一、FM介绍
(1)实验的主要任务:使用FM在movielen数据集上进行电影评分预测任务(rendle的工作,经典的特征选择)
(2)参考论文:Factorization Machines
(3)部署环境:python37 + pytorch1.3
(4)数据集:Movielen的small数据集,使用的rating.csv文件。数据集按照8:2的比例进行划分,随机挑选80%的数据当做训练集,剩余的20%当做测试集。
从数据集中选取的特征包括:userId , movieId , lastmovie , rating
lastmovie数据的构造过程为:将数据集按照userId进行排序,在对于每一个用户按照时间戳进行排序,找出对应于某个电影的上一个电影的movieId。
(5)代码结构:
进行数据预处理以及数据划分的代码在divideData.py文件中,划分之后得到rating_train.csv与rating_test.csv两个文件。(data文件夹下的ratings.csv为原始数据集,其中会得到一些中间文件:ratings_sort.csv文件为按照useId以及timestamp对数据集排序后得到的文件;rating_addLastMovie.csv文件为增加用户看的上一部电影的movieId得到文件;ratingsNoHead.csv文件为去掉数据集的表头得到的文件。)
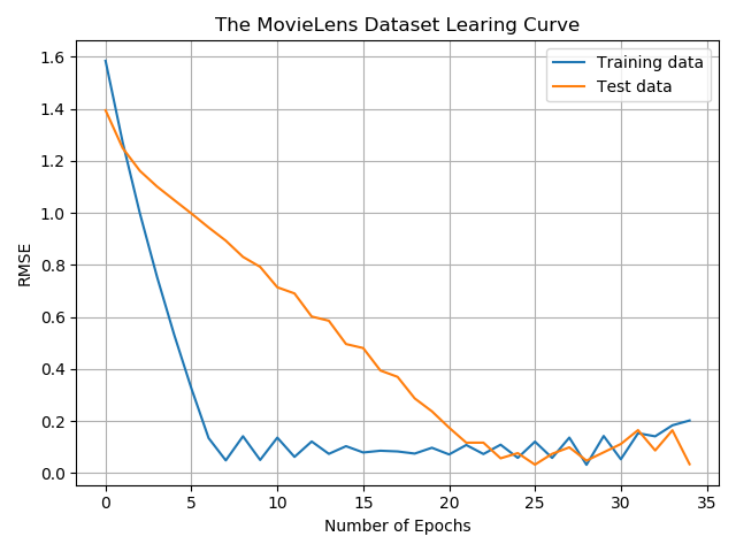
fm_model.py文件是读取训练集以及测试集,并使用pytorch框架编写FM训练模型,最后使用rmse作为评价指标,使用测试集对模型进行测试。模型训练过程中采用batch对数据集进行分批训练,同时每训练完一轮之后使用测试集进行测试,检验测试效果,并最终以曲线的形式展现出来。最终训练集与测试集的曲线图如下图所示:
(6)参数的调节:
①特征因子k的选取:在test_loss_for_k.py文件中含有绘制loss与k的关系图的代码,通过观察曲线的走向,选取合适的k值(前提是要先将loss与对应的k的数据存储存储到csv文件中,对应为data文件夹下的test_loss.csv文件)
②学习率的选取,同样在test_loss_for_k.py文件中含有绘制loss与学习率的关系图的代码,通过观察曲线的走向,选取合适的lr值。(同样应该将loss与学习率lr的对应曲线存储到csv文件中,对应于data文件夹下的test_loss_for_lr.csv文件)
同样的训练次数、正则化次数也是通过这种方法进行选取。
(7)评价标准:采用rmse作为评价指标,使用测试集对模型进行测试。(实验只使用了数据集中的一部分数据,同样也使用了完整的数据集进行了测试,测试误差为1.2。由于数据集较大,这里只上传使用的部分数据集。)
二、代码
1.代码结构:
2.divideData.py代码:
# coding: utf-8 """ 该文件主要是对数据进行预处理,将评分数据按照8:2分为训练数据与测试数据 """ import pandas as pd import csv import os #将文件中的数据按照userId进行排序,如果userId相同则按照timestamp进行排序 origin_f = open('data/ratings.csv','rt',encoding='utf-8',errors="ignore") new_f= open('data/ratings_sort.csv','wt',encoding='utf-8',errors="ignore",newline="") reader=csv.reader(origin_f) writer=csv.writer(new_f) sortedlist=sorted(reader,key=lambda x:(x[0],x[3]),reverse=True) print(sortedlist.__len__()) i=0 for row in sortedlist: if i==0: # 添加表头 writer.writerow(('userId','movieId','rating','timestamp')) if(i==(sortedlist.__len__()-1)): continue writer.writerow(row) i=i+1 origin_f.close() new_f.close() #增加last_movie字段 csvfile1=open('data/ratings_sort.csv','rt') reader=csv.DictReader(csvfile1) rows=[row for row in reader] # print(rows[0].get("userId")) i=0 csvfile2=open('data/ratings_sort.csv','rt') reader=csv.DictReader(csvfile2) rating_addLastMovie=open('data/rating_addLastMovie.csv','wt',encoding='utf-8',errors="ignore",newline="") writer=csv.writer(rating_addLastMovie) for row in reader: # 添加用户看得上一部电影 if i<(rows.__len__()-1) and rows[i].get("userId")==rows[i+1].get("userId"): row["last_movie"]=rows[i+1].get("movieId") else: row["last_movie"]=0 # print(row.values()) if i==0: writer.writerow(('userId', 'movieId', 'rating', 'timestamp','last_movie')) writer.writerow(row.values()) i=i+1 csvfile1.close() csvfile2.close() rating_addLastMovie.close() # 删除文件中的表头 origin_f = open('data/rating_addLastMovie.