在使用之前,提供一个大致思想,使用Flume的过程是确定scource类型,channel类型和sink类型,编写conf文件并开启服务,在数据捕获端进行传入数据流入到目的地。
实例一、从控制台打入数据,在控制台显示
1、确定scource类型,channel类型和sink类型
确定的使用类型分别是,netcat source, memory channel, logger sink.
2、编写conf文件
#a代表agent的名称,r1代表source的名称。c1代表channel名称,k1代表的是sink的名称
#声明各个组件
a.sources=r1
a.channels=c1
a.sinks=k1
#定义source类型,这里是试用netcat的类型
a.sources.r1.type=netcat
a.sources.r1.bind=192.168.230.50
a.sources.r1.port=8888
#定义source发送的下游channel
a.sources.r1.channels=c1
#定义channel
a.channels.c1.type=memory
#缓存的数据条数
a.channels.c1.capacity=1000
#事务数据量
a.channels.c1.transactionCapacity=1000
#定义sink的类型,确定上游channel
a.sinks.k1.channel=c1
a.sinks.k1.type=logger
3、开启服务,我们重新开启复制一个客户端进行开启服务
命令:
flume-ng agent -n a -c ../conf -f ./netcat.conf -Dflume.root.logger=DEBUG,console (注意:-n 后面跟着的是你在conf文件中定义好的,-f 后面跟着的是编写conf文件的路径)
在另一个客户端输入命令:
telnet master 8888 (注意:这里的master和8888是在conf文件中设置好的ip地址和端口)
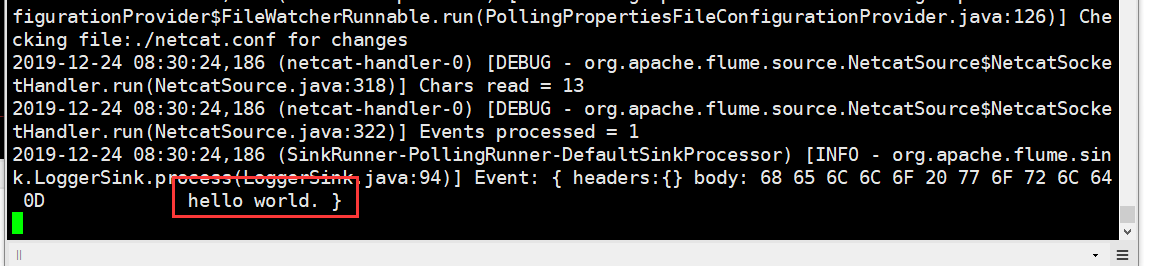
在输入第二个命令的窗口中输入数据,回车,在服务端就会接收到数据。如图

接收的数据:
实例二、从本地指定路径中打入数据到HDFS
1、同样,我们需要先确定scource类型,channel类型和sink类型
我们确定使用的类型分别是,spooldir source, memory channle, hdfs sink
2、编写conf文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#指定spooldir的属性
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/soft/flumedata
#时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
#指定sink的类型
a1.sinks.k1.type = hdfs
#指定hdfs的集群地址和路径,路径如果没有创建会自动创建
a1.sinks.k1.hdfs.path =hdfs://master:9000/usr/test/log_s/dt=%Y-%m-%d
#指定hdfs路径下生成的文件的前缀
a1.sinks.k1.hdfs.filePrefix = log_%Y-%m-%d
#手动指定hdfs最小备份
a1.sinks.k1.hdfs.minBlockReplicas=1
#设置数据传输类型
a1.sinks.k1.hdfs.fileType = DataStream
#如果参数为0,不按照条数生成文件。如果参数为n,就是按照n条生成一个文件
a1.sinks.k1.hdfs.rollCount = 1000
#这个参数是hdfs下文件sink的数据size。每sink 32MB的数据,自动生成一个文件
a1.sinks.k1.hdfs.rollSize =0
#每隔n 秒 将临时文件滚动成一个目标文件。如果是0,就不按照时间进行生成目标文件。
a1.sinks.k1.hdfs.rollInterval =0
a1.sinks.k1.hdfs.idleTimeout=0
#指定channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、开启服务
flume-ng agent -n a1 -c ../conf -f ./spool2hdfs2.conf -Dflume.root.logger=DEBUG, console
将文件复制到指定的目录下
cp commodity.csv /usr/local/soft/flumedata/
去HDFS上查看结果

