-
Hive的数据查询
-
Hive的聚合函数
1. Hive的数据查询
数据查询是Hive的最主要的功能。Hive不支持标准SQL,但是熟悉SQL开发者还是能很快上手。
- select ....from 表;语句
- select后面可以跟查询的字段,from后面跟查询的表名,如下:
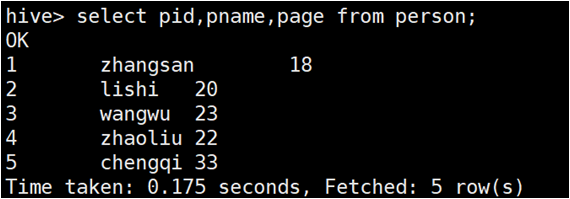
- 还可以为列和表起别名,select 列名 as 别名 from 表 ;(as可以省略)如下:

- 限制返回行数:
- select * from 表名 limit n; n表示行数;
- 去除重复字段:
- select distinct 列名 from 表;
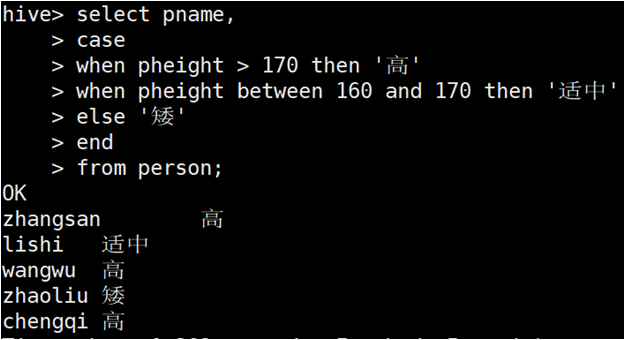
- 在select语句中使用case..when ...then 根据某列进行相应的处理,如图下所示:
- where语句(很多时候需要对查询条件进行限制,就需要使用where语句) 例如:
- select * from 表 where age = 18; (查询年龄的18的信息)
- where后的表达式完全兼容sql的写法,后面可以跟:
- = , <> , != , >= , <= , is null , is not null , like , between ,or , and in
- group by 和having语句(相当于where)
- group by 通常会和聚合函数一起使用,先按照一个或多个结果进行分组,再执行聚合操作,如下:
- select 列,count(*) from 表 group by 列名;
- 如果使用group by 字句,那么查询的字段如果没有出现在group by 字句后面则必须使用聚合函数,如下:
-
- select name,avg(age) from student roup by body;
- 这样Hive就会抛出一个:Expression not in gtoup by key name 的异常

- 如果想对分组的结果进行条件过滤,可以使用having字句,如下:
-

- 注意:字符串不能使用单引号,必须使用双引号。
-
- group by 通常会和聚合函数一起使用,先按照一个或多个结果进行分组,再执行聚合操作,如下:
- join语句
- (内连接)inner join ....on 等值连接条件
- 语法:select * from 表A inner join 表B on A.id = B.id;
- 只查询连接条件相等的字段数据。
- (左/右外连接)left/right outer join on 等值连接条件
- 语法:select * from 表A left/right join 表B on A.id = B.id;
- left:查询左表的所有信息与右表连接,没有与之对应的用null代替
- right:查询右表的所有信息与左表连接,没有与之对应的用null代替
(全外连接)full outer join on 等值连接条件
- 语法:select 表A.列,表B.列 from 表 full outer join A.id = B.id;
- 全外连接意味着结果集会包括左表和右表的所有记录
- (左半连接)left semi join
- 语法:select 表A.列,表B.列 from 表 left semi join A.id = B.id;
- 返回左表记录,前提满足on语句的判断条件
- 多表join(三表之上)
- select 表A.列,表B.列,表C.列 from 表 where A.id = B.id B.id = C.id;
- (内连接)inner join ....on 等值连接条件
- order by 和 sotr by 语句------------>单独使用的时候不用where
- order by 全局排序
- select * from 表 order by 列 desc/asc(升/降)
- sort by 局部排序
- select * from 表 sort by 列 desc/asc(升/降)
distribute by 和 cluster by
- order by 全局排序
- 二次排序:第一列相同的数据能够按照第二列进行排序的。
- 语法:select 列1,列2 from 表 distribute by 列1 sort by 列2;
- 语法:select 列1,列2 from 表 cluster by 列1,列2;
2. Hive函数
- count:j计算总行数
- sum:计算指定列的和
- avg:计算指定列的平均数
- max:统计指定列的最大值
- min:统计指定列的最小值