第二章 数据组织
在数据的组织结构设计上,Laxcus严格遵循数据和数据描写叙述分离的原则,这个理念与关系数据库全然一致。在此基础上,为了保证大规模数据存取和计算的须要,我们设计了大量新的数据处理技术。同一时候出于兼顾用户使用习惯和简化数据处理的目的,继续沿用了一些关系数据库的设计和定义,当中不乏对SQL做适量的修订。
在这些变化中,核心仍然是以关系代数的理念去处理数据,以及类自然语言风格的数据描写叙述。所以用户在使用体验上。和关系数据库相比。不会感觉到有太多的差异。
本章将介绍Laxcus数据结构的组成,并对当中的一些修订和修订原因做出说明。
2.1 基础
Laxcus沿袭了关系数据库的用户模型、逻辑模型、存储模型的三层结构。对于逻辑模型。遵循用户账号、数据库、表的结构序列,即用户账号下能够建立多个数据库。数据库下能够建立多个表,在表之下是数据文件。
由于Laxcus的多集群架构,支持表跨节点跨集群存在。
在逻辑描写叙述上。表是行的集合。行由多列构成,每一列相应一个数据值。实体的行,最多容纳32767列(0x7FFF),这个尺寸足以满足各种数据应用须要。
在列的基础上,能够建立索引,通过索引实现对表的高速检索。
用户的配置数据经过加密后。会保存到Top节点的数据字典里。
在兼容SQL方面,SQL的管理控制语句、数据定义语句、数据操作语句,以及运算符、keyword、大部分SQL函数。被完整继承下来。
用户依旧能够依照SQL标准进行操作。被支持的还有“空值”,包含NULL和EMPTY。二者的差别是,NULL表示数据值没有定义或者不知道。适用于全部数据类型;EMPTY仅仅用在字符或者字节数组上,表示数据值确定且是0长度。做为SQL核心的4个操作语句也得到支持,并在此基础上扩展了SELECT嵌套语句、ORDER BY、GROUP BY子句,另外也能够使用LIKEkeyword进行模糊检索。
|
管理语句 |
说明 |
|
CREATE USER |
建立一个用户账号和password |
|
ALTER USER |
改动用户账号的password |
|
DROP USER |
删除一个用户账号及其下的全部数据资料 |
|
GRANT |
对用户账号下的某个操作授权 |
|
REVOKE |
收回用户账号下的某个操作权利 |
表2.1.1 管理语句
|
数据定义 |
说明 |
|
CREATE DATABASE |
建立一个数据库 |
|
DROP DATABASE |
删除一个数据库及其下的全部表 |
|
CREATE TABLE |
建立一个表 |
|
DROP TABLE |
删除一个表和其下的全部数据 |
表2.1.2 数据定义语句
|
数据操作 |
说明 |
|
INSERT |
写入记录 |
|
DELETE |
删除记录 |
|
UPDATE |
更新记录 |
|
SELECT |
查询记录 |
|
JOIN |
连接查询 |
表2.1.3 数据操作语句
|
运算符类型 |
运算符 |
说明 |
|
比較运算符 |
= |
等于 |
|
> |
大于 |
|
|
< |
小于 |
|
|
>= |
大于等于 |
|
|
<= |
小于等于 |
|
|
<> != |
不等于 |
|
|
逻辑运算符 |
not |
非 |
|
and |
与 |
|
|
or |
或 |
|
|
between ... and |
在某些数据范围内 |
|
|
in |
满足多个条件之中的一个 |
|
|
like |
模糊查询。匹配特定符串 |
|
|
