GuozhongCrawler QQ群 202568714
教程源代码下载地址:http://pan.baidu.com/s/1pJBmerL
GuozhongCrawler内置三大PageDownloader。各自是採用HttpClient作为内核下载的DefaultPageDownloader、採用HtmlUnitDriver作为内核下载WebDriverDownloader、採用ChromeDriver调用浏览器作为内核下载的ChromeDriverDownloader。
当中DefaultPageDownloader和WebDriverDownloader在实际开发中用的最好性能也是最好的。而ChromeDriverDownloader尽管性能不佳。可是ChromeDriverDownloader可以灵活调用浏览器抓取。
在调试过程中使用ChromeDriverDownloader可以看到爬虫真实的执行流程确实为开发增添了不少乐趣。
首先我们来看下怎样使用大三下载器。
以及它们各种什么特点。
一、DefaultPageDownloader
DefaultPageDownloader既然是採用HttpClient作为内核下载器。
那么他必须兼容全部httpClient应该有的功能。
样例我们以职友企业网抓取为样例。我们准备了阿里巴巴和淘宝网两个公司的主页URL。并通过CrawTaskBuilder注入到CrawlTask中。
prepareCrawlTask时指定使用DefaultPageDownloader作为下载器。
String alibaba = "http://www.jobui.com/company/281097/";
String taobao = "http://www.jobui.com/company/593687/";
CrawTaskBuilder builder = CrawlManager.getInstance()
.prepareCrawlTask("职友网爬虫", DefaultPageDownloader.class)
.useThread(2)//使用两个线程下载
.injectStartUrl(alibaba, PageCompanyDescript.class)
.injectStartUrl(taobao, PageCompanyDescript.class)
.usePageEncoding(PageEncoding.UTF8);
CrawlTask spider = builder.build();
CrawlManager.getInstance().start(spider);
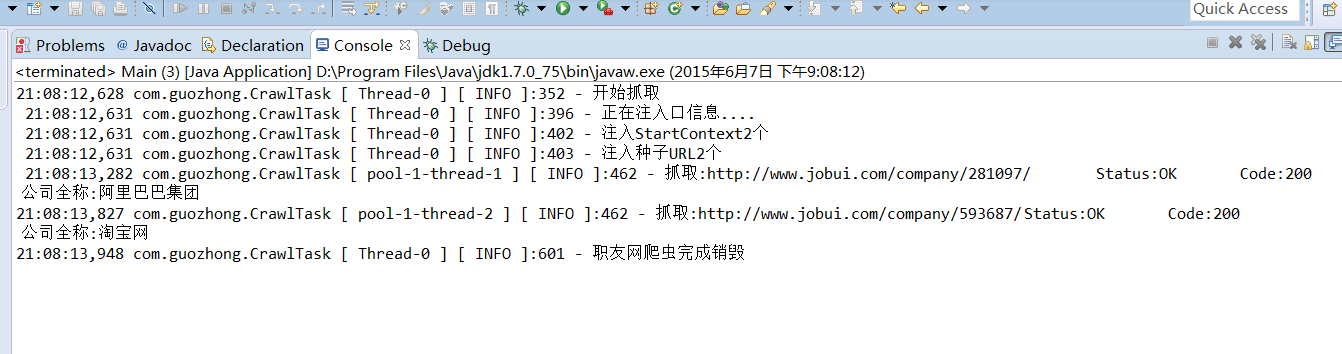
PageCompanyDescript.java的实现我们如今临时仅仅输出解析出来的公司名称代码例如以下
public class PageCompanyDescript implements PageProcessor {
@Override
public PageScript getJavaScript() {
return null;
}
@Override
public Pattern getNormalContain() {
return null;
}
@Override
public void process(OkPage page, StartContext context,
List<BasicRequest> queue, List<Proccessable> objectContainer)
throws Exception {
Document doc = Jsoup.parse(page.getContent());
Element h1 = doc.select("h1[id=companyH1]").first();
if(h1 != null){
System.out.println("公司全称:"+h1.text());
}
}
@Override
public void processErrorPage(Page arg0, StartContext arg1)
throws Exception {
}
}
OK。如今測试代码就已经完毕。我们执行。
二、WebDriverDownloader
使用WebDriverDownloader事实上仅仅要把main方法中的prepareCrawlTask("职友网爬虫", DefaultPageDownloader.class)
改成prepareCrawlTask("职友网爬虫", WebDriverDownloader.class)就可以完毕WebDriverDownloader的设置。
为了体现差别我们在PageCompanyDescript中实现getJavaScript方法来运行一段js代码。getJavaScript实现例如以下:
@Override
public PageScript getJavaScript() {
return new PageScript() {
@Override
public void executeJS(HtmlUnitDriver driver) throws Exception {
WebElement element = driver.findElementById("companyH1");
driver.executeScript("arguments[0].innerHTML='WebDriverDownloader支持运行JavaScript';", element);
}
};
}
OK执行之后的结果例如以下图。

10:10:23,572到 10:10:32,056中间相差了9s的时间。这是由于webdriver的js引擎在jvm中运行确实过慢。但大规模抓取过程中还是建议採用抓包抓取的方式。
三、ChromeDriverDownloader
ChromeDriverDownloader和WebDriverDownloader功能上一样。
仅仅是下载会调用谷歌浏览器。用户须要安装谷歌浏览器和下载chromedriver。放在谷歌浏览器的安装文件夹。
我的文件夹是D:program files (x86)Chrome。
那么chromedriver的路径是D:program files (x86)Chromechromedriver.exe。
这里解释下ChromeDriver是Chromium team开发维护的。它是实现WebDriver有线协议的一个单独的服务。ChromeDriver通过chrome的自己主动代理框架控制浏览 器。ChromeDriver仅仅与12.0.712.0以上版本号的chrome浏览器兼容。
chromedriver下载地址:https://code.google.com/p/chromedriver/wiki/WheredAllTheDownloadsGo?
tm=2
之后我们改动main方法中的代码:
//设置chromedriver.exe路径
System.setProperty("webdriver.chrome.driver", "D:\program files (x86)\Chrome\chromedriver.exe");
String alibaba = "http://www.jobui.com/company/281097/";
String taobao = "http://www.jobui.com/company/593687/";
CrawTaskBuilder builder = CrawlManager.getInstance()
.prepareCrawlTask("职友网爬虫", ChromeDriverDownloader.class)
.useThread(2)//使用两个线程下载
.injectStartUrl(alibaba, PageCompanyDescript.class)
.injectStartUrl(taobao, PageCompanyDescript.class)
.usePageEncoding(PageEncoding.UTF8);
CrawlTask spider = builder.build();
CrawlManager.getInstance().start(spider);
再次运行会弹出谷歌浏览器界面,我们能够看到爬虫抓取过程了。
控制台输出

可能你会注意到。
我们用了useThread(2)//使用两个线程下载。为什么没有出现两个谷歌浏览器同一时候抓。这里解释是由于我们注入种子URL的方式是使用injectStartUrl它会注入2个StartContext。而StartContext好比是一批种子URL的上下文。同一时间是不能同一时候使用的。
为此GuozhongCrawler提供了DynamicEntrance的概念实现多个种子URL同一时候共享一个StartContext的功能。想了解DynamicEntrance的话,请继续关注后期GuozhongCrawler系列教程。谢谢大家!
GuozhongCrawler QQ群 202568714