- 安装
- 创建项目
- scrapy startproject projectname
- 原理
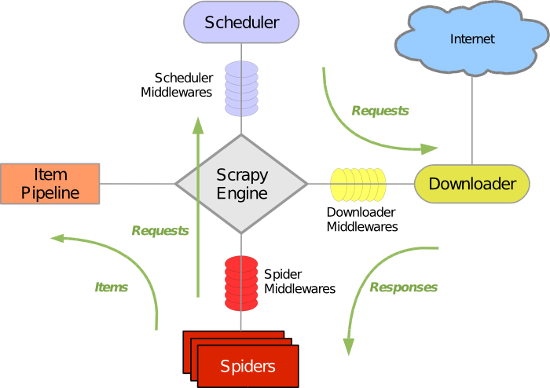
- scrapy.cfg
- 一般不改。只是settings.py的位置、deploy的Project名称。
- settings.py
- 一些配置。一般也就改改ROBOTSTXT_OBEY、COOKIES_ENABLED、DEFAULT_REQUEST_HEADERS什么的。
- middlewares.py
- 可以重写许多方法。比如在process_request(self, request, spider)增加cookie
- spiders/
- 可以放多个spider。
- 每个XxxSpider均继承自scrapy.Spider
- name:spider的名称,可用于运行时当做参数指定要执行哪个spider
- allowed_domains:允许爬取的域名。避免爬到其他网站去了?
- start_urls:数组。开始进行爬取的根url。
- 自定义parse(self, response)函数
- 从response中使用xpath解析、组织出数据,然后放到自己定义了结构的item对象中,然后通过yield item完成工作,
- start_requests(self)
- 相当于这个spider的入口函数,默认实现是用parse(self, response)函数循环处理start_urls中的所有入口地址
- 因此如果在这个函数中为请求加入cookie,注意也要同样循环处理start_urls中的所有入口地址
- parse(self, response)
- 默认只有这一级,但其实可以自定义多级,用于处理如先抓列表页再抓详情页的需求
- 返回值如果是yield item,那么就是结束了这一次请求,并已提取出item交由对应的pipeline处理
- 返回值如果是yield Request,那么就是进行下一层的请求和处理,比如前面说的先抓列表页再抓详情页的需求
- items.py
- 可以定义多个XxxItem类
- 每个XxxItem类都继承自scrapy.Item
- 可以定义业务所需的多个字段,如id = scrapy.Field()
- pipelines.py
- 必须打开settings.py中的ITEM_PIPELINES开关,其中包含多个值,都是pipelines.py中定义的pipeline
- init(self)
- 自定义process_item(self, item, spider)函数
- 对spider抓取、解析并传过来的item进行进一步操作,如持久化。
- spider_closed(self, spider)
- 运行
- scrapy crawl spidername -o items.json
- spidername是spiders目录下某个想要运行的spider的名字的前半部分,比如想运行cnblogs_spiders.py的话,就用命令scrapy crawl cnblogs。
- 即使是没有实现item对应的pipeline,也可能用默认的持久化行为存到items.json中,使用 -o items.json参数即可。
- 调试
- 使用cmd执行scrapy命令的话,不便于调试
- 增加一个start.py,用来起一个进程运行爬虫。
- 貌似调试不到pipelines.py里面去
import scrapy
from scrapy.crawler import CrawlerProcess
from spiders.cnblogs_spider import CnblogsSpider
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(CnblogsSpider)
process.start() # the script will block here until the crawling is finished
- 其他
- settings.py中的ROBOTSTXT_OBEY
- 这是因为业内有个robot协议,被爬取的网站可以通过在robots.txt中设置规则,不允许爬取其中某些资源。
- 默认为True。也就是说Scrapy默认是遵循robot协议的。如果爬取了禁止的资源,就会出现Forbidden by robots.txt错误。这时如果开发者坚持要爬取,那么就要把这个值改成False。
- 自动登陆
- 方法一:先访问登录页登陆
- 在抓取数据之前,先访问登陆界面进行Form登陆,然后转回抓数据的入口地址继续进行。
- 问题是,很多网站有反爬取措施,比如验证码、回答问题等。绕过比较麻烦。。。
- 方法二:先直接手动登陆再将Cookie信息放到抓取请求中
- 有多种方式可以往请求中放Cookie信息,比如在settings.py和middlewares.py中。但貌似比较靠谱的是重写start_requests方法(其实也能修改header等信息)。
- 问题是,每次都要手动更新一下Cookie信息,有点麻烦,不过还能接受。。。
# -*- coding: utf-8 -*-
import scrapy
from BlogCrawler.items import CnblogsPostItem
from scrapy.http import Request
