作业链接#
https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1816W/homework/2085
1.Fork仓库的Github项目地址:#
https://github.com/wyz0918/PersonProject-Java
2.PSP表格#
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 400 | 568 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 20 |
| • Design Review | • 设计复审 | 10 | 8 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 30 | 30 |
| • Coding | • 具体编码 | 150 | 180 |
| • Code Review | • 代码复审 | 10 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 240 |
| Reporting | 报告 | 80 | 120 |
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 500 | 708 |
3.计算模块接口的设计与实现过程#
一、相关类设计
- 一个Main类,用于处理文件输入输出,Main类对象直接调用Lib类中的方法。
- 一个Lib类作为工具类,用于计算字符数、行数、单词总数,出现次数等静态方法。
二、相关函数设计
1、Main类中的方法
- readFile方法实现从控制端口读入文件名,并且返回文件对象。
- writeFile方法实现把信息写入指定文件。
2、Lib类中的方法
- countChars方法实现计算字符数。
- countLines方法实现计算行数。
- countWords方法实现计算单词数。
- countTop10方法实现单词先从出现频率降序排列,再按照若相同频率按照字典序升序排列并且找出符合条件的前10个单词。
三、关键代码和算法
-
单词的划分
单词的划分需要String.split()方法来通过对空格和其他字符进行划分,并进行单词的匹配,可以使用正则表达式。若使用macher.find(),matcher.group()方法则会把不符合要求的单词计算在单词数里,比如123file。
