在屏幕上显示一个字符串
mov edx, len ; 参数三:字符串长度
mov ecx, msg ; 参数二:要显示的字符串
mov ebx, 1 ; 参数一:文件描述符(stdout)
mov eax, 4 ; 系统调用号(sys_write)
int 0x80 ; 调用内核功能
; 退出程序
mov ebx, 0 ; 参数一:退出代码
mov eax, 1 ; 系统调用号(sys_exit)
int 0x80 ; 调用内核功能
汇编语言的优点以及缺点:
优点:相对于机器语言汇编语言是一种进步,他依靠英文标签来代表二进制指令,这使得他的开发效率有所提高,
但执行效率依旧很低。
缺点:依旧是直接操作硬件,虽然比机器语言相比更便捷简单些,但他的开发效率依旧很低,两者之间基本较为持
平,与机械器言一样跨平台性差,开发效率低且都依赖于硬件
1.3高级语言:
高级语言是直接与操作系统打交道的,程序员开发时无需考虑硬件细节,因此高级语言他的开发效率极高,语言更
加容易理解和使用。但在使用高级语言是往往需要一个翻译才能使得计算机理解(如python解释器)这使得高级
语言的执行效率低于低级语言
高级语言分为两种:一种是编译型语言,另一种是解释行语言
编译型:
讲程序的代码编译成计算机能识别的二进制指令,然后操作系统再根据这些二进制指令去操作硬件
优点:
编译一次之后就可以拿着结果重复运行,而无需再次翻译,执行效率高于解释型
缺点:
编译型代码是针对某一个平台翻译的,当前平台翻译的结果无法拿到另外一个平台使用,即无法跨平台
解释型:
解释型他需要一个解释器,解释器会读取程序的代码然后一遍翻译一遍执行
优点:
代码运行是依赖于解释器,不同平台有对应版本的解释器,所以代码是可以跨平台运行
缺点:
每次执行都需要翻译,执行效率低于编译型
需要理解记忆
执行效率:机器语言>汇编语言>高级语言(编译型>解释型)
开发效率:机器语言<汇编语言<高级语言(编译型<解释型)
跨平台性:解释型具有极强的跨平台型
二、变量
1.1什么是变量:
变量是指可以变化的量,而量指的就是事物的状态
1.2为什么要有变量:
变量的存在是为了记录某种事物的状态,程序置形的本质就是一系列状态的变化,我们可以通过变量来反映程序执
行时的状态以及状态的变化
1.3怎么使用变量:
定义变量:
name = 'Jason' # 记下人的名字为'Jason'
sex = '男' # 记下人的性别为男性
age = 18 # 记下人的年龄为18岁
salary = 30000.1 # 记下人的薪资为30000.1元
我们在使用变量时通过变量名就可以直接引用到变量的值再通过使用print()我们就可以讲变量的值打印出来
命名变量:
命名变量的时候我们遵循一定的规范
1. 变量名只能是 字母、数字或下划线的任意组合
2. 变量名的第一个字符不能是数字
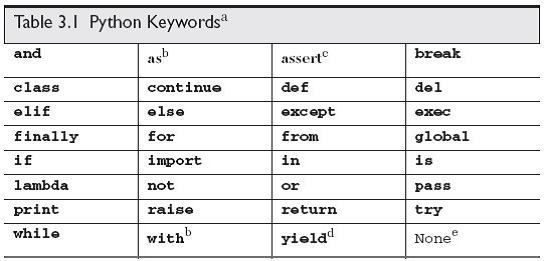
3. 关键字不能声明为变量名,常用关键字如下
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
# 错误示范如下:
*a=123
$b=456
c$=789
2_name='lili'
123='lili'
and=123
年龄=18 # 强烈建议不要使用中文命名
# 正确示范如下
age_of_jason=31
page1='首页'
_class='终极一班'
#命名风格
风格一:驼峰体
AgeOfTony = 56
NumberOfStudents = 80
风格二:纯小写下划线(在python中,变量名的命名推荐使用该风格)
age_of_tony = 56
number_of_students = 80
变量值的特点:
#1、id
反应的是变量在内存中的唯一编号,内存地址不同id肯定不同
#2、type
变量值的类型
#3、value
变量值
查看变量值的方式:
>>> x='Info Tony:18'
>>> id(x),type(x),x
4376607152,<class 'str'>,'Info Tony:18'
三、基本数据类型
1.1什么是数据以及为何要有多种类型的数据
数据是我们在代码操作是所定义的一些变量或者常量,比如m=18 则18这个数就是我们所保存的数据。
变量是来反应/保持状态以及这个状态的变化,对于不同的状态有不同的数据类型去表示
概括地说,编程语言的划分方式有以下三种
1、编译型or解释型
2、强类型or弱类型
2.1 强类型语言: 数据类型不可以被忽略的语言
即变量的数据类型一旦被定义,那就不会再改变,除非进行强转。
在python中,例如:name = 'egon',这个变量name在被赋值的那一刻,数据类型就被确定死了,是字符型,值
为'egon'。
2.2 弱类型语言:数据类型可以被忽略的语言
比如linux中的shell中定义一个变量,是随着调用方式的不同,数据类型可随意切换的那种。
3、动态型or静态型
3.1 动态语言 :运行时才进行数据类型检查
即在变量赋值时,就确定了变量的数据类型,不用事先给变量指定数据类型
