本篇博客的目录:
一:put方法源码
二:get方法源码
三:rehash的过程
四:总结
一:put方法的源码
首先,我们来看一下segment内部类中put方法的源码,这个方法它是segment片组的,也就是我们在用concurrentHash的put方法的时候,实际上它会取得key的hashcode值,再计算它的hash,然后它会选择一个片组,进入segment中的这个方法。所以我们根本上要看的是这个方法:
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
从这里也可以看出concurrentHashMap不允许值为null,否则会抛出NullPointetException.
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } }
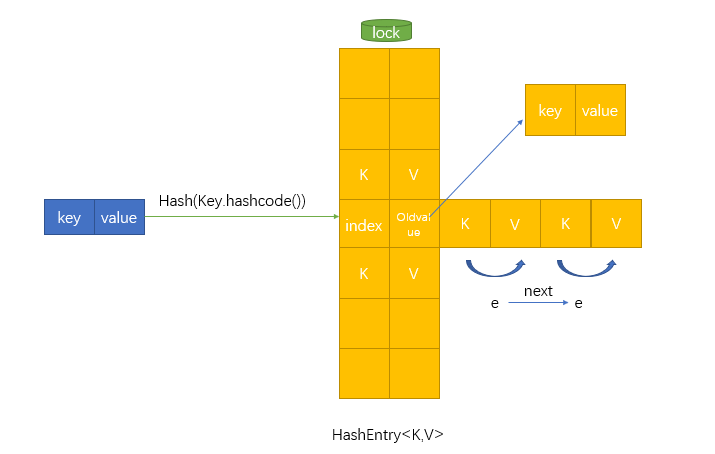
调用put方法之后,它首先是lock()上锁,防止多个线程同时put,可能会有并发的问题。上锁的话可以保证每次put一个key的时候,其他线程将会无法进入这个片组,它会去选择另外一个segment,这就是分段的 好处。并不简单粗暴的采用synchronized的方法阻塞其他线程。接下来是取它的元素多少,给它+1(只添加一个元素)每次新加元素的时候都要去判断它是否超过了数组的扩容临界值,如果超过了,就要对它进行扩容操作,也就是reHash,或者叫做"Hash再置"的过程。这里我们先略过,暂且不分析。往下走,接下来是取得它内部的table数组,就是封装键值对的数组,根据传入的hash值和数组的长度减去1进行与运算,找到一个预放置数组的位置,然后再找它对应的数组元素,再通过一个while循环去遍历这个节点上的链表,去寻找这个元素,如果找到这个元素了(证明欲放入的元素已存在)。然后取得它的值,判断onlyifAbsent,这个字段按照字面意思翻译为:是否缺席,也就是说放入一个元素前用这个字段是决定它是否存在,上面的 方法传入的参数为fasle,也就是它存在。那么就取它的值赋值给这个元素(替换它的值)。如果它不存在,增加修改次数,然后在这个位置上新new一个元素放进去,并把加+1的值赋给count,最后再返回旧值。最后在finally里进行解锁。以下是图示:
二:get方法的源码分析
get方法需要传入一个key和hash。它的原理同样等同于上面讲的put方法:
public V get(Object key) {//根据key获取value int hash = hash(key.hashCode());//拿到键的hash值 return segmentFor(hash).get(key, hash);//调用segmentFor方法传入key和hash值得到value }
通过key的hashcode值,传入segment中的get方法:
V get(Object key, int hash) { //根据指定的key和hash值获取value值 if (count != 0) { // 如果count不为0 HashEntry<K,V> e = getFirst(hash);//根据传入的hash获取链表中的第一个键值对 while (e != null) {//如果这个键值对不为null if (e.hash == hash && key.equals(e.key)) {//如果该键值对的hash值等于方法传入的Hash,并且该键与第一个Hashentry对象通过equals方法比较相同 V v = e.value;//取第一个hashEntry对象的值 if (v != null)//如果该值不为null return v;//返回值 return readValueUnderLock(e); // 调用readValueUnderLock方法返回对象的值 } e = e.next;//指向下一个键值对,这里相当于去遍历整个链表,直到找到key对应的值 } } return null;//如果找不到,返回null }
get方法首先判断的是数组中的元素是不是0,如果不是0继续往下走,然后通过传入的hash值去获取他的第一个元素,如果这个元素不为null,说明可以找到这个hash对应的元素。否则就返回null。然后通过while循环再去判断hash值是否相同,key是否相同,在两者相同的情况下,获取该元素的value。如果这个value不为null,就返回这个值。如果它为null,调用readValueUnderLock()方法,这里主要是考虑到一点,如果再它取值的过程中,如果这个值正在被put进去。再来看看readValueUnderLock方法:
V readValueUnderLock(HashEntry<K,V> e) {//在锁中读取指定的HashEntry值
lock();//上锁
try {
return e.value;//返回Hashentry中的value
} finally {
unlock();//解锁
}
}
