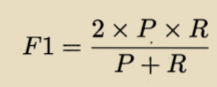混淆矩阵:
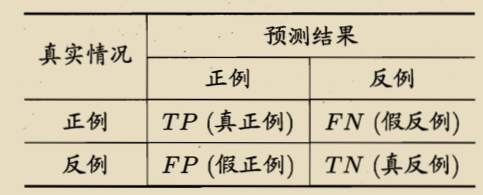
混淆矩阵的正例一般是我们需要关注的,常用1表示,反例是我们不关注的,常用0表示。例如:一个需要识别借贷需求的人的分类任务中,正例表示有借贷需求的人,反例表示没有借贷需求的人。下面定义一些基于混淆矩阵的度量分类任务的方法:
查准率(Precision):
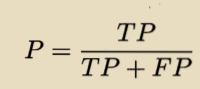
基于这个借贷需求识别任务说明:所有识别出来的正例中真实正例的占比,越高越好。
召回率(Rcall):
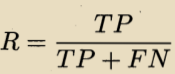
基于这个借贷需求识别任务说明:所识别出来的正例在在实际正例中的占比,越高越好。
当然TP越高,二者都高。但是现实中这两个一般一个高,另一个就低。在借贷需求识别任务中识别出的正例会交给电话销售,如果电话销售成本高,我们当然希望识别出的正例中真实正例越高越好,即优先保证查全率高;如果电话销售的成本低,那么有限保证召回率高。
F1度量: