源码包:
org.apache.spark.sql.Dataset.scala
数据:
stu.json
{"stuid":"19001","classid":"1002","name": "Michael", "age": 12}
{"stuid":"","classid":"1001","name": "Andy", "age": 13}
{"stuid":null,"classid":"1002","name": "Justin", "age": 8}
{"stuid":"19001","classid":"1002","name": "Michael", "age": 12}
{"stuid":"","classid":"1001","name": "Andy", "age": 13}
{"stuid":null,"classid":"1002","name": "Justin", "age": 8}
cls.json
{ "classid": "1001", "teacher": "Wang"}
{ "classid": "1002", "teacher": "Li"}
###判空
val st = df.isEmpty
###显示所有行
df.show()
###显示指定行数
$ df.show(10)
###limit
df.limit(1).show()

###显示所有列名
val list = df.columns
for(l <- list){
println(l)
}

###显示一个字段,返回对象为Colum名
val colName = df.col("name")
println(colName)
###删除返回的某个字段
df.drop("age").show()
###显示概要 字段信息
df.printSchema()

###显示概况
df.describe().show()

###查询总行数
val num = df.count()
###把所有行放入一个变量,返回Array对象
val list = df.collect()
###获取头几行
val list = df.head(3)
val list = df.take(3)
for(l <- list){
println(l)
}
###查空
df.filter("stuid is null").select("name").show()
df.filter("stuid is not null").select("name").show()
df.filter(df("stuid").isNull).select("name").show()
df.filter("stuid <> ''").select("name").show()
###别名
df.select(df("name").as("username")).show()
df.withColumnRenamed("name", "stuname").show() 查询出所有列,只修改设置的列名
###去重
df.distinct().show()
df.dropDuplicates(Seq("name")).show() ###根据指定列去重

###条件查询
df.select("name", "age").where("age>12").show()
df.select("name", "age").where("age>10 and name like '%n%'").show()
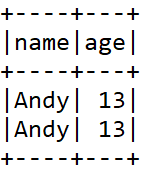
###排序
df.select("name", "age").sort("age").show()
df.select("name", "age").sort(df("age").asc).show()
df.select("name", "age").sort(df("age").desc).show()
df.select("name", "age").orderBy(df("age").desc, df("name").asc).show()
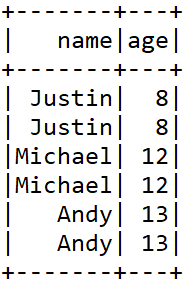
###分组
df.select("name", "age").groupBy("name").count().show()
df.select("name", "age").groupBy(df("name")).count().show()
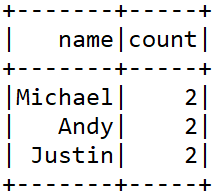
###汇总
df.select("name", "age").groupBy(df("name")).sum().show()

###函数
df.select("name","age").groupBy(df("name")).max().show()
df.select("name","age").groupBy(df("name")).avg().show()
df.select("name","age").groupBy(df("name")).min().show()

df.select("name","age").groupBy().max("age").show()
df.select("name","age").groupBy().avg("age").show()

###聚合函数
df.agg("name" -> "max", "age" -> "avg").show()

###结果合并
df.union(df).show()
df.union(df.limit(1)).show()
###连接
stuDF.join(clasDF).show() 笛卡尔积
stuDF.join(clasDF, "classid").show() 要求有一个相同的字段
df.select(df("classid").as("claid"), df("name")).join(df2, "claid").show()
df.join(df2, Seq("name", "id"), "inner").show() 多个字段关联,inner left/left_outer right/right_outer outer
###是否存在
df.intersect(df2.limit(1)).show()
###不存在
df.except(df.limit(1)).show()
###新增一个列
df.withColumn("newCol", df("classid")).show()

###修改某列值
df.withColumn("age", df("age")+100).show()
