没错这就是DQL,数据查询语言。来看看怎么用。
select语句按照复杂程度来说分为简单查询、where查询、多表查询、子查询等。
先来看看select的语法
1.select 2.[distince|all] //描述列表字段中的数据是否去除重复记录 3. select_list 需要查询的字段列表,也可以说是占位符。可以是一个字段,也可以多个字段 4.from table_list 5.[where_clause] //查询条件 6.[group_by_clause] // group by子句部分 7.[having condition]//havint子句部分 8.[order_by_clause]//排序
方便研究,先来创建一个表pro。
| productid | productname | productprice | quantity | category | origin |
| 1 | 夏普 | 1000 | 22 | 1 | 日本 |
| 2 | 海尔 | 2000 | 33 | 2 | 中国 |
| 3 | 三星 | 3000 | 44 | 3 | 韩国 |
| 4 | 华为 | 4000 | 55 | 4 | 中国 |
1.简单查询
简单查询用到上面查询语句的前四行。
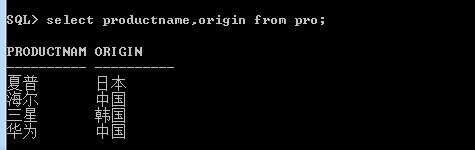
1.获取productname 和 origin的数据
2.获取所有字段的数据

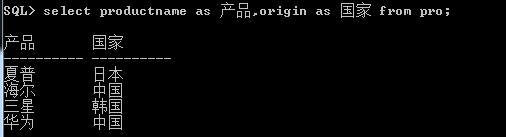
3.使用别名替代表中的字段名。 指定别名可以使用as关键字。
4.使用表达式操作查询的字段
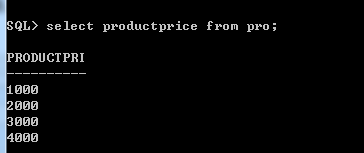
可以针对某个列使用表达式,这样查询出来的结果就是修改后的数据,但是数据库表里面的数据不会改变
不用的时候
那么想要让他都变成1.25倍呢?可以使用

这里面 || 是用来连接字符串的。
5.使用函数操作查询的数据
查询过程中允许检索的列使用函数对其操作,如果仅仅是查询,那么更多的是利用函数对数据进行类型转换。
利用函数 subStr,对字符串进行截取。
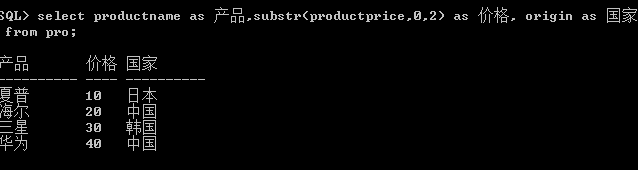
截取前两位字符串。
6.去除检索数据中的重复记录
使用distince(column_name)来去重复数据

2.检索出来的数据排序
1.使用升序或者降序排序
按照productname进行排序,先来看看未排序之前默认是升序的

按照升序,关键字是desc
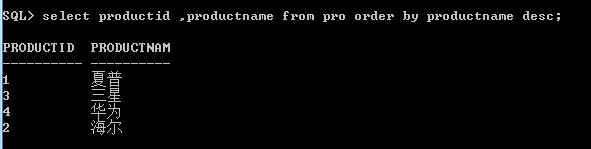
按照降序,关键字是asc

2.排序时对null值进行处理
修改一下表
| productid | productname | productprice | quantity | category | origin |
| 1 | 夏普 | 1000 | 22 | 1 | 日本 |
| 2 | 海尔 | 2000 | 33 | 2 | 中国 |
| 3 | 三星 | 3000 | 44 | 韩国 | |
| 4 | 华为 | 4000 | 55 | 4 | 中国 |
对于null值来说默认排序的时候是最大的。
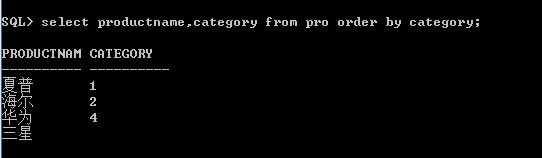
但是我们可以指定null值在前面还是后面


