一、基本介绍
可以进行功能测试、性能测试、自动化测试。
二、配置元件介绍
线程组:threads

虚拟用户数,设置Jmeter按照什么场景运行,是一系列线程的集合,每一个线程都代表一个正在使用应用程序的用户。在JMeter中,每一个线程都意味着模拟一个真实用户向服务器发起请求。比如设置的线程数为50,JMeter将创建并模拟测试50个用户请求到服务器端
(指的是在线用户数量,并不是并发数量)。
setUp Thread Group:用于执行预测试操作,比如初始化的配置,类似LR中的init
tearDown Thread Group:用于执行测试后动作,比如建立数据库连接后,测试结束需要关闭数据库,类似LR中的end。
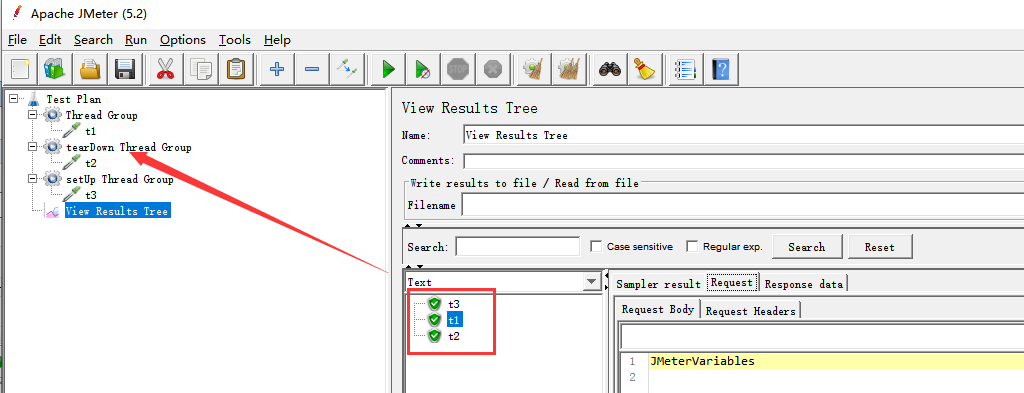
结论:线程组在同一作用域名范围内执行顺序为:setUp Thread Group (init进行初始化操作)->线程组-> tearDown Thread Group(进行收尾关闭工作)
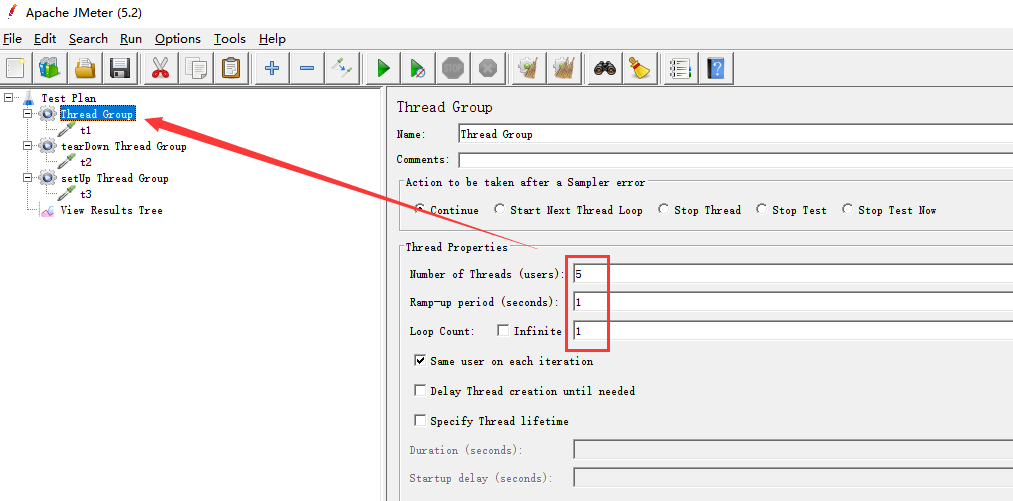

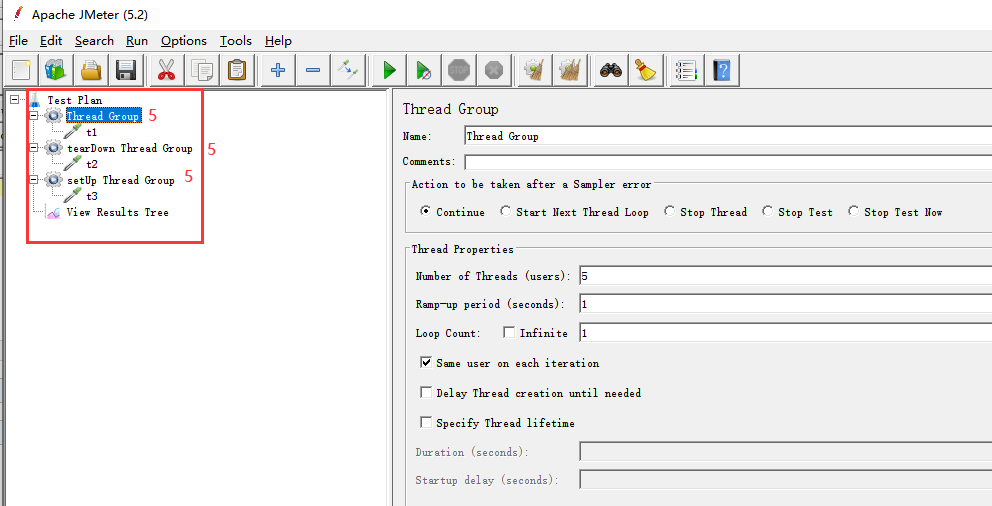
验证:

结论:线程组的执行次数跟线程数有关。