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratingsNoHead.csv','wt+',encoding='utf-8',errors="ignore",newline="") reader = csv.reader(origin_f) writer = csv.writer(new_f) i=0 for i,row in enumerate(reader): if i>1: writer.writerow(row) origin_f.close() new_f.close() #将数据按照8:2的比例进行划分得到训练数据集与测试数据集 df = pd.read_csv('data/ratingsNoHead.csv', encoding='utf-8') # df.drop_duplicates(keep='first', inplace=True) # 去重,只保留第一次出现的样本 # print(df) df = df.sample(frac=1.0) # 全部打乱 cut_idx = int(round(0.2 * df.shape[0])) df_test, df_train = df.iloc[:cut_idx], df.iloc[cut_idx:] # 打印数据集中的数据记录数 print(df.shape,df_test.shape,df_train.shape) # print(df_train) # 将数据记录存储到csv文件中 # 存储训练数据集 df_train=pd.DataFrame(df_train) df_train.to_csv('data/ratings_train_tmp.csv',index=False) # 由于一些不知道为什么的原因,使用pandas读取得到的数据多了一行,在存储时也会将这一行存储起来,所以应该删除这一行(如果有时间在查一查看能不能解决这个问题) origin_f = open('data/ratings_train_tmp.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratings_train.csv','wt+',encoding='utf-8',errors="ignore",newline="") #必须加上newline=""否则会多出空白行 reader = csv.reader(origin_f) writer = csv.writer(new_f) for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() os.remove('data/ratings_train_tmp.csv') # 存储测试数据集 df_test=pd.DataFrame(df_test) df_test.to_csv('data/ratings_test_tmp.csv',index=False) origin_f = open('data/ratings_test_tmp.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratings_test.csv','wt+',encoding='utf-8',errors="ignore",newline="") reader = csv.reader(origin_f) writer = csv.writer(new_f) for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() os.remove('data/ratings_test_tmp.csv')
3. fm_model代码:
import pandas as pd import torch as pt import torch.utils.data as Data import matplotlib.pyplot as plt from sklearn.feature_extraction import DictVectorizer BATCH_SIZE=15 cols=['user','item','rating','timestamp','last_movie'] train = pd.read_csv('data/ratings_train.csv', encoding='utf-8',names=cols) test = pd.read_csv('data/ratings_test.csv', encoding='utf-8',names=cols) train=train.drop(['timestamp'],axis=1) #时间戳是不相关信息,可以去掉 test=test.drop(['timestamp'],axis=1) # DictVectorizer会把数字识别为连续特征,这里把用户id、item id和lastmovie强制转为 catogorical identifier train["item"]=train["item"].apply(lambda x:"c"+str(x)) train["user"]=train["user"].apply(lambda x:"u"+str(x)) train["last_movie"]=train["last_movie"].apply(lambda x:"l"+str(x)) test["item"]=test["item"].apply(lambda x:"c"+str(x)) test["user"]=test["user"].apply(lambda x:"u"+str(x)) test["last_movie"]=test["last_movie"].apply(lambda