赋符运算符 |
= |
对变量赋值 |
表2.1.4 运算符
2.2 数据类型
眼下各种关系数据库上的数据类型,由于产品和版本号原因。数量也不尽同样。在实际应用中,最经常使用到的大约10余个。依据这样的现状。我们在设计数据类型时做了简化处理,取消了当中大部分比較少用的数据类型,保留了一批基础数据类型,另外考虑到网络应用需求,新添加了一批数据类型,同一时候对某些数据类型进行了合并。最后把它们分为两大类:固定长的数值类型、可变长的数组类型。见表2.2所看到的。
数值类型在不同操作系统平台上都是统一的,数组类型的长度范围在0 - 2G字节之间,能够随输入数据自己主动调整。这个尺寸足以容纳当前各种文本、图片、视频、音频等多媒体内容。由于这个尺寸对用户来说已经足够大,用户在输入数据时,能够忽略列长度问题。在字符选择上,为了适用于多语言的混合环境,字符类型内码统一採用Unicode编码,因此就避免了乱码现象。Laxcus字符定义是。单字节的Char相应UTF8编码,双字节的WChar相应UTF16 Big Endian编码,四字节的HChar相应UTF32编码。
用户在设计表的时候能够依据须要选择。比如英文环境应该使用Char,东亚语系内码和西里尔文字都是双字节,採用WChar更合适。
|
数据类型 |
标识 |
字长 |
范围 |
|||
|
数组 类型 |
字节 |
原始类型 |
RAW(BINARY) |
8 |
0 - 2G |
|
|
媒体 |
文档 |
DOCUMENT |
8 |
|||
|
图像 |
IMAGE |
|||||
|
音频 |
AUDIO |
|||||
|
视频 |
VIDEO |
|||||
|
字符 |
单字符 |
CHAR |
8 |
|||
|
宽字符 |
WCHAR |
16 |
||||
|
大字符 |
HCHAR |
32 |
||||
|
数值类型
|
数值 |
短整型 |
SHORT (SMALLINT) |
16 |
-32768 - 32767 |
|
|
整型 |
INT |
32 |
-2147483648 - 2147483647 |
|||
|
长整型 |
LONG (BIGINT) |
64 |
-9223373036854775808 - 9223373036854775807 |
|||
|
单浮点 |
FLOAT |
32 |
-3.40E+38 - 3.40E+38 |
|||
|
双浮点 |
DOUBLE |
64 |
-1.79E+308 - 1.79E+308 |
|||
|
时间日期 |
日期 |
DATE |
32 |
1年1月1日 - 9999年12月31日 |
||
|
时间 |
TIME |
32 |
0时0分0秒0毫秒 - 23时59分59秒999毫秒 |
|||
|
时间戳 |
TIMESTAMP |
64 |
1年1月1日0时0分0秒0毫秒 - 9999年12月31日23时59分59秒999毫秒 |
|||
表2.2 数据类型
2.3 全局数据库
在Laxcus大数据系统里,数据库被定义成“全局”的。
这个“全局”意味着每个数据库的名称,在整个主域集群里都是唯一的。不同意出现重叠现象,即使分属两个用户也不能够。比方,当A用户建立一个名为“Product”的数据库后。B用户再建立“Product”数据库将被系统拒绝。
採用全局数据库是出于简化系统设计和降低操作环节的考量。
这样节点在执行过程中,由于数据库不存在同名歧义的可能性,系统能够非常easy推断每个数据库和用户的相应关系,能够降低很多不必要的作业流程。