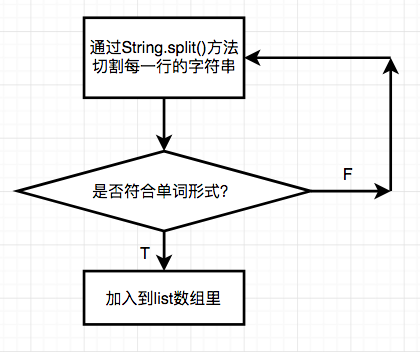
-
字符数的计算
字符数因为包括换行符空格等,因此若用readline(),则会忽略换行符,因此需要用read(),把全部字符当成一个字符串并返回。 -
行数的计算
行数需要去掉都是空格的行,因此使用trim(),并且用isEmpty()判断。 -
单词数的计算
单词总数只需要计算满足正则表达式的单词即可,其中包括重复的单词。 -
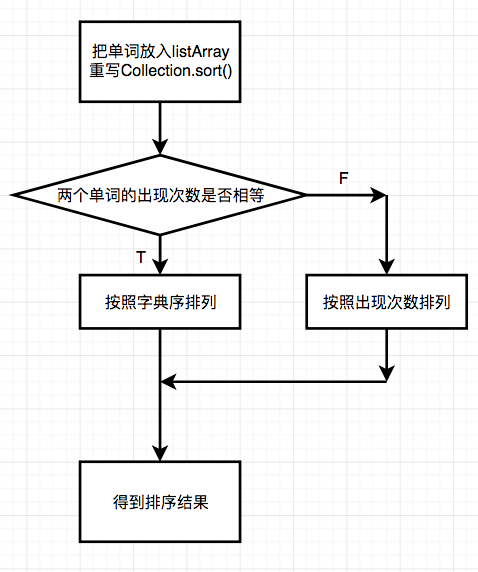
单词的排序
单词的排序需要按照从出现频率降序排列,再按照若相同频率按照字典序升序排列,主要使用了Collection.sort()方法。
4.计算模块接口部分的性能改进#
改进计算模块性能上花费了120分钟左右。
Jprofiler性能测试:
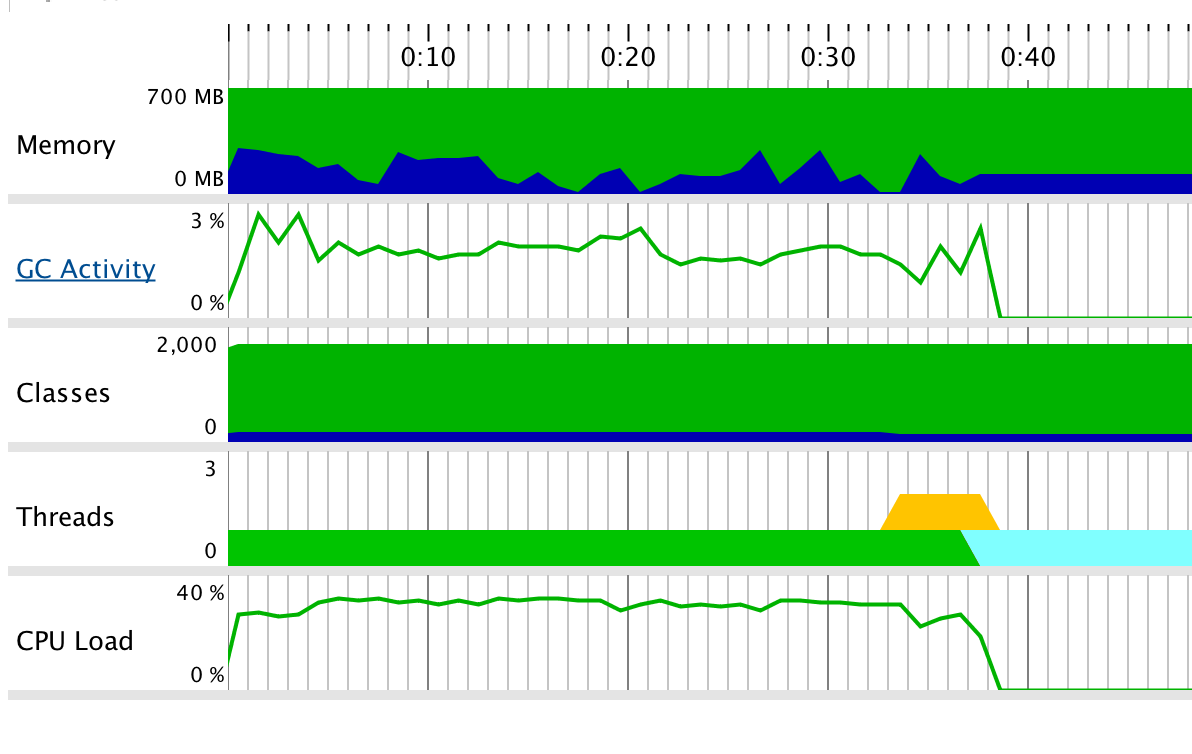
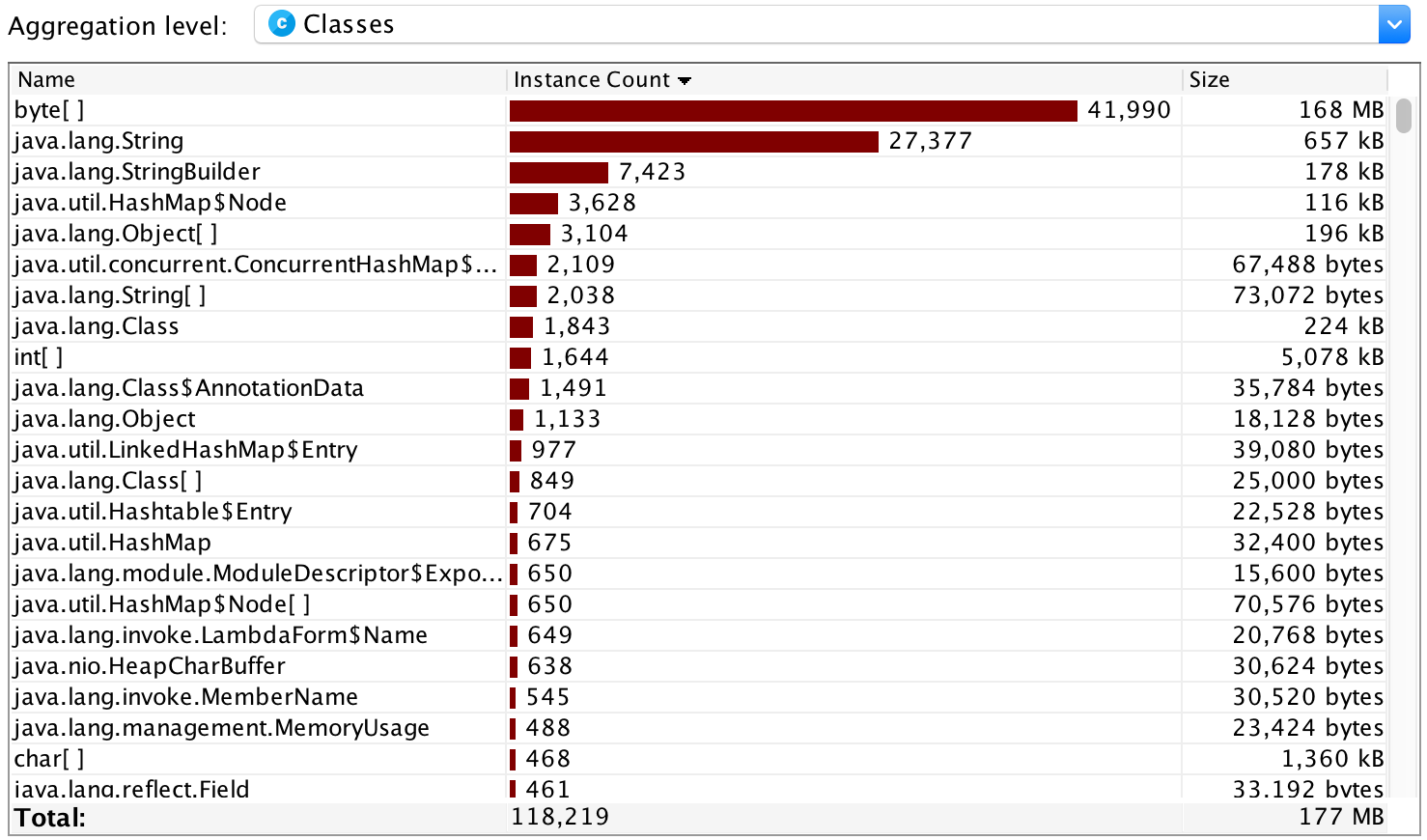
从性能分析图可知String类开销较大
改进的思路:使用正则表达式减少判断的复杂度,使用hashmap提高查询速度。
5.计算模块部单元测试展示#
input.txt文件:
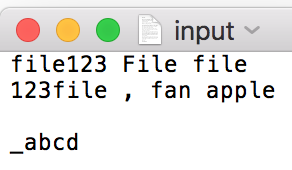
测试的思路:将input.txt文件作为参数输入,对照返回值是否等于预期。
一、countChars方法单元测试:
@Test
public void testCountChars() {
File f = new File("input.txt");
assertEquals(Lib.countChars(f),44);
}
二、CountLines方法单元测试:
@Test
public void testCountLines() {
File f = new File("input.txt");
assertEquals(Lib.countLines(f),3);
}
三、CountWords方法单元测试:
@Test
public void testCountWords() {
File f = new File("input.txt");
assertEquals(Lib.countWords(f),5);
}
