最近处理的大多数任务都是基于python的多线程实现的,然而使用python逃避不开的一个话题就是,python的GIL(的全称是 Global Interpreter Lock)全局解释器锁是单线程的,那么是不是意味着python的多线程也是串行的?多线程对共享资源的使用就不需要锁(线程锁)了?
笔者一开始也是这么误解:
既然python解释器的锁是单线程的===》那么经过解释器生成的线程,是轮训执行的(相当于单线程)===》然后推断出线程访问共享资源的时候不需要加线程锁?
既然不需要加线程锁,那么python为什么会存在线程锁?这明显是一个矛盾的问题,以上推论纯属YY,上述结论是不正确的。
其实上述推断从第二步就开始错误了,其实某些时候,看似合理的推断,是完成不成立的。
先做个小demo看一下效果,下面代码很简单,线程方法内部轮训设置全局变量递增,然后其多个线程调用该方法,线程方法在操作全局变量的时候暂时不适用线程锁
#! /usr/bin/python # -*- coding: utf-8 -*- from threading import Thread,Lock g_var = 0 lock = Lock() def thread_tasks(): for i in range(100000): global g_var #lock.acquire() g_var = g_var+1 #lock.release() if __name__ == "__main__": t_list = [] for i in range(100): t = Thread(target=thread_tasks, args=[]) t_list.append(t) for t in t_list: t.setDaemon(True) t.start() for t in t_list: t.join() print('thread execute finish') print('global variable g_var is ' + str(g_var))
理论上出来的结果,最终全局变量的结果就是线程数*每个线程循环的次数,这里线程数是100,线程方法内部循环100000次,最终的结果“理论上”是10,000,000。
能动手的绝对不动嘴,实际执行下来发现并不是这样的,甚至会出现各种意料之外的答案,原因何在?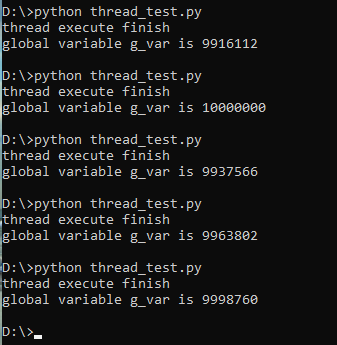
这篇《也许你对 Python GIL 锁的理解是 错的》文章提到这个问题,理论上也比较简单
然后再加上线程锁,看看效果(需要注意的是:开启线程锁之后,不应该无脑开启太多的线程,因为这个线程锁会导致线程之间严重争用问题)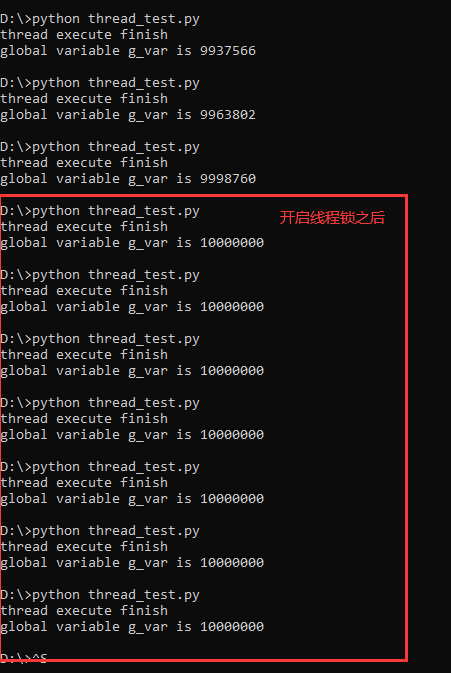
关于python的多线程无法对CPU使用充分的问题,笔者是12核的机器,在跑上述代码的时候,CPU使用情况如下,鉴于对python了解的不够深入,不知道怎么解释这种“python单位时间内只能使用同一个CPU”的问题
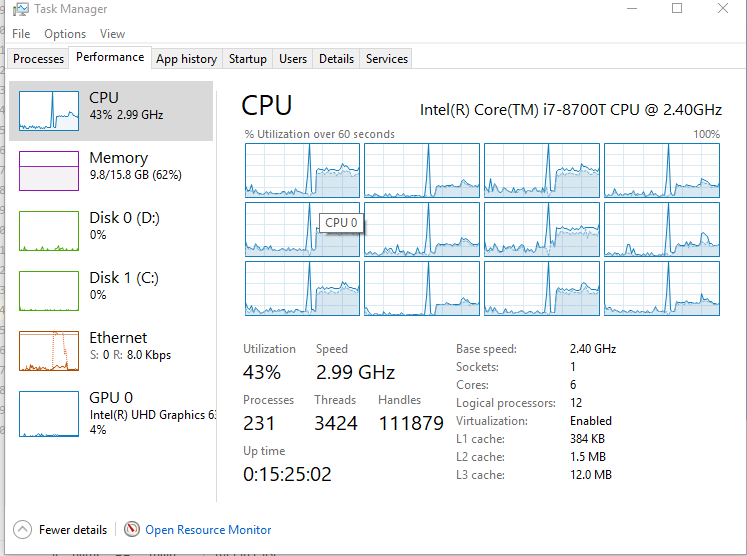

关于python多线程使用,根据笔者的测试总结,也有一些思考
1,如果是远程任务,就好比上述代码thread_tasks中执行的是一个远程服务(比如远程数据库访问什么的),完全可以达到“并发”的效果,因为本地CPU仅负责启动线程,线程在远程服务端一样可以做到并发效果,比如多线程压测远程访问数据库的时候,一样可以打爆远程数据库服务器的CPU。
2,如果本地任务,且本地任务属于非CPU密集型任务,比如IO操作,或者网络读写等等,多线程一样可以达到并发效果,因为瓶颈并不在CPU使用上(整体效率不是增加CPU的使用就可以提升的)
3,如果本地任务,且本地任务属于CPU密集型任务,此时python的多线程是无法发挥其功效的(多进程不香么,此时可以考虑多进程并发)。
关于python的多进程并发模型,也非常简单,相比线程锁,进程之间的通讯,一个内置的queue就完事了,如下是模拟多进程并法实现上述计算。
from multiprocessing import Process, Pool, Queue from threading import Thread, Lock import time import progressbar import math g_var = 0 lock = Lock() def thread_tasks(q): for _ in range(100000): q.put(1) def consumer_q(q): global g_var p = progressbar.ProgressBar() p.start() while True: var = q.get(True) g_var = g_var + var try: p.update(int((g_var / (100 * 100000 - 1)) * 100)) except Exception as ex: pass p.finish() if __name__ == "__main__": q = Queue() p_list = [] p_consumer = Process(target=consumer_q, args=[q, ]) p_consumer.start() for i in range(50): p = Process(target=thread_tasks, args=[q, ]) p_list.append(p) for p in p_list: p.start() for p in p_list: p.join() time.sleep(1) print(' sub_process execute finish') p_consumer.terminate()
这里非常客观地评价了python的多进程和多线程并发对比:https://www.cnblogs.com/massquantity/p/10357898.html