爬虫的自我修养_2
一、Handler处理器 和 自定义Opener(引擎们)
-
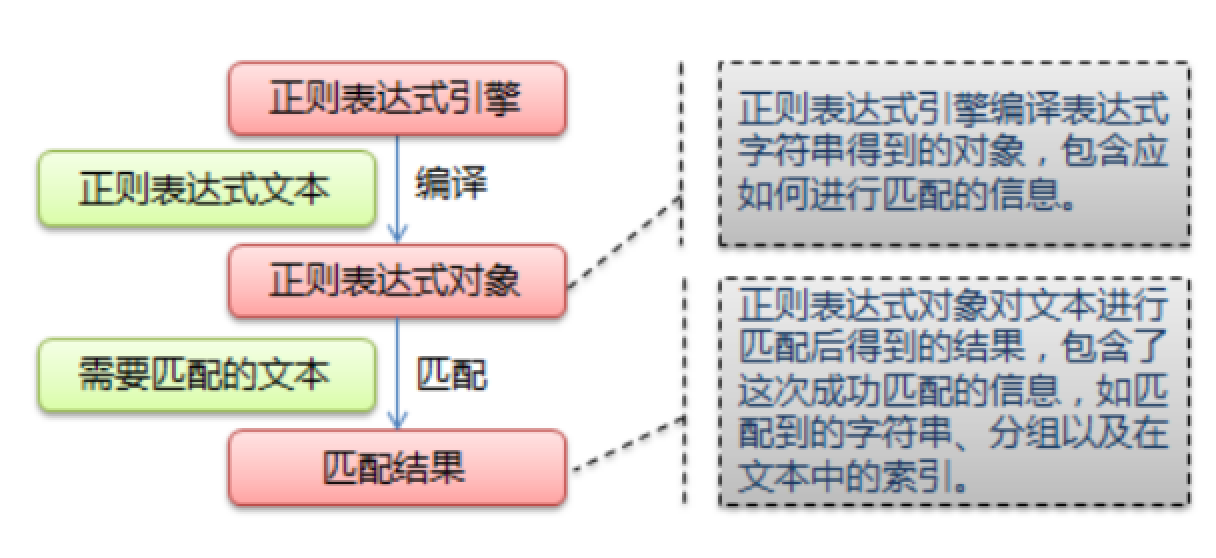
opener是 urllib2.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。
-
但是基本的urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以要支持这些功能:
- 使用相关的
Handler处理器来创建特定功能的处理器对象; - 然后通过
urllib2.build_opener()方法使用这些处理器对象,创建自定义opener对象; - 使用自定义的opener对象,调用
open()方法发送请求。
- 使用相关的
-
如果程序里所有的请求都使用自定义的opener,可以使用
urllib2.install_opener()将自定义的 opener 对象 定义为 全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
自定义简单的opener
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
# 构建一个HTTPHandler处理器对象,支持处理HTTP的请求
#http_handler = urllib2.HTTPHandler()
# 不加参数时,和使用urllib2.urlopen()发送HTTP/HTTPS请求得到的结果是一样的。
# 在HTTPHandler增加参数"debuglevel=1"将会自动打开Debug log 模式,程序在执行的时候会打印收发包的报头(请求头)的信息
http_handler = urllib2.HTTPHandler(debuglevel=1)
# 调用build_opener()方法构建一个自定义的opener对象,参数是构建的处理器对象
opener = urllib2.build_opener(http_handler)
request = urllib2.Request("http://www.baidu.com/")
response = opener.open(request)
# print response.read()
ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib2中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
# 代理开关,表示是否启用代理
proxyswitch = False
# 构建一个Handler处理器对象,参数是一个字典类型,包括代理类型和代理服务器IP+PROT
# httpproxy_handler = urllib2.ProxyHandler({"http" : "124.88.67.54:80"})
# 如果代理服务器有密码
authproxy_handler = urllib2.ProxyHandler({"http" : "mr_mao_hacker:sffqry9r@114.215.104.49:16816"})
# 构建了一个没有代理的处理器对象
nullproxy_handler = urllib2.ProxyHandler({})
if proxyswitch:
opener = urllib2.build_opener(httpproxy_handler)
else:
opener = urllib2.build_opener(nullproxy_handler)
# 构建了一个全局的opener,之后所有的请求都可以用urlopen()方式去发送,也附带Handler的功能
urllib2.install_opener(opener)
request = urllib2.Request("http://www.baidu.com/")
response = urllib2.urlopen(request)
#print response.read().decode("gbk")
print response.read()
免费代理网站:
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
HTTPPasswordMgrWithDefaultRealm()
HTTPPasswordMgrWithDefaultRealm()类将创建一个密码管理对象,用来保存 HTTP 请求相关的用户名和密码,主要应用两个场景:
- 验证代理授权的用户名和密码 (
ProxyBasicAuthHandler()) - 验证Web客户端的的用户名和密码 (
HTTPBasicAuthHandler())
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
test = "test"
password = "123456"
webserver = "192.168.21.52"
test2 = "x5456"
password2 = "5456"
webserver2 = "119.130.115.226:808"