2.4 跨数据库操作
我们在进行数据结构规划设计时。经常须要定义一个或者几个数据库,再这些数据库之下,又定义不同需求的表,然后录入不同性质的数据。同一时候。我们还须要设置一些公共參数,把它们放在一个或者几个表里,为了便于管理和使用,又经常希望放在一个数据库里。在数据处理时。能够给分散在不同数据库下的数据表共同使用。
出于这种考虑,Laxcus大数据系统支持跨数据库的数据表操作。这样就形成了在一个用户账号下。在数据操作时。全部表与表之间。不用事先声明。就能够实现全然的互通互调用。在精简了系统设计和集中数据资源的同一时候,也降低了数据处理过程中非常多不必要的麻烦。方便了用户高速处理数据,提高了数据处理的灵活性和效率。
在实际应用中。这项功能对数据检索很有利,诸如连接查询 (Join)和嵌套查询(Sub select)这种操作。跨数据库操作不会出现数据混乱,由于它们都要接受Aid节点的管理,被Aid节点有序地依照所属条件分别运行。
2.5 固定表
在关系数据库里,表结构是能够随时改动变化的,可是在Laxcus,这项功能被停止使用。表结构一旦定义禁止改动。禁止的原因在于大数据所处的现实环境。试想一下,在一个由上千台计算机组成的集群环境里,假设同意改动表结构,会有什么反应?所有正在执行和关联的任务将被迫停止,新的任务将转入队列中堆积和等待。所有数据内容将依照新的表结构又一次组织和排列。
这样的变化和等待的过程,是不论什么一个大数据集群所不能承受的。囿于这样的现实情况。Laxcus规定,表的结构一旦正式确定不同意改动。
因为表的不可改动。同一时候被改变的还有对索引的定义。依照SQL规范。“CREATE INDEX”是在“CREATE TABLE”之后进行的操作。
如今将它们合并到一起,在定义列的时候,指定这个列是否成为索引。
对索引的解释,Laxcus也做了调整。
新的规定是,一个表中仅仅能有一个列成为主索引(Prime Index)和随意多个列的副索引(Slave Index)。副索引概念与SQL没有区别,主索引除了具有副索引的功能。主要用于指示数据排列位置,即将有同样值的列组织到一起。
例外的是,对于列存储模型,全部列成员,即使用户不定义索引,其列值也可以自己主动做为索引使用,同一时候不添加磁盘和内容开销。可是两种存储模型都须要定义一个主索引。由于涉及到数据内容在磁盘和内存上的排列。
另外。为适应大数据处理须要。在建表命令中添加了一批新的内容,这些參数主要在“Create Table”和“数据库名.表名”之间声明,列声明中也有新的定义。
这些參数都是可选的,不声明的时候。系统将使用默认值。
请參见图2.5和表2.5。
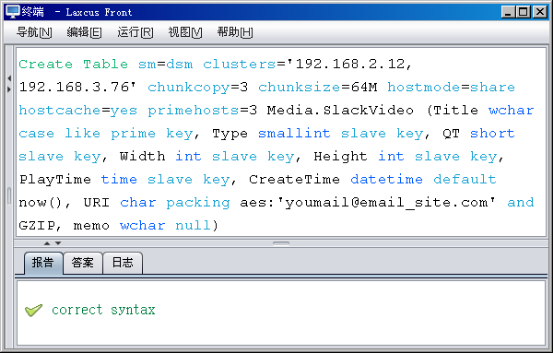
图2.5 数据库建表命令语句
|
keyword |
说明 |
|
SM |
存储模型。NSM:行存储模型;DSM:列存储模型 |
|
CLUSTERS |
子域集群,一个或多个Home地址,或者指定数字 |
|
CHUNKSIZE |
数据块尺寸,以兆为单位 |
|
CHUNKCOPY |
同质数据块数据,包含一个主块和随意个从块 |
|
HOSTMODE |
表对节点全部权。SHARE:共享主机;EXCLUSIVE:独亨主机 |
|
HOSTCACHE |
数据块缓存,依据热度由节点选择是否自己主动载入 |
|
PRIMEHOSTS |
表初始拥有的Data主节点数量,以后随数据诸量自己主动添加 |
|
NULL|NOT NULL |