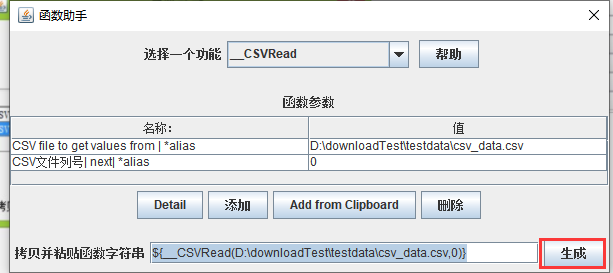
菜单栏:函数助手对话框:
打开方式:打开-选项-函数助手对话框-_CSVRead)
作用:读取csv文件的第二种方式,也是读取参数的第三种方式
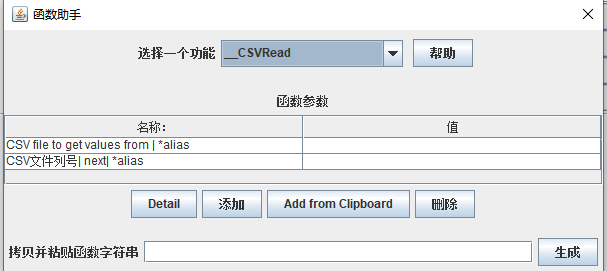
其中第一行表示:填写csv文件的路径+名称
第二行表示:参数的列号,默认是从0开始的。
点击生成即可,在复制到对应的请求参数中:
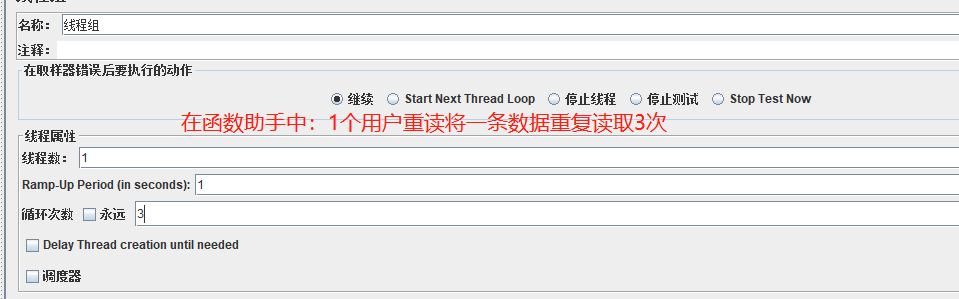
注意:利用函数助手读取CSV文件时,默认线程数也就是代表一个用户数永远只会读取一个数据,就算加上循环次数也只是表示一个用户重复将一个数据读取三次。如下所示:
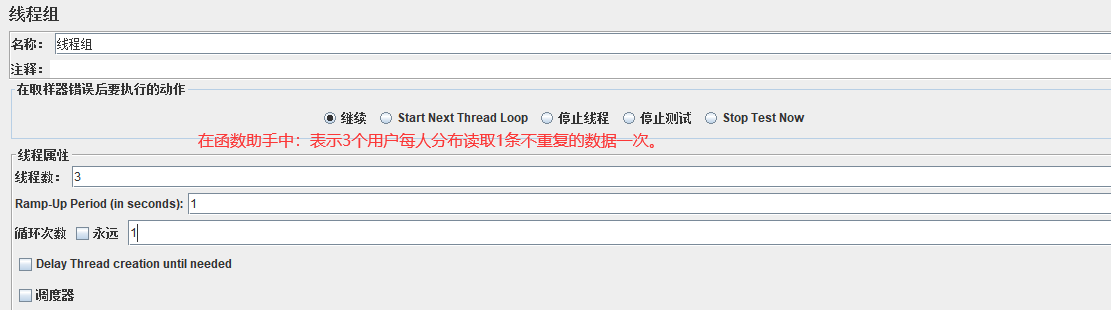
注意:利用函数助手读取CSV文件时,要想所有的数据都能被读取,只是通过线程数来控制,多个线程数表示多个用户分别读取不同的数据。
2.1:HTTP请求默认值:
打开方式:配置元件---http请求默认值
作用:可以设定一些缺省值,假设有10个请求,访问域名和端口都是一样的,那HTTP请求中就不再需要单独配置了,比较方便这样增加脚本的移植性。