# 构建一个密码管理对象,可以用来保存和HTTP请求相关的授权账户信息
passwordMgr1 = urllib2.HTTPPasswordMgrWithDefaultRealm()
passwordMgr2 = urllib2.HTTPPasswordMgrWithDefaultRealm()
# 添加授权账户信息,第一个参数realm如果没有指定就写None,后三个分别是站点IP,账户和密码
passwordMgr1.add_password(None, webserver, test, password)
# 代理服务器的ip:port、用户名、密码
passwordMgr2.add_password(None, webserver2, test2, password2)
# HTTPBasicAuthHandler() HTTP基础验证处理器类
httpauth_handler = urllib2.HTTPBasicAuthHandler(passwordMgr1)
# 处理代理基础验证相关的处理器类
proxyauth_handler = urllib2.ProxyBasicAuthHandler(passwordMgr2)
# 构建自定义opener,里面可以加多个参数
opener = urllib2.build_opener(httpauth_handler, proxyauth_handler)
# urllib2.install_opener(opener) # 加上这句话,urllib2.urlopen()使用的是我们自写的opener
request = urllib2.Request("http://192.168.21.52/")
# 用加上授权验证信息
response = opener.open(request)
# 没有授权验证信息
#response = urllib2.urlopen(request)
print response.read()
Cookie的应用
Cookies在爬虫方面最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续。
cookielib库 和 HTTPCookieProcessor处理器
在Python处理Cookie,一般是通过cookielib模块和 urllib2模块的HTTPCookieProcessor处理器类一起使用。
cookielib模块:主要作用是提供用于存储cookie的对象
HTTPCookieProcessor处理器:主要作用是处理这些cookie对象,并构建handler对象。
cookielib 库
该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与
Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与
libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
其实大多数情况下,我们只用CookieJar(),如果需要和本地文件交互,就用 MozillaCookjar() 或 LWPCookieJar()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib,urllib2,cookielib
# 通过CookieJar()类构建一个cookieJar()对象,用来保存cookie的值
cookie = cookielib.CookieJar()
# 通过HTTPCookieProcessor()处理器类构建一个处理器对象,用来处理cookie
# 参数就是构建的CookieJar()对象
cookie_handler = urllib2.HTTPCookieProcessor(cookie)
# 构建一个自定义的opener
opener = urllib2.build_opener(cookie_handler)
# 通过自定义opener的addheaders的参数,可以添加HTTP报头参数
opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36")]
# renren网的登录接口
url = "http://www.renren.com/PLogin.do"
# 需要登录的账户密码
data = {"email":"mr_mao_hacker@163.com", "password":"alarmchime"}
# 通过urlencode()编码转换
data = urllib.urlencode(data)
# 第一次是post请求,发送登录需要的参数,获取cookie
request = urllib2.Request(url, data = data)
# 发送第一次的post请求,生成登录后的cookie(如果登录成功的话)
response = opener.open(request)
# 获取个人主页
print response.read()