四、CountTop10方法单元测试:
@Test
public void testCountTop10() {
File f = new File("input.txt");
String[] str = {"file","abcd","apple","file123"};
String[] str2 = {"2","1","1","1"};
ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>();
list = Lib.countTop10(f);
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getKey(),str[i]);
}
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getValue().toString(),str2[i]);
}
}
测试的思路:将input.txt文件作为参数输入,对照List中存储的值看是否符合预期的结果即可,我用了循环一个个进行比对,能比较全面地覆盖测试用例。
三、测试覆盖率截图:


6.模块部分异常处理说明#
- 读入文件时若失败则抛异常
代码:
public static int countChars(File f) {
int characters = 0;
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(f));
while (br.read() != -1) {
characters++;
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
错误对应的场景:当读入文件失败
7.运行测试#
输入文件:
输出文件:
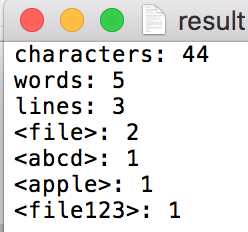
8.收获与体会#
这是我第一次比较系统地开发一个项目,收获非常多,首先发现了前期的规划非常重要,当明确了需求和思路,进行相关代码的设计后,编码的效率才会提高,而不应该闷头就敲代码。这次的代码用到了正则表达式,也是最近编译原理有着重讲解的内容,能实际运用加深了对它的理解。另外代码的规范也非常重要,这也是我需要改进的地方,面向对象的思想理解的不够深刻,刚开始只写出一个类,并没有更加细致地划分,后面重新进行了优化。