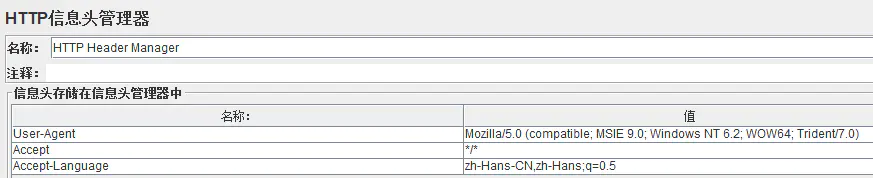
2.2:HTTP信息头管理:
打开方式:配置元件---http信息头管理
作用:内容为空,有需要的时候进行添加,否则无需处理,一般的请求格式:
1、类似form表单
2、参数json格式,添加Content-Type:application/json,utf-8
3、参数是XML,添加text/xml
2.3:HTTP cookie 管理器:
打开方式:配置元件---http cookie 管理器
作用:发送请求,经常要校验cookies信息,录制时使用的cookie管理器,只能在指定的域下面使用,如果服务器地址切换,发现发送请求时,就会出现no cookies。
储存在用户本地终端上的数据,主要用于默认cookie管理,通常情况下,当用户结束浏览器会话时,系统将终止所有的cookie,当web服务器创建了Cookie后,只要在其有效期内,当用户访问同一个Web服务器时,浏览器首先要检查本地的cookies,并将其原样发送
给web服务器。
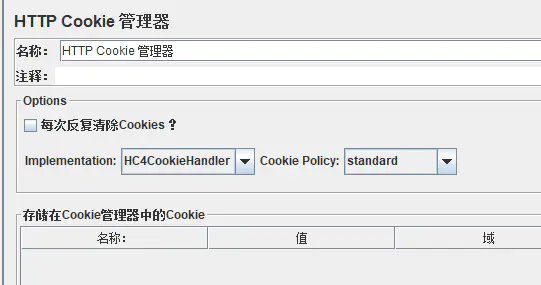
如何设置:
1、自动管理cookies,jmeter配置文件中设置(bin目录)CookieManage.save.cookies=true,去掉前面的#,然后重启jmeter