支持空值或者否(适用全部数据类型) |
|
EMPTY|NOT EMPTY |
支持这值或者否(仅仅限字符串和字节数组) |
|
CASE|NOT CASE |
字符串大写和小写敏感或者否 |
|
LIKE|NOT LIKE |
字符串同意模糊查询或者否 |
|
DEFAULT |
列的默认值。依据类型支持数值、数组、字符串、SQL函数 |
|
PRIME KEY|SLAVE KEY |
主/从索引。如是数组类型,指定从0下标開始的索引长度 |
|
PACKING |
数组列内容的加密、压缩,若加密提供password |
表2.5 数据库建表keyword
2.6 取消视图
在SQL的定义中,视图是一个虚拟表。是对实体表和其他视图的关联和映射,做为一个数据描写叙述存在于系统中,被视为用户和实体表之间的过渡而存在。视图具有向用户屏蔽实体表数据结构的作用,也具有在改变表数据结构时,不用改变上层描写叙述的能力。
仅仅是在数据处理时,视图才将数据操作又一次定位到实体表上,然后向用户返回经过它处理重组后的新的数据集合。
假设遵守SQL这套定义,把视图转移到大数据环境,它在处理海量数据时,就要进行视图和表之间的关联和转换,这无疑将添加执行开销。减少处理效率,同一时候也加大了系统设计难度,与我们追求简单、快捷的设计初衷相悖。另外Laxcus为代替视图提供了一套新的技术方案:数据构建。这项技术提供了对一个表或者多个表的分析、组合能力。而且具有比视图更大的灵活性和高效率。另外一个更重要的原因是:在Laxcus体系里,用户、数据之间的概念和关系已经与关系数据库大不一样。关系数据库提供视图的初衷是向部分用户屏蔽表数据结构,或者改变表数据结构而不用改变上层表述,而Laxcus的用户拥有对自己数据的所有管理权和使用权。表的数据结构也是固定的。这种设计假设移植到Laxcus显然有悖常理。鉴于这些原因,综合比較之后,Laxcus取消了视图。
2.7 带Where子句的Select检索
在关系数据库上,SELECT检索不带WHERE语句将返回表下的所有记录。按此推理,计算机集群上的操作也应该返回一样的结果。可是这种操作转移大数据环境下。面对巨大的数据压力将导致灾难性的后果:计算机会由于瞬间暴发的庞大数据量,在还来不及处理时。就造成内存溢出和软件系统崩溃;网络也会由于这些瞬间涌现的巨大流量。出现数据风暴,造成网络堵塞。接下来的可能是大面积故障和连带的波及影响扩大化,造成整个集群的故障,从而被迫中断数据处理业务,造成不可挽回的损失。这种情况显然是不可接受的。另外,在现实的应用环境里,全网络全数据的检索操作事实上并没有太多实际意义。
由于上述原因。Laxcus对数据检索提出这种规定,主要的数据检索操作必须是“SELECT-FROM-WHERE”语句块,否则将视为非法。拒绝运行。这项检查工作将在Front节点上分析运行,然后在集群里还有进一步的推断。
2.8 数组列的压缩和加密
我们在使用非常多网络应用的时候,常常会在当中保存一些敏感和关键的内容,比方银行卡password、电子邮件账号、手机电话、家庭地址等私密性非常强的信息。这些信息,一般是不希望被别人知道的,包含网络管理人员。另一些内容,比如像网页或者文档这种文本数据,一般会非常长。假设採用明文的方式保存会占用大量磁盘空间,将其压缩再保存就能有效降低空间占用量,况且文本数据的压缩比率都是非常高的。