3.2 静态语言:需要事先给变量进行数据类型定义
所以综上所述,Python是一门解释型的强类型动态语言
了解:Python是一门解释型的强类型动态语言
1.2数字类型
type( ) :
type():
查看数字类型的方法
int(整型):
定义:age=10 #age=int(10)
<class 'int'>
用于标识:年龄,等级,身份证号,qq号,个数等数字为整的数字类型
long(长整型):
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们
使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字
母L也不会导致严重后果了。
注意:在Python3里不再有long类型了,全都是int
float(浮点型):
定义:salary=3.1 #salary=float(3.1)
<class 'float'>
用于标识:工资,身高,体重等带有小数的数字类型
字符串 :
在python中,加了引号的字符就是字符串类型,python并没有字符类型。
name = 'yan'
name= "yan"
name = '''
abc
def
'''
<class 'str'>
用来标识一些具有描述性的内容,姓名,班名,国籍
那单引号、双引号、多引号的使用是没有区别的
只有下面这种情况 你需要考虑单双的配合
msg = "My name is yan , I'm 18 years old!"
列表:
在[]内用逗号分隔,可以存放n个任意类型的值
定义:list = [1, 2, 3, 4, 5, 6]
用于标识:储存多个值得情况
字典:
在{}内用逗号分隔,可以存放多个key:value的值,value可以是任意类型
dlct={'name':'yan','age':21}
用于标识:存储多个值的情况,每个值都有唯一一个对应的key,可以更为方便高效地取值
布尔:
布尔值,一个True一个False
>>> a=3
>>> b=5
>>>
>>> a > b #不成立就是False,即假
False
>>>
>>> a < b #成立就是True, 即真
True
接下来就可以根据条件结果来干不同的事情了:
if a > b
print(a is bigger than b )
else
print(a is smaller than b )
上面是伪代码,但意味着, 计算机已经可以像人脑一样根据判断结果不同,来执行不同的动作。
*****
所有数据类型都自带布尔值
1、None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False
2、其余均为真
格式化输出:
占位符:%s、%d
%s字符串占位符:可以接收字符串,也可接收数字
print('My name is %s,my age is %s' %('egon',18))
%d数字占位符:只能接收数字
print('My name is %s,my age is %d' %('egon',18))
print('My name is %s,my age is %d' %('egon','18')) #报错
接收用户输入,打印成指定格式
name=input('your name: ')
age=input('your age: ') #用户输入18,会存成字符串18,无法传给%d
print('My name is %s,my age is %s' %(name,age))
注意:
print('My name is %s,my age is %d' %(name,age)) #age为字符串类型,无法传给%d,所以会报错
数据类型总结
按存储空间的占用分(从低到高)
数字
字符串
集合:无序,即无序存索引相关信息
元组:有序,需要存索引相关信息,不可变
列表:有序,需要存索引相关信息,可变,需要处理数据的增删改
字典:无序,需要存key与value映射的相关信息,可变,需要处理数据的增删改
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
|---|---|
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
|---|---|
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
|---|---|
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
四、基本运算符:
算数运算符:

比较运算符:

赋值运算符:

逻辑运算符:

1、三者的优先级关系:not>and>or,同一优先级默认从左往右计算。
>>> 3>4 and 4>3 or 1==3 and 'x' == 'x' or 3 >3
False
2、最好使用括号来区别优先级,其实意义与上面的一样
'''
原理为:
(1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割
(2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可
(3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算
'''
>>> (3>4 and 4>3) or (1==3 and 'x' == 'x') or 3 >3
False
3、短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
我们用括号来明确一下优先级
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
短路: 0 '' 'abc'
假 假 真
返回: 'abc'
4、短路运算面试题:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
在python中 Python把0、空字符串''和None看成 False,其他数值和非空字符串都看成 True
and 两边都成立则输出True 不成立则输出False
or 任意一边成立则输出True 不成立则输出False
身份运算:
is 和 ==
is 比较的是两边的id
== 比较的是两边的值
>>>a = b = 3
>>>c = 1
>>>a is c
False
>>>a is b
True
>>>id(a)
1611030816
>>>id(b)
1611030816
>>>id(c)
1611030752
>>>a == c
False
五、流程控制:
if...else:
import random
computer = random.randint(1, 100)
while True:
number = int(input("请输入100以内的整数:"))
if (number > computer):
print("大了")
elif (number < computer):
print("小了")
else:
print("恭喜你赢了")
break
通过 if...else 语句实现猜数字小游戏
score = input('>>: ')
score = float(score)
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('普通')
else:
print('很差')
通过 if...else 语句实现判断成绩
while循环:
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行,执行完毕后再次循环,重新判断条件。。。
# 如果条件为假,那么循环体不执行,循环终止
#打印0-10
count=0
while count <= 10:
print('loop',count)
count+=1
#打印0-10之间的偶数
count=0
while count <= 10:
if count%2 == 0:
print('loop',count)
count+=1
#打印0-10之间的奇数
count=0
while count <= 10:
if count%2 == 1:
print('loop',count)
count+=1
死循环:
import time
num=0
while True:
print('count',num)
time.sleep(1)
num+=1
死循环会无限循环且会增加内存负担
例题:
name='123'
password='123'
while True:
inp_name=input('用户名: ')
inp_pwd=input('密码: ')
if inp_name == name and inp_pwd == password:
while True:
cmd=input('>>: ')
if not cmd:continue
if cmd == 'quit':
break
print('run <%s>' %cmd)
else:
print('用户名或密码错误')
continue
break
break与continue
break用于退出本层循环
while True:
print "123"
break
print "456"
continue用于退出本次循环,继续下一次循环
while True:
print "123"
continue
print "456"
for循环:
#分析
'''
#max_level=5
* #current_level=1,空格数=4,*号数=1
*** #current_level=2,空格数=3,*号数=3
***** #current_level=3,空格数=2,*号数=5
******* #current_level=4,空格数=1,*号数=7
********* #current_level=5,空格数=0,*号数=9
#数学表达式
空格数=max_level-current_level