2、手动添加cookies,可以利用Firefox中导出cookies之后,再导入Jmeter中轻松完成(浏览器需安装Firebug)
2.4:HTTP 授权管理器:
打开方式:配置元件---http 授权管理器
作用:可以理解为用户名和密码的验证过程,也是一种验证机制,比如说客户端或浏览器与服务端发生交互、发生请求时,需要提供凭证(URL、用户名、密码),提交后服务端通过后才会继续后续的请求或者交互。
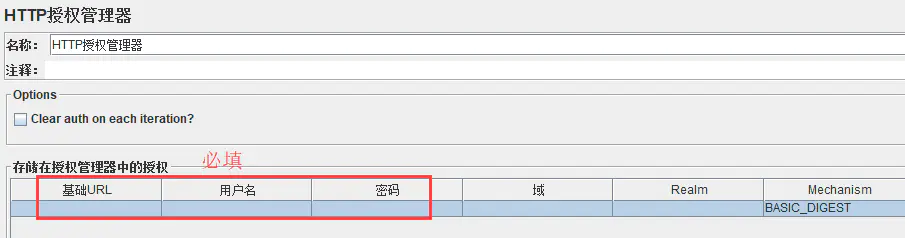
clear auth on each iteration:是不是每次迭代时都清空,不勾验证一次可能就不再去验证了,一般不勾
2.5:计数器:
打开方式:配置元件---计数器
作用:数字记录

启动(Starting value):开始值
递增:即步长,以多少进行增长,若值为2,起始值为1,那么第二个请求执行时就是3
最大值(Maxinum value):一直递增到最大值时停止增长
Number format:python-00000000,0表示占位符
引用名称:存储递增后的值,如num
与每用户独立的跟踪计数器:每个线程都去独立计数,互不干扰,准确性会更高一点