class CnblogsSpider(scrapy.Spider):
# spider name
name = 'cnblogs'
# allowed domains
allowed_domains = ['i.cnblogs.com']
# entry urls
start_urls = [
'https://i.cnblogs.com/posts',
'https://i.cnblogs.com/posts?page=2',
'https://i.cnblogs.com/posts?page=3',
'https://i.cnblogs.com/posts?page=4',
'https://i.cnblogs.com/posts?page=5',
'https://i.cnblogs.com/posts?page=6',
'https://i.cnblogs.com/posts?page=7',
'https://i.cnblogs.com/posts?page=8',
'https://i.cnblogs.com/posts?page=9',
'https://i.cnblogs.com/posts?page=10',
'https://i.cnblogs.com/posts?page=11',
'https://i.cnblogs.com/posts?page=12',
'https://i.cnblogs.com/posts?page=13',
'https://i.cnblogs.com/posts?page=14',
'https://i.cnblogs.com/posts?page=15',
'https://i.cnblogs.com/posts?page=16',
'https://i.cnblogs.com/posts?page=17',
'https://i.cnblogs.com/posts?page=18',
'https://i.cnblogs.com/posts?page=19',
'https://i.cnblogs.com/posts?page=20',
'https://i.cnblogs.com/posts?page=21',
'https://i.cnblogs.com/posts?page=22',
'https://i.cnblogs.com/posts?page=23',
'https://i.cnblogs.com/posts?page=24',
'https://i.cnblogs.com/posts?page=25',
'https://i.cnblogs.com/posts?page=26'
]
# def start_requests(self):
# url = 'https://account.cnblogs.com/signin'
# data = {
# 'email': 'wangyeping1988',
# 'password': 'bk1517P@ssword',
# }
# request = scrapy.FormRequest(url, formdata=data, callback=self.parse_page)
# yield request
#
# def parse_page(self, response):
# url2 = 'http://www.renren.com/880792860/profile'
# request = scrapy.Request(url2 ,callback=self.parse_profile)
# yield request
# def start_requests(self):
# headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0"}
#
# cookies = {
# '.CNBlogsCookie': '6E0D581D816B40292F2CB163F9E2F6103933AE513E86496338B4D8098A447EF63939A0742F7BE1D09364AC1F46272E1B53175A0051B2F2E21476A6051F5FDD91E83A0AED5B2DA4AE02AD96225882AAA12602975F5AB90A169A851961F9B37D620F8C4D34',
# '.Cnblogs.AspNetCore.Cookies': 'CfDJ8BQYbW6Qx5RFuF4UTI7QvU118ut7nAbYfnRl0pAOtKCjq7-cwYn6CHWAbA4QwiOkwSvZ1jQu1PYse-z8i-D_Sl-rkl63Nvg_1w-vFssT77vMeEvCbSy2uwWYWHizRZbSazW4aoSLECfVWxioywacv3ZCzryhWkSfV2OKd-6EmsAnijvZ59eW1kYNH1keRodIMGM7k9Il2OvnOVOWSQysJbQPoYrR1uvHPY62avfQdQVhjHt7JhXhz5euovH6kVgZqFeIjUTCyqR6jc1LfS488Kr7-wVb-VMoLGYJFHKW_P2gEwzEImLJg3vYU-_Pp0NH333rhEiKaDnIHS3Y-WUpgaY9tAXSswLYTPFWCuBAe5SeY9nbRQqU9EJuix_fA0StJaNS1Nbc9MoW4LhRxctWJ_8HmnKhjuKW40d4bewALIJpJYot2X8FsS-NTr0LaPsJ4rAAS-zp4K9vlpKW_SsPe29STe_GJ0VKB0p2C18sX7WC',