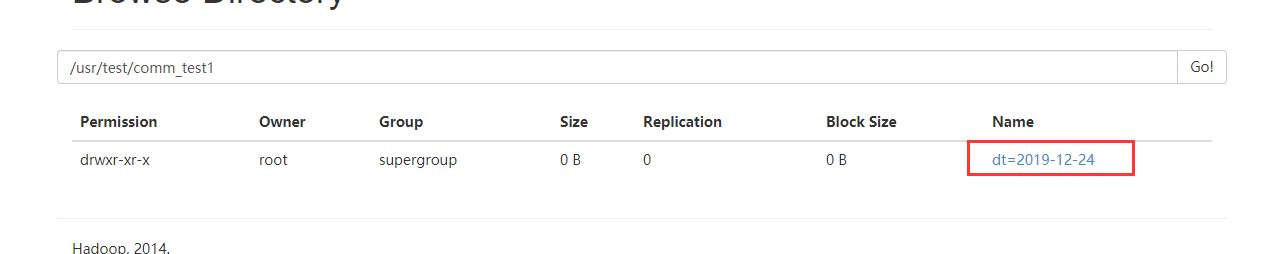
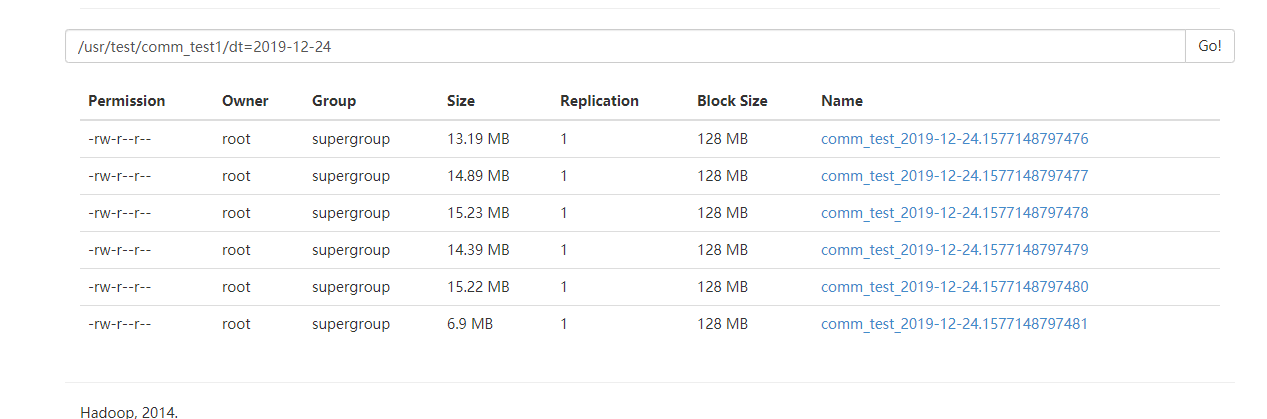
实例三、从java代码中进行捕获打入到HDFS
1、先确定scource类型,channel类型和sink类型
确定的三个组件的类型是,avro source, memory channel, hdfs sink.
2、打开maven项目,添加依赖
<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.flume.flume-ng-clients</groupId> <artifactId>flume-ng-log4jappender</artifactId> <version>1.6.0</version> </dependency>
3、设置log4J的内容
log4j.rootLogger=INFO,stdout,flume
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = 192.168.230.50
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
log4j.appender.flume.layout=org.apache.log4j.PatternLayout
log4j.appender.flume.layout.ConversionPattern=%m%n
4、编写conf文件
#定义agent名, source、channel、sink的名称
a.sources = r1
a.channels = c1
a.sinks = k1
#具体定义source
a.sources.r1.type = avro
a.sources.r1.bind = 192.168.230.50
a.sources.r1.port = 41414
#具体定义channel
a.channels.c1.type = memory
a.channels.c1.capacity = 10000
a.channels.c1.transactionCapacity = 100
#具体定义sink
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path =hdfs://master:9000/usr/test/flume_hdfs_avro2
a.sinks.k1.hdfs.filePrefix = events-
a.sinks.k1.hdfs.minBlockReplicas=1
a.sinks.k1.hdfs.fileType = DataStream
#a.sinks.k1.hdfs.fileType = CompressedStream
#a.sinks.k1.hdfs.codeC = gzip
#不按照条数生成文件
a.sinks.k1.hdfs.rollCount = 1000
a.sinks.k1.hdfs.rollSize =0
#每隔N s将临时文件滚动成一个目标文件
a.sinks.k1.hdfs.rollInterval =0
a.sinks.k1.hdfs.idleTimeout=0
#组装source、channel、sink
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
5、开启服务,命令:
flume-ng agent -n a -c ../conf -f ./avro2hdfs2.conf -Dflume.root.logger=DEBUG,console