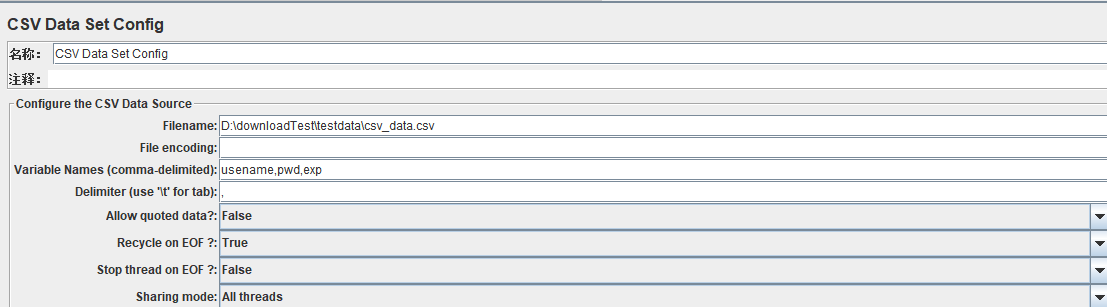
2.6:CSV Data Set Config :
打开方式:配置元件---csv data set config
作用:用于读取txt文件数据,注意:默认txt文件的第一行内容会被当成参数读取

Filename:txt数据文件的文件路径+文件名称
Variable Names:txt文件中文件列的变量名
jmeter 参数的调用方式:

与正则表达式类似:${变量名},如${p1}
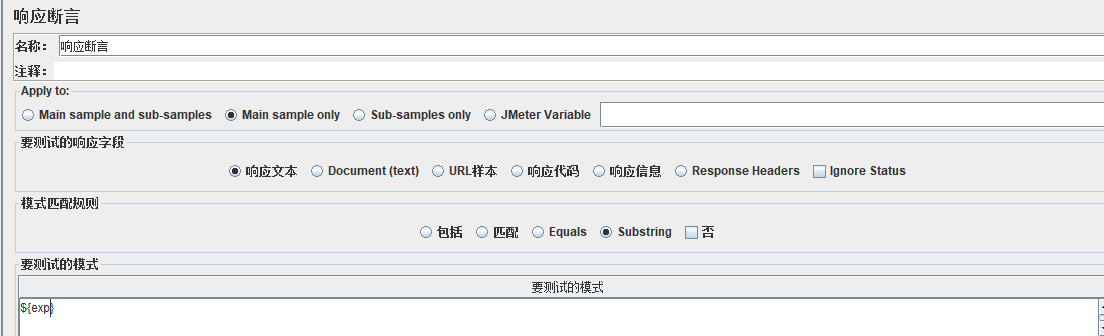
2、CSV Data Set Config:也可以用于读取csv文件数据,注意:默认csv文件的第一行内容会被当成参数读取,其他参数写法同上。${变量名}格式,也可以在文件中加入于其结果一列。

这样在jmeter配置中加入预期结果的参数:
在响应断言中添加预期结果即可:
2.8:用户定义的变量 :
打开方式:配置元件---用户定义的变量
作用:对于测试来说经常更换测试服务器地址时常有的事情,所以把测试的服务器地址作为用户定义的变量最适合不过,将测试的ip地址写在变量中,http请求中在去引用这些变量:

三、sampler