# 已经有cookie了,那还不干点别的事 ,第二次可以是get请求,这个请求将保存生成cookie一并发到web服务器,服务器会验证cookie通过
response_deng = opener.open("http://www.renren.com/410043129/profile")
# 获取登录后才能访问的页面信息
print response_deng.read()
小Tips:
两种添加报头的方法 request.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36") opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36")]
二、Re模块
实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
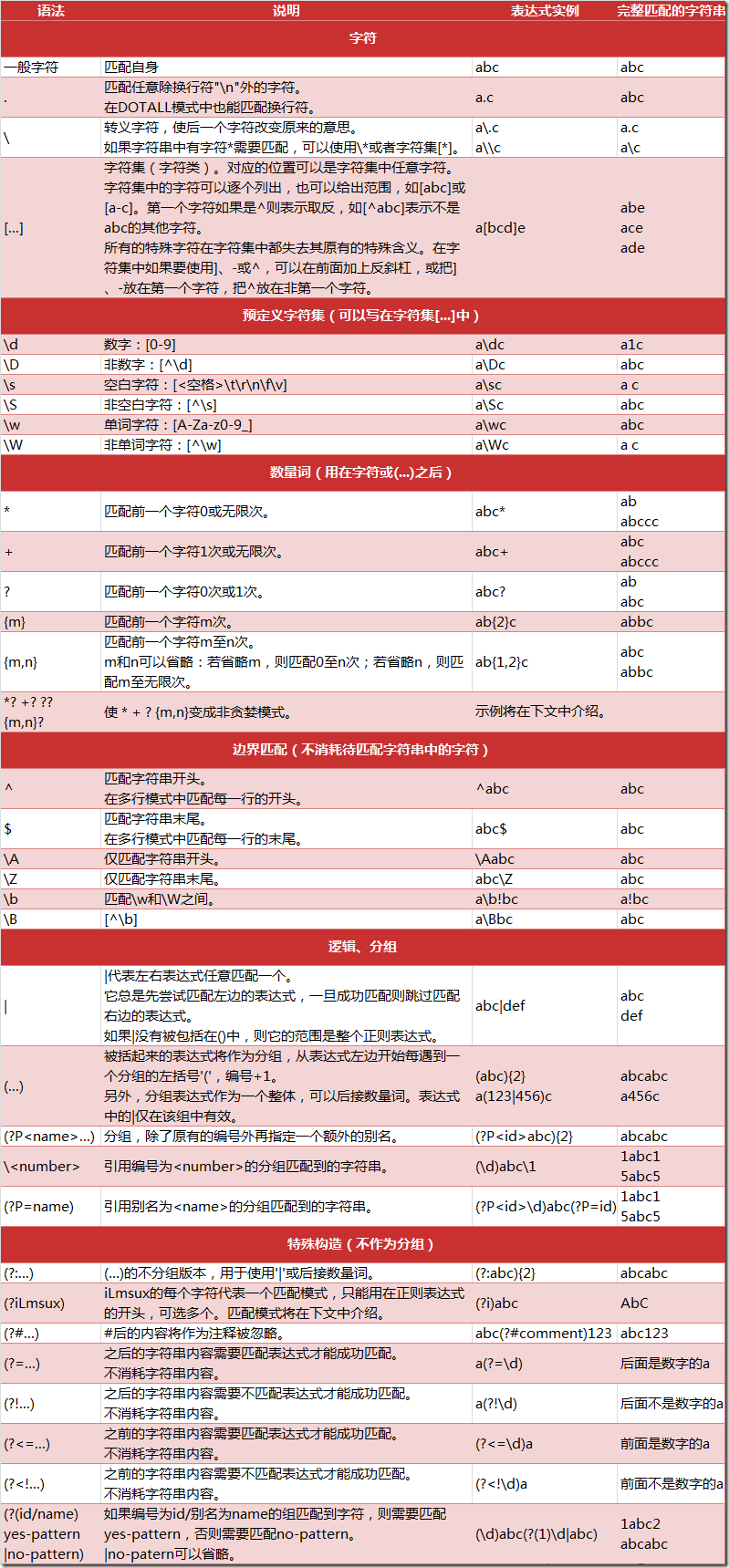
对于文本的过滤或者规则的匹配,最强大的就是正则表达式,是Python爬虫世界里必不可少的神兵利器。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式匹配规则
python中的re模块
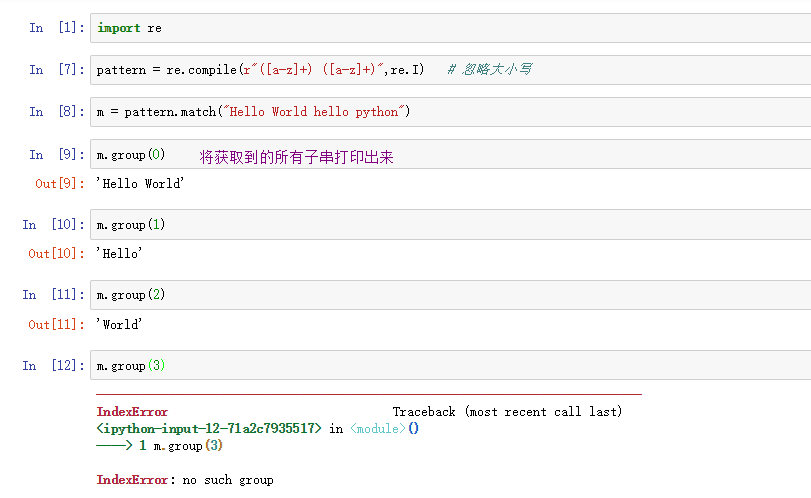
pattern = re.compile(r"d") # r表示字符串不受
,d,w等转义字符影响,u表示是unicode字符串
pattern.match(str,begin,end) # 起始位置,终止位置(是以切片的形式顾头不顾尾)
# 从起始位置开始往后找,返回第一个符合规则的(返回的是match对象),只匹配一次
pattern.search(str,begin,end)
# 从随机位置开始往后找,返回第一个符合规则的(返回的也是match对象),只匹配一次
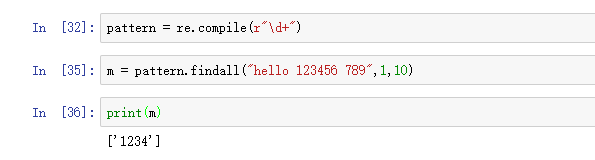
pattern.findall(str,begin,end)
# 匹配全部字符串,返回列表
pattern.split(str,count) # 切割次数
# 分割字符串
pattern.sub('替换文字',"字符串")
re.I ==> 忽略大小写 re.S ==> 全文匹配
用法
match

search
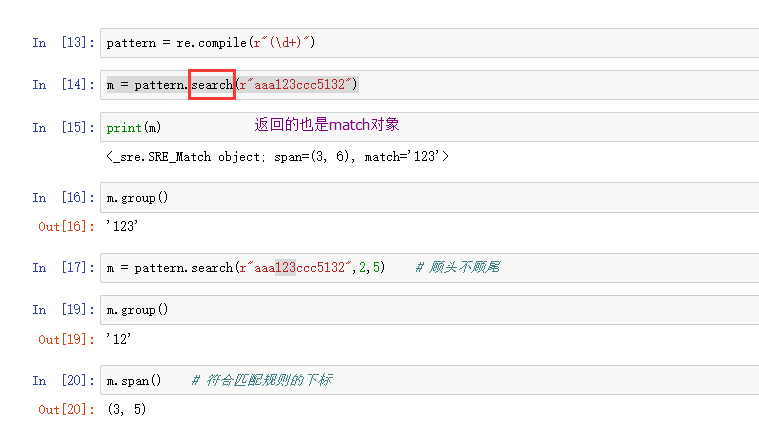
findall

split

sub



1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import urllib2,urllib,re 5 6 class Spider(object): 7 def __init__(self): 8 self.page = 1 9 self.switch = True 10 11 def loadPage(self): 12 """ 13 下载页面 14 :return: 15 """ 16 url = "http://www.neihan8.com/article/list_5_"+str(self.page)+".html" 17 # headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} 18 # request = urllib2.Request(url,headers=headers) 19 # response = urllib2.urlopen(request) 20 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} 21 request = urllib2.Request(url, headers=headers) 22 print("正在下载...") 23 response = urllib2.urlopen(request) 24 html = response.read().decode('gbk') 25 self.dealPage(html) 26 27 def dealPage(self,html): 28 """ 29 处理页面 30 :return: 31 """ 32 pattern = re.compile('<divsclass="f18 mb20">(.*?)</div>',re.S) 33 content_list = pattern.findall(html.replace("<p>","").replace("</p>","").replace("<br />","").replace("<br>",""). 34 replace("…","").replace('”','').replace("“",'')) 35 for i in content_list: 36 self.writePage(i) 37 38 def writePage(self,duanzi): 39 """ 40 保存段子 41 :return: 42 """ 43 with open('duanzi.txt','a') as f: 44 print("正在保存...") 45 f.write(duanzi.encode('utf-8')) 46 47 def startWork(self): 48 """ 49 控制爬虫是否运行 50 :return: 51 """ 52 while self.switch: 53 self.loadPage() 54 userinput = raw_input("任意键继续爬取,输入q停止爬取") 55 if userinput == 'q': 56 self.switch = False 57 print("谢谢使用...") 58 self.page += 1 59 60 if __name__ == '__main__': 61 duanziSpider = Spider() 62 duanziSpider.startWork()