这里专门做了一个上锁的过程,主要是为了防止获取值的过程这个值正在被添加,此刻就会对取值进行上锁,那么put方法就会被阻塞,只得等它get完毕再put,那么又会有一个新的问题产生:比如假如一个线程现在要put一个键值对:put("a","sunday"),而map里面已经存在一个“a”,"Monday";而另外一个线程正在get("a"),此时得到的值是null还是“sunday”,还是monday?回答这个问题,只需要看这里transient volatile HashEntry<K,V>[] table;table是volatile的,所以它可以及时的同步它的Hashentry,它可以保证取到最后一次put的值。
三:rehash的过程
rehash的过程就是扩容的过程,每次要put一个值的时候,都要调用这个方法给当前的容量+1去检查是不是超过最大容量。我们来看一下它的源码,分析一下这个过程:
void rehash() HashEntry<K,V>[] oldTable = table; //取当前的数组设为旧数组 int oldCapacity = oldTable.length;//取旧数组的数组的长度 if (oldCapacity >= MAXIMUM_CAPACITY)//判断旧数组的容量是否大于最大容量(保证当前的数组不越界) return;//如果是 结束 HashEntry<K,V>[] newTable = HashEntry.newArray(oldCapacity<<1);//以旧数组的长度的2倍创建一个新数组 threshold = (int)(newTable.length * loadFactor);//设置临界值为新数组的长度乘以加载因子 int sizeMask = newTable.length - 1;//设置大小的掩码为新数组的长度减去1 for (int i = 0; i < oldCapacity ; i++) {//遍历旧数组,也就是复制数组的过程 // We need to guarantee that any existing reads of old Map can // proceed. So we cannot yet null out each bin. HashEntry<K,V> e = oldTable[i];//取数组的元素 if (e != null) {//如果不为null HashEntry<K,V> next = e.next;//往下遍历该节点上的链表 int idx = e.hash & sizeMask;//用该节点的hash乘以大小的掩码获取一个位置值 // Single node on list if (next == null)//如果该节点上没有形成链表 newTable[idx] = e;//把新该元素的值设为新数组的计算出来的位置的值 else { //如果该节点有连续的链表 // Reuse trailing consecutive sequence at same slot HashEntry<K,V> lastRun = e;//取该节点 int lastIdx = idx;//取计算出来的位置 for (HashEntry<K,V> last = next; last != null; last = last.next) {//遍历该链表 int k = last.hash & sizeMask;//通过该元素的hash值与size掩码进行与运算出来一个位置值 if (k != lastIdx) {//如果两个值不相同 lastIdx = k;//把k的值赋值给lastIdx lastRun = last;//把当前值设为lastRun的值 } } newTable[lastIdx] = lastRun;//用得出的值赋值给新数组 // Clone all remaining nodes for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {//遍历循环该链表中的元素 int k = p.hash & sizeMask;//取元素的hash值与size掩码进行与运算计算出它的位置 HashEntry<K,V> n = newTable[k];//取计算出来的位置元素的值 newTable[k] = new HashEntry<K,V>(p.key, p.hash, n, p.value);//调用HashEntry的构造方法新建一个新HashEntry对象 } } } } table = newTable;//把新数组设定为片组维持的table }
上面这个方法主要是对数组扩容的过程做一个简单的分析,根据代码可以发现以下几点问题:
1:数组扩容的时候是把原数组的长度*2(左移1位)
2:然后去遍历旧数组,这里分为两种情况,旧数组的节点存在链表和不存在链表,如果不存在链表,会把当前节点的hash与它的index进行与运算得出一个位置,然后把它放入到新素组的该位置
3:如果存在链表:会遍历当前的链表,然后把旧数组的当前值设为新数组计算出来的值后,再遍历该链表,把链表里面的值的key和value还有index位置新构建一个元素放入到新数组中
4:最后再把这个新数组代替原来的数组,让segment维护这个新数组
四:总结
本篇博客主要是分析了conucurrenhashMap的put和get方法,还有rehash的过程,因为这三个方法高频率使用,在代码的分析过程中,主要是体会concurrenHashMap的数据结构设计以及具体的放值和获取值它中间对于多线程是如何处理的,它是如何处理多线程访问的安全的,相信经过源码分析,对于concurrenhashmap有一个更加深入的理解,以便在程序中更好的使用它。