6、运行Java代码

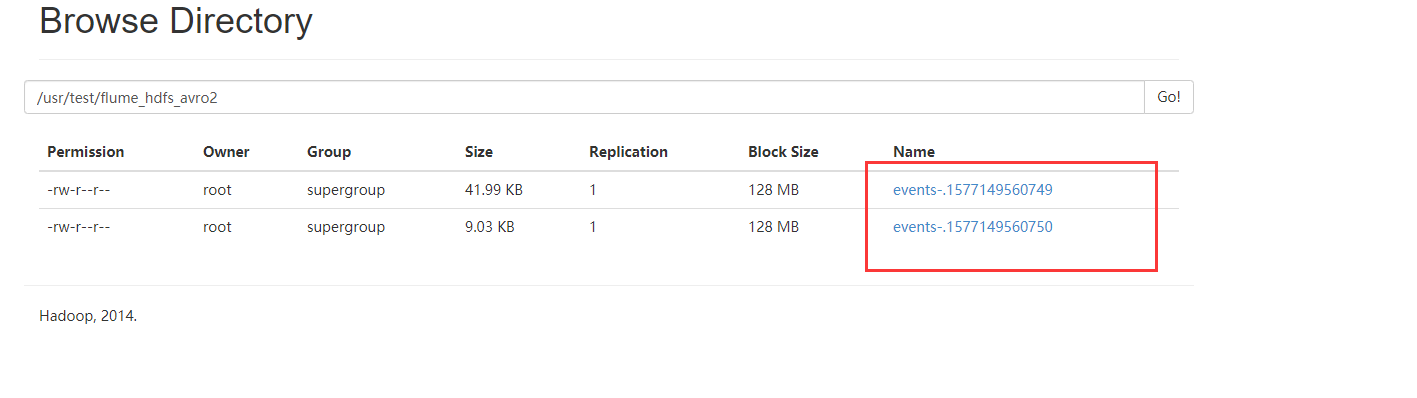
7、查看HDFS

实例四、flume监控Http source
1、先确定scource类型,channel类型和sink类型
确定的三个组件的类型是,http source, memory channel, logger sink.
2、编写conf文件
a1.sources=r1 a1.sinks=k1 a1.channels=c1 a1.sources.r1.type=http a1.sources.r1.bind=duan140 a1.sources.r1.port=50000 a1.sources.r1.channels=c1 a1.sinks.k1.type=logger a1.sinks.k1.channel=c1 a1.channels.c1.type=memory a1.channels.c1.capacity=10000 a1.channels.c1.transactionCapacity=100
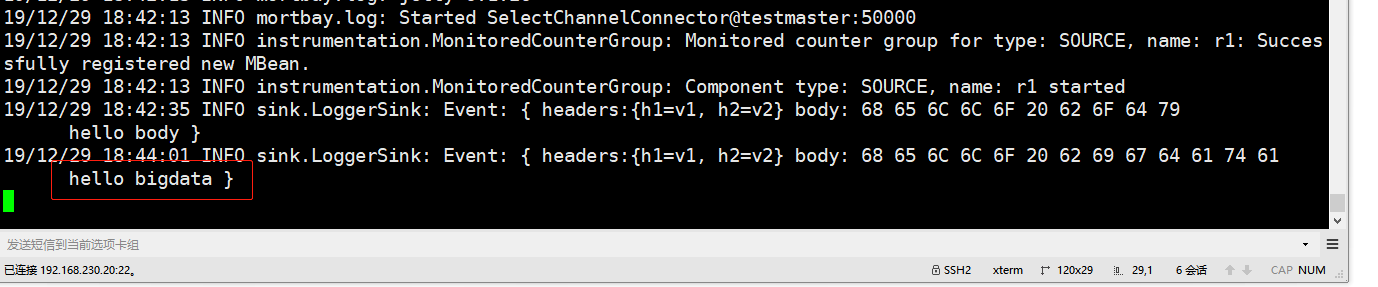
3、启动服务
flume-ng agent -f ./http.conf -n a1
4、复制一个窗口进行打数据
curl -X POST -d'[{"headers":{"h1":"v1","h2":"v2"},"body":"hello bigdata"}]' http://192.168.230.20:50000
5、查看结果