3.1:HTTP请求:
打开方式:线程组---sampler----Http请求
作用:可以设定一些缺省
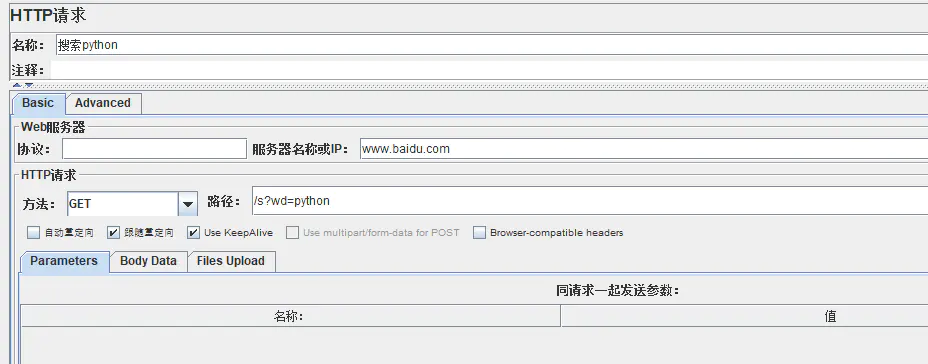
Content encoding :内容的编码方式,默认值为iso8859
自动重定向:如果选中该选项,当发送HTTP 请求后得到的响应是302/301 时,JMeter 自动重定向到新的页面Use multipart/from-data for HTTP POST :当发送HTTP POST 请求时,可以使用表单形式发送,默认不选中。
注意:如果是POST请求,数据以Json的格式传的,那么可以把参数写在Body Data里面,格式:{"XXX":"XXX"},若不是Json格式的话就直接写xx=xx,多个参数中间用&
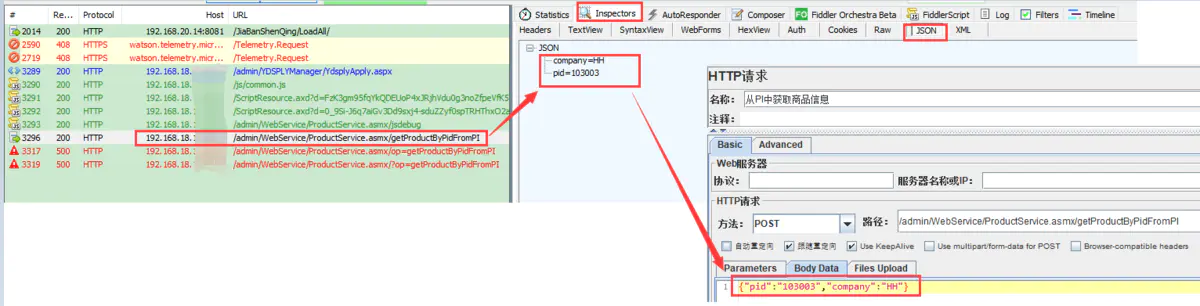
四、后置处理器
4.1:正则表达式提取器:当上文有些变量的值在下文当中被使用:
注意:loadrunner与jmeter中关联的不同之处:
1、在loadruner中关联函数是写在要获取变量值的页面的前面,而在jmeter中关联值是写在要获取变量值页面的后面。
2、在loadrunner中关联函数是用注册函数,而在jmeter中使用正则表达式提取器来进行关联。