*号数=2*current_level-1
'''
#实现
max_level=5
for current_level in range(1,max_level+1):
for i in range(max_level-current_level):
print(' ',end='') #在一行中连续打印多个空格
for j in range(2*current_level-1):
print('*',end='') #在一行中连续打印多个空格
print()
for循环打印金字塔
扩展内容:
一.语句和语法
- #:注释
- :转译回车,继续上一行,在一行语句较长的情况下可以使用其来切分成多行,因其可读性差所以不建议使用
- ;:将两个语句连接到一行,可读性差,不建议使用
- ::将代码的头和体分开
- 语句(代码块)用缩进方式体现不同的代码级别,建议采用4个空格(不要使用tab)
- python文件以模块的方式组织,编写一个.py结尾的文件实际上就写了一个模块
二.变量定义与赋值
- a=1:1为内存变量存放于内存中,a为变量的引用,python为动态语言,变量及其类型均无需事先声明类型
- 与c的区别:a=1无返回值
注:
- c语言变量声明必须位于代码最开始,而且要在所有语句之前
- c++,java可以随时随地声明变量,但是必须声明变量名字和类型
- python也可以随时随地声明变量,但是变量在被定义时,解释器会根据等式右侧的值来决定其类型
- 变量必须先赋值,才可使用
三.内存管理
内存管理:
- 变量无须指定类型
- 程序员无须关心内存管理
- 变量会被自动回收
- del能够直接释放内存对象(减少对象的引用计数)
引用计数:
- 增加引用计数
- 对象被创建并将其引用赋值给变量,引用计数加1(例a=1)
- 同一个对象的引用又赋值给其它变量,引用计数加1(例b=a)
- 对象作为参数被函数调用,引用计数加1(例int(a)
- 对象成为容器对象中的一个元素,引用计数加1(例list_test=['alex','z',a])
- 减少引用计数
- a作为被函数调用的参数,在函数运行结束后,包括a在内的所有局部变量均会被销毁,引用计数减1
- 变量被赋值给另外一个对象,原对象引用计数减1(例b=2,1这一内存对象的引用只剩a)
- 使用del删除对象的引用,引用计数减1(例del a)
- a作为容器list_test中的一个元素,被清除,引用计数减少(例list_test.remove(a))
- 容器本身被销毁(例del list_test)
注意:python内存回收交给一段独立的代码即垃圾回收器(包含引用计数器和循环垃圾收集器),引用计数在归零时并不会立即清除(可能有循环调用)
不必纠结循环引用收集,只需记住垃圾回收器帮你自动清理内存。
简单例子
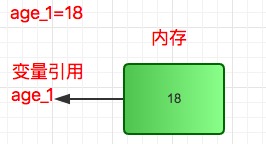
x=1 #创建内存变量1,将变量1的引用传给x,此刻1的引用计数为1
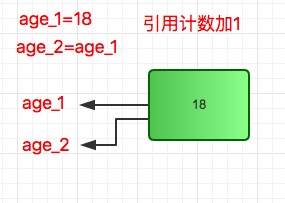
y=x #1的引用计数增加到2
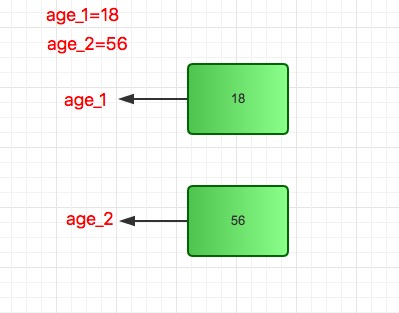
y=2 #创建新的内存变量2,将变量2的引用传给y,原本指向1的y,此刻给了2,所以1的引用计数减少到了1
del x #删除了内存对象1的引用x,此刻1再无引用,此刻它就成了python解释器回收的目标
四.python对象
python中使用对象模型来存储数据,用来生成数据类型的工厂函数本质上是类,新建数据的结果本质是实例化一个对象
对象有三种特性
- 身份:内存地址,可以用id()确认,id相同的就是同一个对象
- 类型:可以用type()查看,返回值的type也是对象
- 值
五.标识符
定义:允许作为名字的有效字符串集合
- 名字必须有实际意义,可读性好
- 首字母必须是字母或下划线(_)
- 剩下的字符可以是字母和数字或者下划线
- 大小写敏感
- 两种风格:conn_obj或ConnObj
- 不能使用关键字,不能使用内建
关键字表:
内建:由解释器自动导入(提供基本功能),可以看作全局变量,
六.专用下划线标识符
- _xxx:不能用from module import *导入
- xxx:系统定义名字
- __xxx:类中私有变量
下划线对于解释器来说有特殊意义,而且是内建标识符所使用符号,不建议自定义变量以下划线开头
但是如果是类中的私有变量,__xxx将会是一个好习惯
补充:
-
系统变量__name__会根据python文件被加载方式的不同得出不同的值
- python文件被当作模块导入:name=模块名或者文件名
- python文件被执行:name='main'
-
在我们使用python编写一个软件时,应该只有一个主程序中包含大量顶级代码(就是没有缩进的代码,
python解释器读取到顶级代码会立即执行),其他.py文件应该只有少量顶级代码,所有功能都应该封装
在函数或类中
-
通常在文件结尾结合__name__变量,编写测试代码