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
初步使用
我们利用它来解析 HTML 代码,简单示例:
# lxml_test.py
# 使用 lxml 的 etree 库
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
#利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text)
# 按字符串序列化HTML文档
result = etree.tostring(html)
print(result)
输出结果:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
lxml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签。
文件读取:
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
再利用 etree.parse() 方法来读取文件。
# lxml_parse.py
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
输出结果与之前相同:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
XPath实例测试
1. 获取所有的 <li> 标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
print type(html) # 显示etree.parse() 返回类型
result = html.xpath('//li')
print result # 打印<li>标签的元素集合
print len(result)
print type(result)
print type(result[0])
输出结果:
<type 'lxml.etree._ElementTree'> [<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>] 5 <type 'list'> <type 'lxml.etree._Element'>
2. 继续获取<li> 标签的所有 class属性
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print result
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3. 继续获取<li>标签下hre 为 link1.html 的 <a> 标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print result
运行结果
[<Element a at 0x10ffaae18>]
4. 获取<li> 标签下的所有 <span> 标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
#result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
print result
运行结果
[<Element span at 0x10d698e18>]
5. 获取 <li> 标签下的<a>标签里的所有 class
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class')
print result
运行结果
['blod']
6. 获取最后一个 <li> 的 <a> 的 href
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()]/a/@href')
# 谓语 [last()] 可以找到最后一个元素
print result
运行结果
['link5.html']
7. 获取倒数第二个元素的内容
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')
# text 方法可以获取元素内容
print result[0].text
运行结果
fourth item
8. 获取 class 值为 bold 的标签名
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# tag方法可以获取标签名