打开方式:后置处理器---正则表达式提取器
作用:用于接口间参数传递
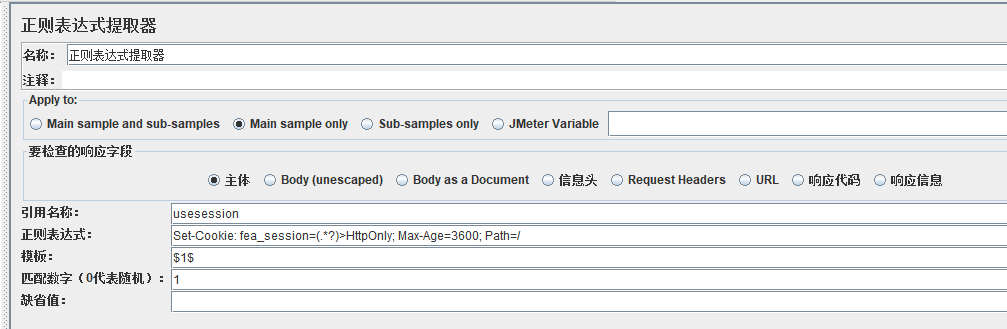
引用名称:相当于变量名
正则表达式:提取需要值的正则表达式
模板:表示提取结果中的第几值,一般结果用列表表示,$!$表示取结果中的第一个值,$n$表示取结果中的第n个值
匹配数字:0表示随机取,1表示取全部数据,n表示取个数据
缺省值:表示没有值时使用的默认数
案例:多参数获取
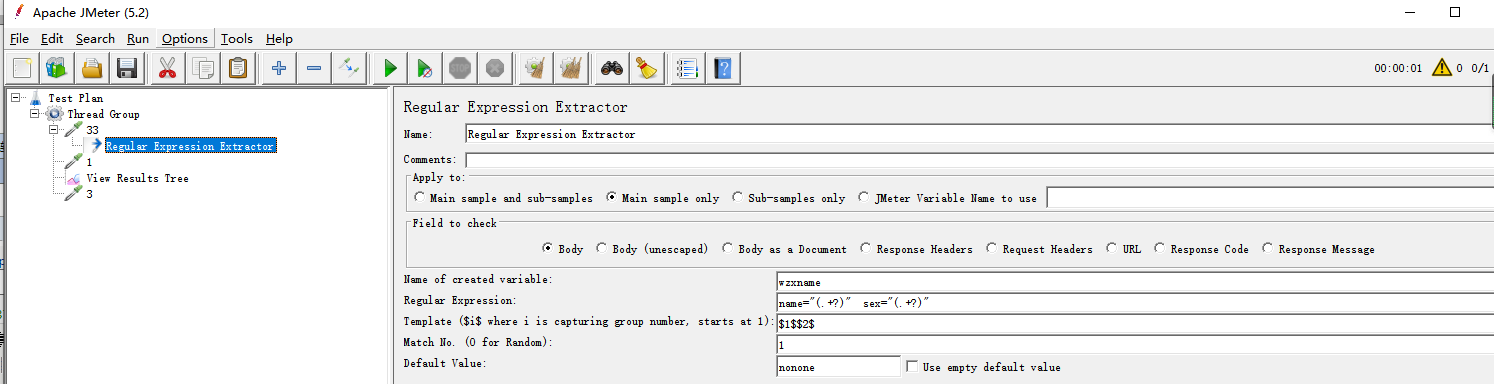
查看结果树:
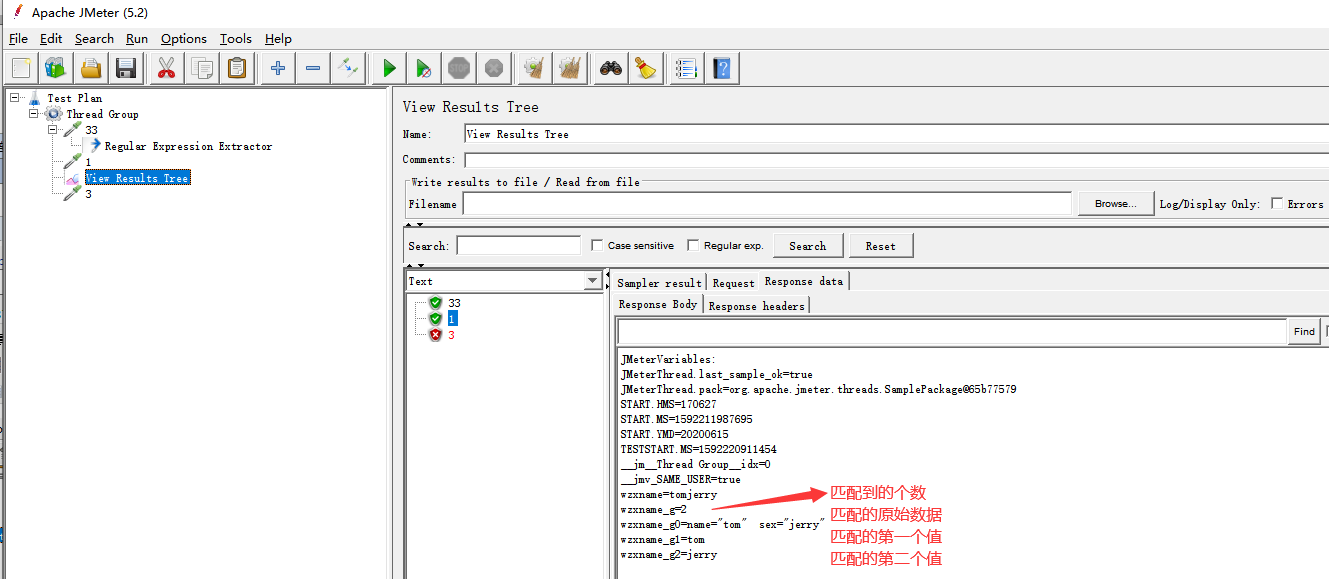
jmeter 参数的调用方式:
名称:表示参数名
值:${变量名},此处的变量名即时正则表达式中的引用名称。
五、前置处理器
5.1:用户参数:
打开方式:前置处理器---用户参数
作用:用于接口间参数传递
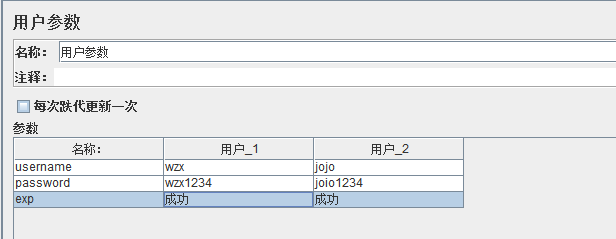
后面的函数使用和之前的读取方式相同,${变量名}格式读取。
注意:如果以用户参数读取数据,线程数的配置原理与函数助手相同,一个线程数多次循环只会读取重复读取某一行数据。