Laxcus提供了这样一个选项。能够对这类信息进行加密和压缩。见图2.5和表2.5,这里对格式进行说明。“Packing”是对数组列内容进行压缩和加密的keyword。压缩和加密能够同一时候声明,也能够任选其一声明,假设仅仅声明当中一种。要去掉连接它们的“AND”keyword。做加密声明时,同一时候须要提供password。password能够是不论什么语种的和不定长的字符串,在建表时会转换为UTF8码保存。压缩和加密的算法名称是固定的。已经支持的压缩算法有:GZIP、ZIP,以及加密算法:AES、DES、3DES、BLOWFISH。
数组列的压缩和加密由用户定义,在建表时输入。
在此后的处理过程中,算法和password也仅仅对用户可见。
特别声明:不管数组列是否被压缩和加密。都不影响其做为索引的使用。
2.9 事务
事务在2.0版本号是一个重要的模块,以管理器的形式运行在Aid网站上。
全部数据处理工作都被默认要求运行事务处理流程。就是它们在运行数据操作前,须要通过事务管理器的审核才干实施。事务申请是一个同步串行操作过程,採用队列的“先到先得”原则,总是由排在最前面的申请获得优先使用权。申请成功后的事务会被记录到管理器队列,作为兴许事务申请时的推断比較根据,直到它的数据处理工作完毕后。才从管理器队列中撤销。没有申请成功的事务将被挂起,直到前面的事务从队列中撤销后才被唤醒。
我们在兼顾大数据并发效率、平衡事务申请要求、保证事务操作精度这几个方面需求考虑下,依照事务操作范围,把事务分为三种类型:用户型事务、数据库型事务、表型事务。
用户型事务拥有操纵账号下所有资源的权力,数据库事务可以操作一个或者几个数据库以及下属所有表,表事务仅仅能操作一个或者几个详细的表。
三种事务在管理器上的地位是平等的,没有隶属关系。
使它们产生关联的是它们所绑定的资源。这是决定一个事务可以获得申请通过、还是被拒绝挂起的根据。
事务另外一个属性是操作状态。事务操作状态被分成“读”和“写”两种。
不论什么一个"写“事务生效。即表示和它关联的资源对象被锁定,不同意再申请,直到这个事务完毕,这些资源被解锁。兴许“写”申请才干生效。假设是“读”操作事务生效,被关联的资源仅仅做标记,供兴许全部事务參考,其他“写”事务仍然拥有锁定这些资源的权力。
综上所述,结合图2.9。在系统执行过程中。事务申请依照例如以下规则处理:
1.全部类型的"读"事务都能够共享存在。
2.假设队列都是“读”事务,兴许一个“写”事务能够获得批准。
3.假设队列中有“写”事务,兴许一个“写”事务仅仅要不与它们存在资源冲突,就能够获得批准。否则被拒绝挂起。
4.为了进一步提高数据库事务和表事务的并发效率,在它们之间有一个“数据库名称”比較。当这种两个"写“事务发生”数据库名称“冲突时。兴许“写”事务被挂起,即同名相互排斥。
5.假设一个事务同一时候存在“读写”两种状态时,将依照“写”事务规则处理。
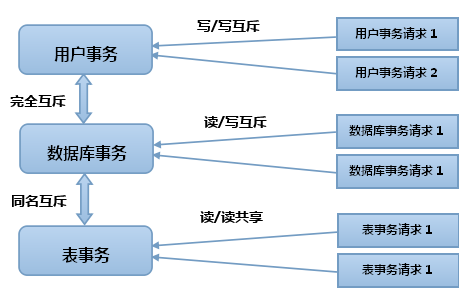
图2.9 Laxcus事务处理
2.10 分布描写叙述语言
分布描写叙述语言(简称DDL)開始于Laxcus 0.1版本号,经过0.x、1.x版本号加强后,在2.0版本号又得到进一步完好。分布描写叙述语言由大量命令组成。使用者在操作界面上输入字符语句命令语句,通过语法解释器解释后,转换成计算机指令,分发到集群上运行。分布描写叙述语言经过这几个版本号的完好,如今已经与Laxcus大数据管理系统高度集成,提供了全方位的管理、操纵集群能力,而且贯穿到集群的每个环节。我们设计分布描写叙述语言的目的在于简化操作人员的工作,希望实现“仅仅须要操作人员通知集群做什么。而不须要去知道集群怎么做”。经过这几个版本号的使用调查证明,分布描写叙述语言所带来的效果,已经成为Laxcus大数据管理系统简单、高效处理的基本保证。