3.使用别名作为排序字段
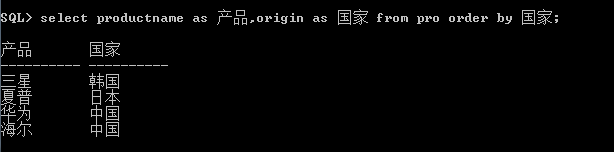
4.使用表达式作为排序字段
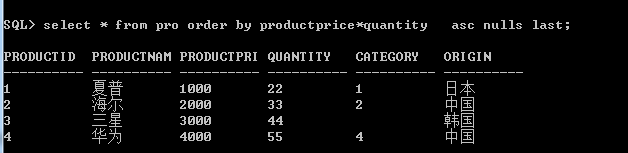
5.使用字段的位置作为排序字段
排序时允许使用查询列表中字段的位置来作为排序字段

6.使用多个字段排序
也就是说当第一个字段都一样时,再用第二个,依次类推。
3.where子句设置检索条件
where条件子句中可以使用的操作符主要有关系操作符、比较操作符和逻辑操作符
关系操作符:< 、 <= 、 > 、 >=、 =、!=、<>
比较操作符:
is null:如果操作数为Null返回true
like:模糊比较字符串值
between...and...验证值是否在范围之内
in:验证操作数在设定的一系列值中
逻辑操作符
and:且
or:或
not:取反
1.查询中使用单一条件限制
主要针对关系操作符来说,也可以使用函数

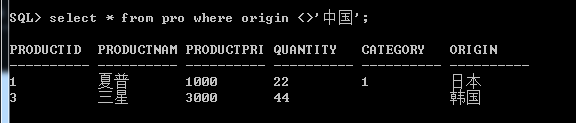

2.查询中使用多个条件限制


3.模糊查询数据
模糊查询使用like,它和两个通配符一起使用,才能使用模糊查询的功能,用这两个通配符可以替代模糊的地方
_:代替一个字符
%:代替多个字符

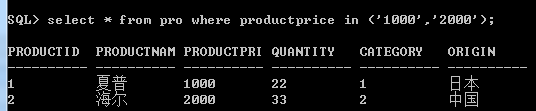
4.查找条件限制在某个列表范围内
5.专门针对null值得查询

4.group by 和 having的使用
用于组的查询,使用分组查询可以统计数据。
1.根据某一个字段分组查询

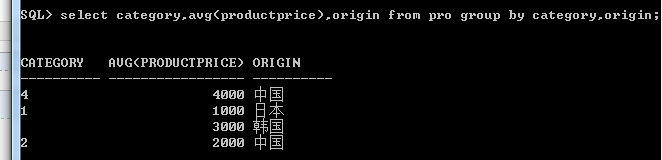
2.根据多个字段分组
3.having用来限制组的搜索条件

5.使用子查询
子查询就是嵌套查询,一个查询嵌套在另一个与剧中的select语句中。
什么时候要使用子查询呢?
当where后面的值并不是一个确切的值或表达式,而是另一个查询语句的查询结果。
再建一个表cat
| catagoryid | catagoryname |
| 1 | 电脑 |
| 2 | 冰箱 |
| 3 | 手机 |
| 4 | 通信设备 |
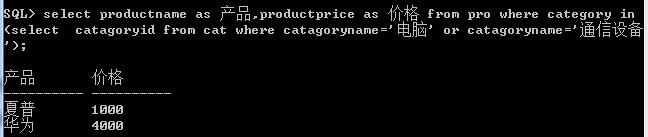
比如 pro表中的catagory对应cat中的主键catagoryid,想通过该类型的产品到底包含了哪些产品,就不得不使用子查询.
1.子查询返回单行


2.子查询返回多行
需要用到in关键字,除此之外,还可以使用量化比较关键字some,any,all,这些需要配合< ,<=,=,>,>=使用
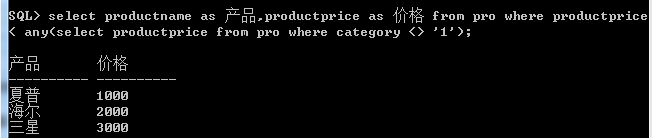


