Fluentd 自定义字段解析
本文分享fluentd日志采集,把一些自定义字段(json)解析出来变成新字段。
PS: 不熟悉fluentd,建议先看:
解析思路
1. 约定日志格式
在打印日志可以约定一个分隔符如"@|@"(只做举例),假设有以下日志:
[2020-06-06 12:00:00 +0900] INFO hello world @|@{"key1": "value1", "key2": "value2"}
2. 正则截取
Ruby正则(命名捕获)匹配出"@|@"后面的json内容,把他复制到另一个新字段(temp)。
<parse>
@type regexp
expression /^[(?<logtime>[^]]*)] (?<level>[^ ]*) (?<message>.+?(?=( @|@.+)?$))(?: @|@(?<temp>.*))?/
time_key logtime
time_format %Y-%m-%d %H:%M:%S %z
</parse>
假设输入的日志(Event)为:
[2020-06-06 12:00:00 +0900] INFO hello world @|@{"key1": "value1", "key2": "value2"}
解析后的日志:
time:
1362120400 (2020-06-06 12:00:00 +0900)
record:
{
"level" : "INFO",
"message": "hello world",
"temp" : {"key1": "value1", "key2": "value2"}
}
3. 使用filter解析json
使用filter解析temp字段(json)的内容
<filter test.*>
@type parser
key_name temp
reserve_data true # 保留除temp外的其他字段
remove_key_name_field true # 解析成功删除temp字段,如果要保留temp字段则关闭
<parse>
@type json
json_parser json # 重点,必须加这句才能把json解析成字段
</parse>
</filter>
使用过滤器后:
time:
1362120400 (2020-06-06 12:00:00 +0900)
record:
{
"level" : "INFO",
"message": "hello world @|@",
"key1": "value1",
"key2": "value2"
}
示例
<source>
@type tail
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag test.*
<parse>
@type regexp # 亦可使用mutilline
expression /^[(?<logtime>[^]]*)] (?<level>[^ ]*) (?<message>.+?(?=( @|@.+)?$))(?: @|@(?<temp>.*))?/
time_key logtime
time_format %Y-%m-%d %H:%M:%S %z
</parse>
</source>
<filter>
@type parser
key_name temp
reserve_data true # 保留除temp外的其他字段
remove_key_name_field true # 解析成功删除temp字段
<parse>
@type json
json_parser json # 重点,必须加这句才能把json解析成字段
</parse>
</filter>
<match test.*>
@type stdout
<match>
在线ruby正则解析工具
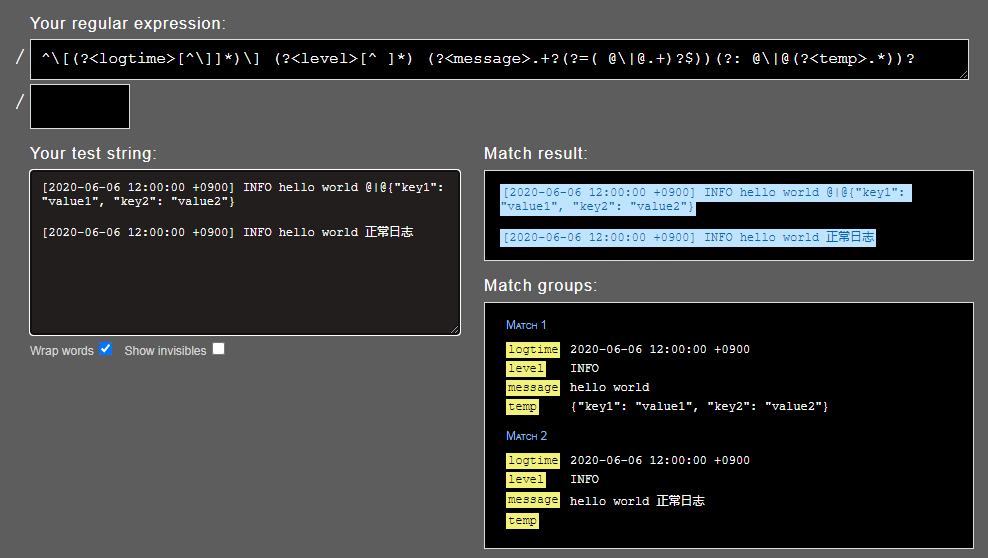
在线正则解析
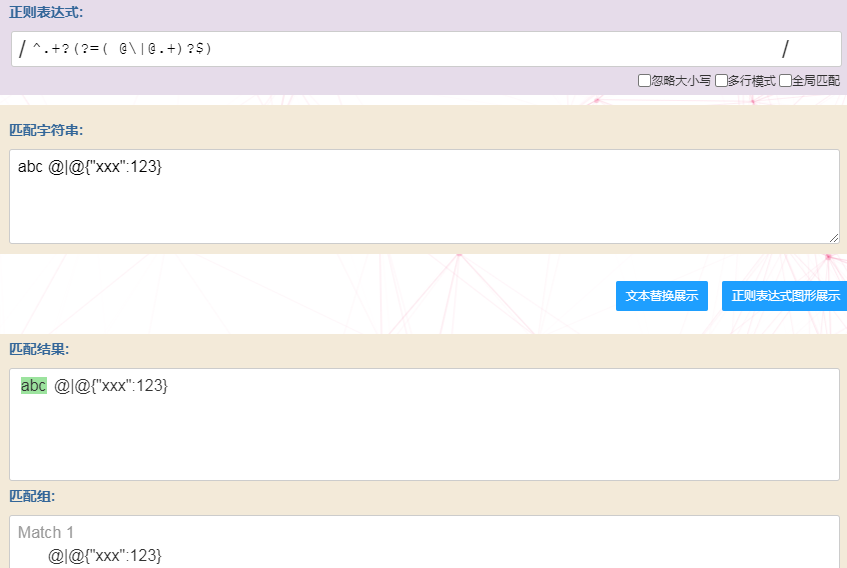
PS: 例子中用到的正则表达式^.+?(?=( @|@.+)?$)说明:
对于abc @|@{"xxx":123}字符串:
- 若存在分隔符" @|@",则截取分隔符前面的内容abc;
- 若不存在,则截取整个字符串如abc{"xxx":123}
优化
上面是最直接的思路。
可能通过fluentd的多分支处理应该也可以实现,有待研究。