x:"l"+str(x)) # 在构造特征向量时应该不考虑评分,只考虑用户数和电影数 train_no_rating=train.drop(['rating'],axis=1) test_no_rating=test.drop(['rating'],axis=1) all_df=pd.concat([train_no_rating,test_no_rating]) # all_df=pd.concat([train,test]) data_num=all_df.shape print("all_df shape",all_df.shape) # 打印前10行 # print("all_df head",all_df.head(10)) # 进行特征向量化,有多少特征,就会新创建多少列 vec=DictVectorizer() vec.fit_transform(all_df.to_dict(orient='record')) # 合并训练集与验证集,是为了one hot,用完可以释放 del all_df x_train=vec.transform(train.to_dict(orient='record')).toarray() x_test=vec.transform(test.to_dict(orient='record')).toarray() # print(vec.feature_names_) #查看转换后的别名 print("x_train shape",x_train.shape) print("x_test shape",x_test.shape) # y_train=train['rating'].values.reshape(-1,1) y_test=test['rating'].values.reshape(-1,1) print("y_train shape",y_train.shape) print("y_test shape",y_test.shape) # n,p=x_train.shape # train_dataset = Data.TensorDataset(pt.tensor(x_train),pt.tensor(y_train)) test_dataset=Data.TensorDataset(pt.tensor(x_test),pt.tensor(y_test)) # 训练集分批处理 loader = Data.DataLoader( dataset=train_dataset, # torch TensorDataset format batch_size=BATCH_SIZE, # 最新批数据 shuffle=False # 是否随机打乱数据 ) # 测试集分批处理 loader_test=Data.DataLoader( dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False ) class FM_model(pt.nn.Module): def __init__(self,p,k): super(FM_model,self).__init__() self.p=p #feature num self.k=k #factor num self.linear=pt.nn.Linear(self.p,1,bias=True) #linear part self.v=pt.nn.Parameter(pt.rand(self.k,self.p)) #interaction part def fm_layer(self,x): #linear part linear_part=self.linear(x.clone().detach().float()) #interaction part inter_part1 = pt.mm(x.clone().detach().float(), self.v.t()) inter_part2 = pt.mm(pt.pow(x.clone().detach().float(), 2), pt.pow(self.v, 2).t()) pair_interactions=pt.sum(pt.sub(pt.pow(inter_part1,2),inter_part2),dim=1) output=linear_part.transpose(1,0)+0.5*pair_interactions return output def forward(self, x): output=self.fm_layer(x) return output k=5 #因子的数目 fm=FM_model(p,k) fm # print("paramaters len",len(list(fm.parameters()))) # # print(list(fm.parameters())) # for name,param in fm.named_parameters(): # if param.requires_grad: # print(name) #评价指标rmse def rmse(pred_rate,real_rate): #使用均方根误差作为评价指标 loss_func=pt.nn.MSELoss() mse_loss=loss_func(pred_rate,pt.tensor(real_rate).float()) rmse_loss=pt.sqrt(mse_loss) return rmse_loss #训练网络 learing_rating=0.05 optimizer=pt.optim.SGD(fm.parameters(),lr=learing_rating) #学习率为 loss_func= pt.nn.MSELoss() loss__train_set=[] loss_test_set=[] for epoch in range(35): #对数据集进行训练 # 训练集 for step,(batch_x,batch_y) in enumerate(loader): #每个训练步骤 #此处省略一些训练步骤 optimizer.zero_grad() # 如果不置零,Variable的梯度在每次backwrd的时候都会累加 output = fm(batch_x) output = output.transpose(1, 0) # 平方差 rmse_loss = rmse(output, batch_y) l2_regularization = pt.tensor(0).float() # 加入l2正则 for param in fm.parameters(): l2_regularization += pt.norm(param, 2) # loss = rmse_loss + l2_regularization loss = rmse_loss loss.backward() optimizer.step() # 进行更新 # 将每一次训练的数据进行存储,然后用于绘制曲线 loss__train_set.append(loss) #测试集 for step,(batch_x,batch_y) in enumerate(loader_test): #每个训练步骤 #此处省略一些训练步骤 optimizer.zero_grad() # 如果不置零,Variable的梯度在每次backwrd的时候都会累加 output = fm(batch_x) output = output.transpose(1, 0) # 平方差 rmse_loss = rmse(output, batch_y) l2_regularization = pt.tensor(0).float() # print("l2_regularization type",l2_regularization.dtype) # 加入l2正则 for param in fm.parameters(): # print("param type",pt.norm(param,2).dtype) l2_regularization += pt.norm(param, 2) # loss = rmse_loss + l2_regularization loss = rmse_loss loss.backward() optimizer.step() # 进行更新 # 将每一次训练的数据进行存储,然后用于绘制曲线 loss_test_set.append(loss) plt.clf() plt.plot(range(epoch+1),loss__train_set,label='Training data') plt.plot(range(epoch+1),loss_test_set,label='Test data') plt.title('The MovieLens Dataset Learing Curve') plt.xlabel('Number of Epochs') plt.ylabel('RMSE') plt.legend() plt.grid() plt.show() print("train_loss",loss) # print(y_train[0:5]," ",output[0:5]) # 保存训练好的模型 pt.save(fm.state_dict(),"data/fm_params.pt") test_save_net=FM_model(p,k) test_save_net.load_state_dict(pt.load("data/fm_params.pt")) #测试网络 pred=test_save_net(pt.tensor(x_test)) pred=pred.transpose(1,0) rmse_loss=rmse(pred,y_test) print("test_loss",rmse_loss) # print(y_test[0:5]," ",pred[0:5]) # 存储test_loss与k及学习率的数据到文件中,来绘制曲线 # new_f= open('data/test_loss_for_lr.csv','a',encoding='utf-8',errors="ignore",newline="") # writer=csv.writer(new_f) # writer.writerow((learing_rating,rmse_loss.detach().numpy())) # new_f.close()
4. test_loss_for_k.py代码:
import matplotlib.pyplot as plt import pandas as pd # 绘制loss与k的关系图 # cols=['k','loss'] # loss_for_k=pd.read_csv('data/test_loss.csv', encoding='utf-8',names=cols) # k=loss_for_k["k"] # loss=loss_for_k['loss'] # epoch=loss.shape[0] # plt.plot(k,loss,marker='o',label='loss data') # plt.title('loss for k') # plt.xlabel('k') # plt.ylabel('loss') # plt.legend() # plt.show() # 绘制loss与学习率的关系图 cols=['lr','loss'] loss_for_k=pd.read_csv('data/test_loss_for_lr.csv', encoding='utf-8',names=cols) lr=loss_for_k["lr"] loss=loss_for_k['loss'] epoch=loss.shape[0] plt.plot(lr,loss,marker='o',label='loss data') plt.title('loss for lr') plt.xlabel('lr') plt.ylabel('loss') plt.legend() plt.show()