一 了解Statefulset
1.1 对比statefulset与RS以及RC的区别以及相同点
- Statefulset是有状态的,而RC以及RS等是没有状态的
- Statefulset是有序的,拥有规则的主机名和名称,而RS以及RC是无序的
- 通常为Statefulset提供的服务一般都是创建headless service,通过headless service可以为statefulset提供唯一的DNS记录,例如一个在default的命名空间里面名为A-0的pod,提供服务的为foo的headless service,我们则可以使用a-0.foo.default.svc.cluster.local,而在ReplicaSet是行不通的
- 当一个Statefulset管理的pod异常消失后,Statefulset会创建一个与之一摸一样的pod,包括名称,pod名称,以及后端引用的pvc等(但是新的pod不要求调度到之前pod所在的节点上)
1.2 Statefulset扩所容方面的差别
- Statefulset的扩缩容方面,扩容方面,一般都是按照正顺往上叠加,例如已经存在2个pod它们的序号分别为0,1那么在扩容的时候下一个被增加的就是2
- 缩容方面,可以指定哪个索引的pod被缩容,没指定就会从最高的索引删除
1.3 Statefulset的存储方面
-
- 在statefulset中每个pod都会有自己的存储,所以需要存储与pod强解耦合,可以使用之前学习到的pv以及pvc,并且每个pod都需要创建一个pvc并有一个pv与之对
- statefulset的做法是在创建的配置的时候就创建一个或者多个pvc,而声明的pv可以由管理员提前创建也可以由系统里面的配置程序提前配置
- 在pod扩容这块,当扩容一个pod的时候需要创建不仅仅是pod的资源包括持久化存储等
- 到pod缩容这块,删除pod的时候不能将其关联的存储也一并删除了,这样的话在重新扩容的时候,之前pod的持久化存储的数据就无法再恢复
1.4 statefulset的保障
-
- 由于statefulset的特殊性,它需要自己去独占很多系统资源或者kubernets资源,所以有一项是必须保证的,就是有2个完全相同的标记不能同时出现,一个pod必须保证statefulset的at-most-one的定义
二 创建statefulset
2.1 一个statefulset的mainifest的配置如下所示
apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: kubia spec: serviceName: kubia replicas: 2 template: metadata: labels: app: kubia spec: containers: - name: kubia image: luksa/kubia-pet ports: - name: http containerPort: 8080 volumeMounts: - name: data mountPath: /var/data volumeClaimTemplates: - metadata: name: data spec: resources: requests: storage: 1Mi accessModes: - ReadWriteOnce
- statefulset基本和RC,RS,Deployment很类似拥有副本数量模版以及标签并且还可以定义关联的headless的svc
- 同时在下面引入了一个新的字段用来定义statefulset的每个pod的pvc
2.2 创建三个hostpath类型的pvc
kind: List apiVersion: v1 items: - apiVersion: v1 kind: PersistentVolume metadata: name: pv-a labels: type: local spec: capacity: storage: 10Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: "/tmp/pv-a" - apiVersion: v1 kind: PersistentVolume metadata: name: pv-b labels: type: local spec: capacity: storage: 10Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: "/tmp/pv-b" - apiVersion: v1 kind: PersistentVolume metadata: name: pv-c labels: type: local spec: capacity: storage: 10Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: "/tmp/pv-c"
- 这里创建了一个pvc列表,里面包含了三个创建的pv
- metadata里面有个type类型的字段如果为local,则statefulset的pv只会出现在pod被调度到的节点上面
- 每个pv里面都包含该卷的大小,访问模式
- 如果是hostpath类型的卷,需要添加一个hostPath参数,并且指定hostpath的存储路径
2.3 为了方便我们对statefulset的访问,我们同时创建了一个clusterIp的service以及headless的IP,其mainifest分别如下所示