# 'SERVERID': '04ead23841720026ba009cb4f597ec8c|1566653061|1566652046',
# '__gads': 'ID=ae065093c3816478:T=1523979454:S=ALNI_MYA9AUiW8F72qKRLOTLGedFqt2nLw',
# '_ga': 'GA1.2.1968144735.1498924730',
# '_gid': 'GA1.2.466366568.1566609068'
# }
#
# yield Request(detailUrl, headers=headers, cookies=cookies, callback=self.detail_parse, meta={'myItem': item},
# dont_filter=True)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
cookies={
'.CNBlogsCookie': '6E0D581D816B40292F2CB163F9E2F6103933AE513E86496338B4D8098A447EF63939A0742F7BE1D09364AC1F46272E1B53175A0051B2F2E21476A6051F5FDD91E83A0AED5B2DA4AE02AD96225882AAA12602975F5AB90A169A851961F9B37D620F8C4D34',
'.Cnblogs.AspNetCore.Cookies': 'CfDJ8BQYbW6Qx5RFuF4UTI7QvU118ut7nAbYfnRl0pAOtKCjq7-cwYn6CHWAbA4QwiOkwSvZ1jQu1PYse-z8i-D_Sl-rkl63Nvg_1w-vFssT77vMeEvCbSy2uwWYWHizRZbSazW4aoSLECfVWxioywacv3ZCzryhWkSfV2OKd-6EmsAnijvZ59eW1kYNH1keRodIMGM7k9Il2OvnOVOWSQysJbQPoYrR1uvHPY62avfQdQVhjHt7JhXhz5euovH6kVgZqFeIjUTCyqR6jc1LfS488Kr7-wVb-VMoLGYJFHKW_P2gEwzEImLJg3vYU-_Pp0NH333rhEiKaDnIHS3Y-WUpgaY9tAXSswLYTPFWCuBAe5SeY9nbRQqU9EJuix_fA0StJaNS1Nbc9MoW4LhRxctWJ_8HmnKhjuKW40d4bewALIJpJYot2X8FsS-NTr0LaPsJ4rAAS-zp4K9vlpKW_SsPe29STe_GJ0VKB0p2C18sX7WC',
'SERVERID': '04ead23841720026ba009cb4f597ec8c|1566653061|1566652046',
'__gads': 'ID=ae065093c3816478:T=1523979454:S=ALNI_MYA9AUiW8F72qKRLOTLGedFqt2nLw',
'_ga': 'GA1.2.1968144735.1498924730',
'_gid': 'GA1.2.466366568.1566609068'
},
callback=self.parse
)
def parse(self, response):
"""1. post list page"""
edit_page_url = 'https://i.cnblogs.com/EditPosts.aspx?postid={0}&update=1'
post_list_items = response.xpath('//tr[contains(@id,"post-row-")]')
for postListItem in post_list_items:
try:
tr_id = postListItem.xpath('@id').extract_first()
if tr_id:
yield Request(edit_page_url.format(tr_id[9:len(tr_id)]), callback=self.parse_edit_page)
except(IndexError, TypeError):
continue
def parse_edit_page(self, response):
"""2. post edit page"""
post_title = response.xpath('//input[@id="Editor_Edit_txbTitle"]/@value').extract_first()
post_content = response.xpath('//textarea[@id="Editor_Edit_EditorBody"]').xpath('text()').extract_first()
item = CnblogsPostItem()
item['title'] = post_title
item['content'] = post_content
yield item