print result[0].tag
运行结果
span
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import urllib2,urllib,os 5 from lxml import etree 6 7 class Spride(object): 8 def __init__(self): 9 self.img_name = 1 10 self.headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"} 11 12 13 def loadPage(self,url): 14 """ 15 获取贴吧中每个帖子的url 16 url: 需要爬取的url地址 17 :return: 18 """ 19 request = urllib2.Request(url) # headers=self.headers 20 html = urllib2.urlopen(request).read() 21 # 解析HTML文档为HTML DOM模型 22 content = etree.HTML(html) 23 # 返回所有匹配成功的列表集合 24 link_list = content.xpath('//div[@class="col2_right j_threadlist_li_right "]/div/div/a/@href') 25 for i in link_list: 26 # 拼接每个帖子的链接 27 fulllink = "http://tieba.baidu.com" + i 28 self.loadImg(fulllink) 29 30 def loadImg(self,link): 31 """ 32 获取帖子中图片的url 33 :return: 34 """ 35 request = urllib2.Request(link,headers=self.headers) 36 img_html = urllib2.urlopen(request).read() 37 img_content = etree.HTML(img_html) # 解析HTML文档为HTML DOM模型 38 # 取出帖子里每层层主发送的图片连接列表集合 39 img_link_list = img_content.xpath('//img[@class="BDE_Image"]/@src') 40 for i in img_link_list: 41 self.writeImg(i) 42 43 def writeImg(self,img_url): 44 """ 45 保存图片到本地 46 :return: 47 """ 48 request = urllib2.Request(img_url,headers=self.headers) 49 # 图片原始数据 50 img = urllib2.urlopen(request).read() 51 # 写入到本地磁盘文件内 52 with open(str(self.img_name)+".jpg",'wb') as f: 53 f.write(img) 54 print(str(self.img_name)+'.jpg下载成功') 55 self.img_name+=1 56 57 def tiebaSpider(self): 58 """ 59 爬虫调度器,负责拼接每个页面的url 60 :return: 61 """ 62 tieba_name = raw_input("请输入要下载的贴吧名:") 63 start_page = int(raw_input("请输入起始页:")) 64 end_page = int(raw_input("请输入结束页:")) 65 tieba_name = urllib.urlencode({'kw':tieba_name}) 66 for page in range(start_page,end_page+1): 67 pn = (page-1)*50 68 fullurl = "http://tieba.baidu.com/f?"+ tieba_name + "&pn=" + str(pn) 69 self.loadPage(fullurl) 70 print("谢谢使用") 71 72 if __name__ == "__main__": 73 img_Spride = Spride() 74 img_Spride.tiebaSpider()
小Tips:
使用Xpath获取浏览器的内容时,最好用IE的user-agent IE8:Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C) 可以在xpath规则中使用/text() 直接获取当前标签的值,不用text.xpath(//div[contains(@id, "qiushi_tag_")]//h2)[0].text这样获取了 //div[contains(@id, "qiushi_tag_")]//h2/text() //a/@href # 直接获取href链接