2.3.1 clusterIP的service的mainifest
[root@node01 Chapter10]# cat kubia-service-public.yml apiVersion: v1 kind: Service metadata: name: kubia-service spec: selector: app: kubia ports: - port: 80 targetPort: 8080
2.3.2 headless的service的mainifest
[root@node01 Chapter10]# cat kubia-service-public.yml apiVersion: v1 kind: Service metadata: name: kubia-service spec: selector: app: kubia ports: - port: 80 targetPort: 8080
2.4 这下所有需要的资源全部都已经创建好了,我们现在来看一下集群中资源的状况
[root@node01 Chapter10]# k get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv-a 10Mi RWO Recycle Bound default/data-kubia-1 110m pv-b 10Mi RWO Recycle Bound default/data-kubia-2 110m pv-c 10Mi RWO Recycle Bound default/data-kubia-0 110m [root@node01 Chapter10]# k get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE data-kubia-0 Bound pv-c 10Mi RWO 106m data-kubia-1 Bound pv-a 10Mi RWO 105m data-kubia-2 Bound pv-b 10Mi RWO 35m [root@node01 Chapter10]# k get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21d kubia ClusterIP None <none> 80/TCP 46m kubia-service ClusterIP 10.110.201.9 <none> 80/TCP 67m [root@node01 Chapter10]# k get statefulset NAME READY AGE kubia 3/3 106m [root@node01 Chapter10]# tree /tmp/ /tmp/ ├── pv-a │ └── kubia.txt ├── pv-b │ └── kubia.txt └── pv-c
- 第一个是我们创建的所有pv
- 第二个是statefulset创建的pvc,并且与我们创建的pv相绑定了
- 第三个是我们创建的2个svc
- 第四个是我们在业务在一些列运行之后产生的存储实际所在的位置
2.6 与statefulset关联的pod进行通信
之前提到过我们可以通过k proxy来进行与pod通信,也可以直接与api服务器进行通信从而,我们依旧使用k proxy与pod通信,具体方案如下
curl -X POST -d "the sun is not shining" localhost:8001/api/v1/namespaces/default/services/kubia-service/proxy/
2.7 删除pod以及缩容扩容statefulset里面的pod
由于statefulset管理也是的pod,这里我只阐述其中几点与RS/RC以及deployment不同的地方,其余的没提到不出意外的话都是一样的
- 扩容pod的时候一般都是从索引的最高数添加,缩容的时候也是同样,如果指定的话就会删除指定的pod
- 扩容pod的时候,如果有存储的话,同时也需要添加pv以及pvc
- 缩容pod的时候,不需要删除pv以及pvc,因为一旦删除之后,之前那个pod的数据持久化就不存在了
- 当出现无法删除的时候我们需要使用强制删除的命令,将其删除
k delete po kubia-0 --force --grace-period 0
2.8 一个需要注意的地方就是,犹如statefulset的特殊性,集群内部部署pod之间并无法直接通信,如果一个客户端需要拿到它们存储的数据所有数据的话,就需要对所有的pod都拿一次数据,并且由于后端挂载的servicde会随机的请求落到不同的pod上,实际上一个pod在不借助任何的外部工具下拿到所有的pod比上面描述的要男的多,这里提供一种比较好的方法用来拿到集群里面所有pod的数据方法,原理图如下所示
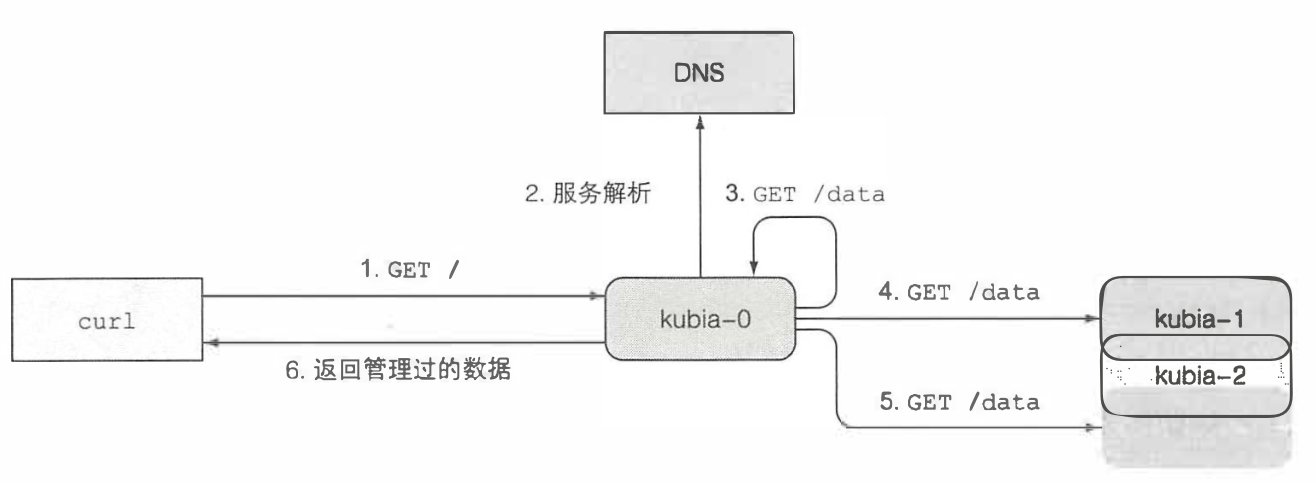
- 每个pod里面需要运行一个支持headless服务的SRV的记录查询
- 请求落到任意的pod的时候,该pod会去访问所有pod的数据
- 之后将数据统一的回复给客户端
2.9 下面来介绍一下SRV的记录
srv记录用来指向提供服务的服务器主机名和端口号,kubernets通过一个headless service创建SRV记录来指向pod的主机名,创建一个记录如下所示
k run -it srvlookup --image=tutum/dnsutils --rm --restart=Never --dig SRV kubia.default.svc.cluster.local