1.Hadoop简介:
- Hadoop是一个apache下的开源框架,它允许在整个集群使用简单的编程模型计算机的分布式环境存储并处理大数据。他的目的是从单一的服务器到上千台机器的扩展,每一个台机都可以提供本地计算和存储
- Hadoop的历史:

- Hadoop的特点:
- 高可靠性
- Hadoop按位存储和处理数据的能力值得人们信赖
- 高扩展性:
- Hadoop是在可用的计算机集簇分配数据并完成计算任务的,这些集簇可以方便的扩展到数以千计的节点中
- 高效性:
- Hadoop能够在节点之间动态的移动数据,并保证各个节点的动态平衡,因此处理速度非常快
- 高容错性:
- Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
- 低成本:
- Hadoop是开源的,使用的是廉价的硬件设备。项目的软件成本因此会大大降低
Hadoop体系介绍
- Hadoop的核心组件包括:HDFS Yarn MapReduce
- HDFS:目前采用分布式系统,是整个大数据应用场景的基础通用文件存储组
- Yarn:分布式资源调度,可以接受计算机任务把它分配到集群节点处理,相当于操作大数据操作系统,通用性好,生态支持好
- MapReduce:分布式计算框架,编程难度高,执行效率低
虚拟机的下载:

2.集群安装部署
- 修改主机名和用户名
- 配置静态ip地址
- 配置SSH无密码连接
- 添加用户:useradd 用户名
- 添加密码: passed 用户名
- 修改主机名: vi /etc/sysconfigs/network (HOSTNAME = 主机名)
- 修改Oracle VBox网络配置
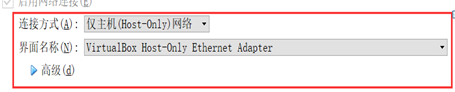
5.修改静态IP地址: vi /etc/sysconfig/network-scripts/ifcfg-eth0
6.普通用户获取sudo管理权限:
-
- 切换到超级用户
- 编辑 vi /etc/sudoers 配置文件 添加用户信息
- 保存退出:wq
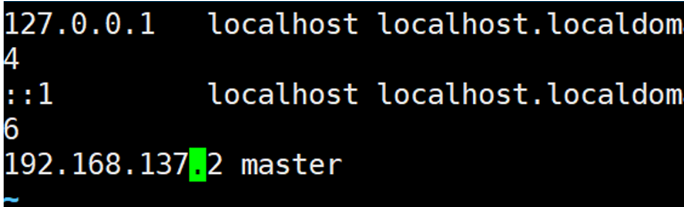
7.修改主机映射文件:为了让安装hadoop节点之间能够使用主机名进行互相访问
-
- vi /etc/hosts 在文件末尾加上ip地址和映射的主机名
8.配置SSH无密码连接
-
- SSH是一个可在应用程序中提供的安全通信协议,通过SSH可以安全的进行网络数据传输
- 在配置SSH无密码连接之前先关闭防火墙
- service iptables stop 临时关闭
- chkconfig iptables off 永久关闭
- 检查SSH是否安装(root用户执行,所有节点都需执行)
- rpm -qa | grep openssh
- 启动SSH服务: service sshd start
- 检查是否安装成功:rpm -qa | grep openssh
9.生成SSH公钥(必须在当前用户上操作)
-
- ssh -keygen -t rsa
- 公钥生成的位置: /home/hadoop01/.shh隐藏目录之下
- 通过:ls /home/主机名.ssh 来查看隐藏目录内容
10.公钥拷贝到本机的authorized_keys列表:
![]()
11.验证安装:对于伪分布式模式,在主节点(master)执行 ssh.master 。没出现输入密码测成功