下面我们对分布描写叙述语言的基本面貌做些简单的介绍。
2.10.1 三层结构模型
如图2.10.1所看到的。分布描写叙述语言是一个三层结构模型。命令从Front或者Watch节点发出。来自Front节点的命令属于用户命令,来自Watch节点的命令属于集群管理命令。不管是Front还要Watch,它们的命令都须要经过语法解释器翻译成计算机指令,才干发往集群。
用户命令在进入集群运行操作前,首先要通过网关节点(Aid、Call)的检查。在推断是正确而且有效后,网关节点会把这个命令分配给兴许相关节点,去运行数据处理和数据管理工作。
Watch节点由于位于集群内部。命令被翻译成计算机指令后。会直接发给与命令关联的节点去处理。
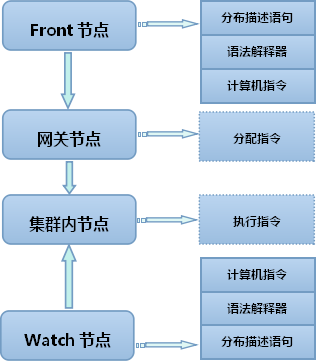
图2.10.1 三层结构模型
2.10.2 命令分类
如上所述。分布描写叙述语言中的命令分为两大类:集群管理命令、用户命令。
集群管理命令由管理员从Watch节点发出,用来控制、检查集群和节点的工作状态、分布资源。
用户命令由用户从Front节点发出,主要是运行数据操纵和数据管理。
由于分布描写叙述语言兼容SQL,SQL中的全部命令被划入用户命令队列里。
集群管理命令和用户命令在系统中是全然平行的,没有交集,也不同意互相使用。在权限等级上,全部集群管理命令都拥有比用户命令更高的操作权限。这体如今命令的被调用过程中。比方当两类命令同一时候出如今一个节点时,集群管理命令总是比用户命令优先获得运行的权力。
只是在系统实际运行时,在集群中工作的基本都是用户命令,集群管理命令偶尔出现,并且也不会产生太多计算压力,所以这样的优先权并不easy体现出来。
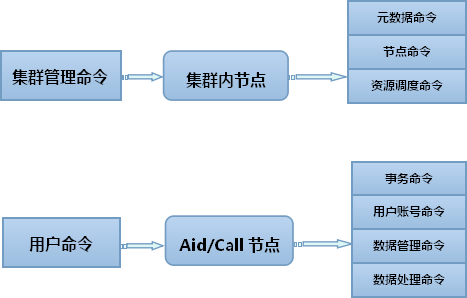
图2.10.2 集群管理命令和用户命令
2.10.3 自己定义參数
在过去几个版本号的演进过程中,有越来越多的用户要求系统提供一种在命令中存在、不须要系统理解、由用户自行处理的数据。这些数据的表现上。有时候可能是一个数字,有时候是一个字符串。也可能是一张图片。或者其他经过格式化处理的信息。
它们成为命令的一部分,參与到用户的数据处理工作中。
顺应这一项发展需求。同一时候也为了规范化数据样式,提高数据处理效率。在2.0版本号中,分布描写叙述语言正式支持自己定义參数。而且对自己定义參数做出这种规定:參数格式由Laxcus提供,内容由用户自己解释。如图2.10.3所看到的,自己定义參数被分解成三部分:名称、类型、数值。当中名称由用户自由定义,类型是系统规定,类型在名称之后。被括号包围。
类型分为数字型和数组型两组。
数字类型包含bool、short、int、long、ushort、uint、ulong、float、double,数组类型包含string(char)、byte、image、object。为保证传输过程时的内码一致,用户输入的string数值会被转为UTF8编码。假设自己定义參数是一个数组类型。那么数值须要被单括号包围,假设自己定义是数字类型则不须要。这种样式的自己定义參数被语法解释器解释后,将存入到命令的自己定义參数队列。随命令一起分发到集群上,在须要它发挥作用的位置參与数据处理工作。
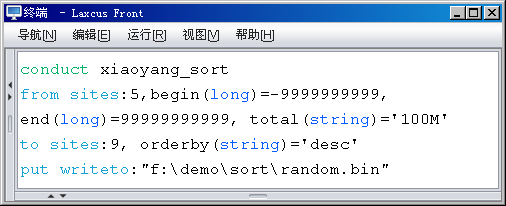
图2.10.3 分布描写叙述语言自己定义參数