6.连接查询
关系型数据库获取真实世界的原始数据后,根据某种规则把它们拆分成了各种独立的数据,假如想从数据库中再次获取原始数据,那么要依靠当初拆分时的规则,而这种规则也可以看成表与表之间的联系,要再次实现这种联系需要用到连接查询,连接分为内连接、外连接、全连接,还有一种叫做自连接
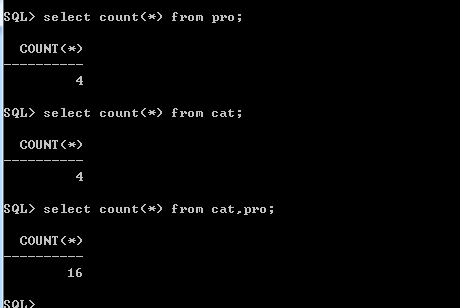
1.最简单的连接查询
也就是通过逗号来实现的,但是这样会产生笛卡尔乘积,没有什么意义
2 内连接
也被称为简单链接,它会把两个或多个表进行连接,只能查询出匹配的记录。这种连接查询是最常用的查询。内连接中最常用的就是等值连接和不等值连接
一、等值连接
连接条件使用“=”连接两个条件列表。
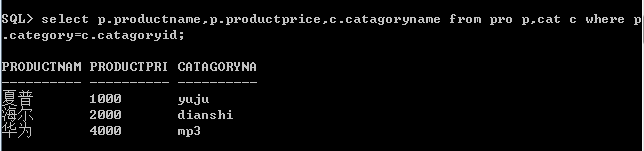
或者是

二、不等值连接
不等值连接就是指连接条件中使用除了=的关系操作符和比较操作符,但这种方式通常需要通过和其他等值运算一起使用,否则检索出来的数据很可能没有实际意义。
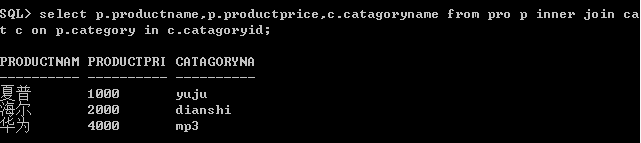
或者

inner join可以直接写成join 但是on不能省略

3.自连接
自连接,就是把自身表的一个引用作为另一个表来处理,这样就能获取一些特殊的数据。
比如获得一个pro中数量相同的不同产品

4.外连接
外连接分为
左外连接:使用左外连接的查询,返回的结果不仅仅是符合连接条件的行记录,还包含了左边表中的全部记录。也就是说,如果坐标的某行记录在右表中没有匹配项,则在返回结果中右表的所有选择列表列均为空。
检索出pro表中每个产品对应的产品类型名称。
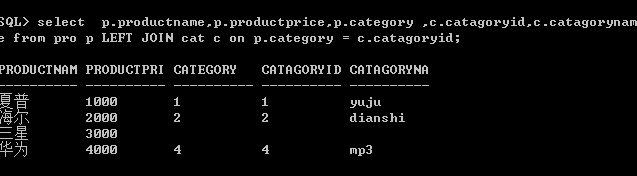
也就是说他会把左边表的所有数据列出来,如果右表没有匹配的数据,那就为空。
右外连接:与左外连接相反,将右边表中所有数据与坐标进行匹配,返回的结果除了匹配成功的记录,还包含了右表中未匹配成功的记录,并在其坐标对应的列补空值。
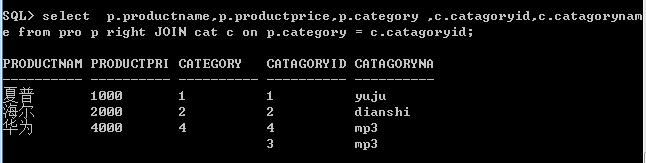
全外连接:返回所有匹配成功的记录,并返回左表未匹配成功的记录,也返回右表为匹配成功的记录

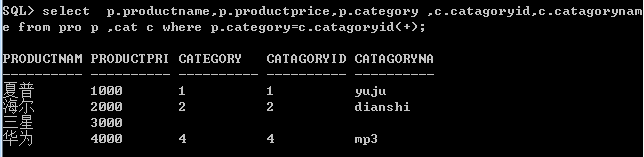
4.(+)的使用
对于左连接和右连接,可以有简便写法
左连接
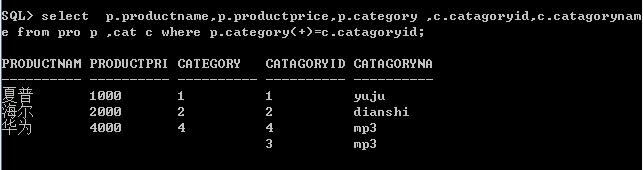
右连接
又温习到这我才有一种说不出的苦涩啊,原来左连接和内连接是这个啊,老师当时讲的时候根本没讲这概念啊,真的是第一次知道这概念啊,学习真的得靠自己啊,书中自有黄金屋啊,面试真的是可惜啊,又看了看数据库我才发现二面问的问题比一面问的要更简单啊!! 可惜啊可惜,继续努力吧!