switch多分支结构根据case语句的不同一般分为一下几种情况:
一、在case语句小于3条时效率跟if……else的执行效率差距不大,不同的是switch是把所有的判断集中放到一起,判断完成后直接跳到相应case语句的地址处,而if……else结构则是每一个判断后紧跟着相应的语句。这里我们主要分析的是case语句大于3条的情况,我们以下面的程序为例分析一下case值有序线性的switch结构(case差值不能大于6):
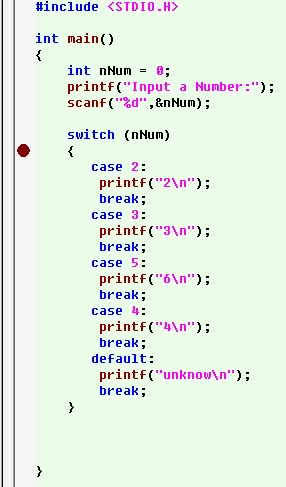
其对应的反汇编代码如下:
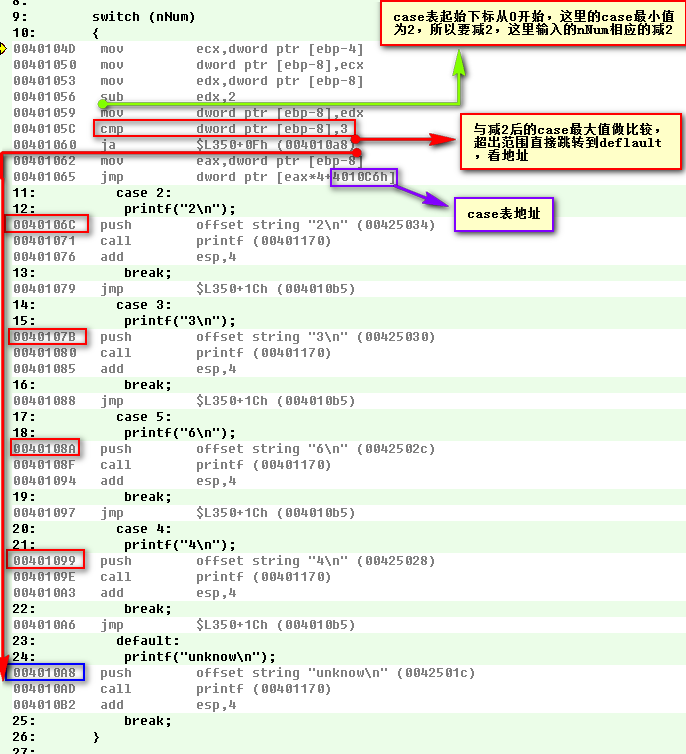
Switch结构运行时,会制作一个case语句地址数组,即case表,里面存放着每条case语句的首地址,上图中红色框内的地址,数组下标就用case语句中case值,这样地址就与case值一一对应。,因为数组起始下标要从零开始,但是这里的case最小值是从2开始,所以要将所有case值进行减2操作,也包括输入进来的nNum值。既然case表的构造是以case值大小顺序来的,所以不管case语句如何顺序排列,case表中地址都应该是这样的:
|
Case值 |
Case语句首地址 |
|
2 |
0040106C |
|
3 |
0040107B |
|
4 |
00401099 |
|
5 |
0040108A |
我们看一下内存中case表的内容,将case表地址4010C6输入到VC内存查看工具中,可以发现
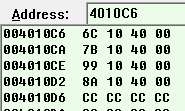
这里我们看的是case值按照顺序来的,如果case值不是连续的,比如2 ,3,5,7时,程序就用default的地址来代替缺省的case值4,6地址

这里default的地址是004010A8,按照推论地址应该的排列顺序是:
|
Case值 |
Case语句首地址 |
|
2 |
0040106C |
|
3 |
0040107B |
|
缺省 |
004010A8 |
|
5 |
00401099 |
|
缺省 |
004010A8 |
|
7 |
0040108A |
看一下case表中内容正是这样:
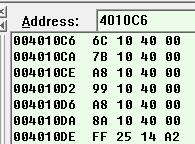
编译器将case地址顺序排列的前提是case语句数不能小于4条,同时case值是有序线性排列的(case差值不能大于6),这样缺省的值会由switch结束地址或者是default的地址来代替。
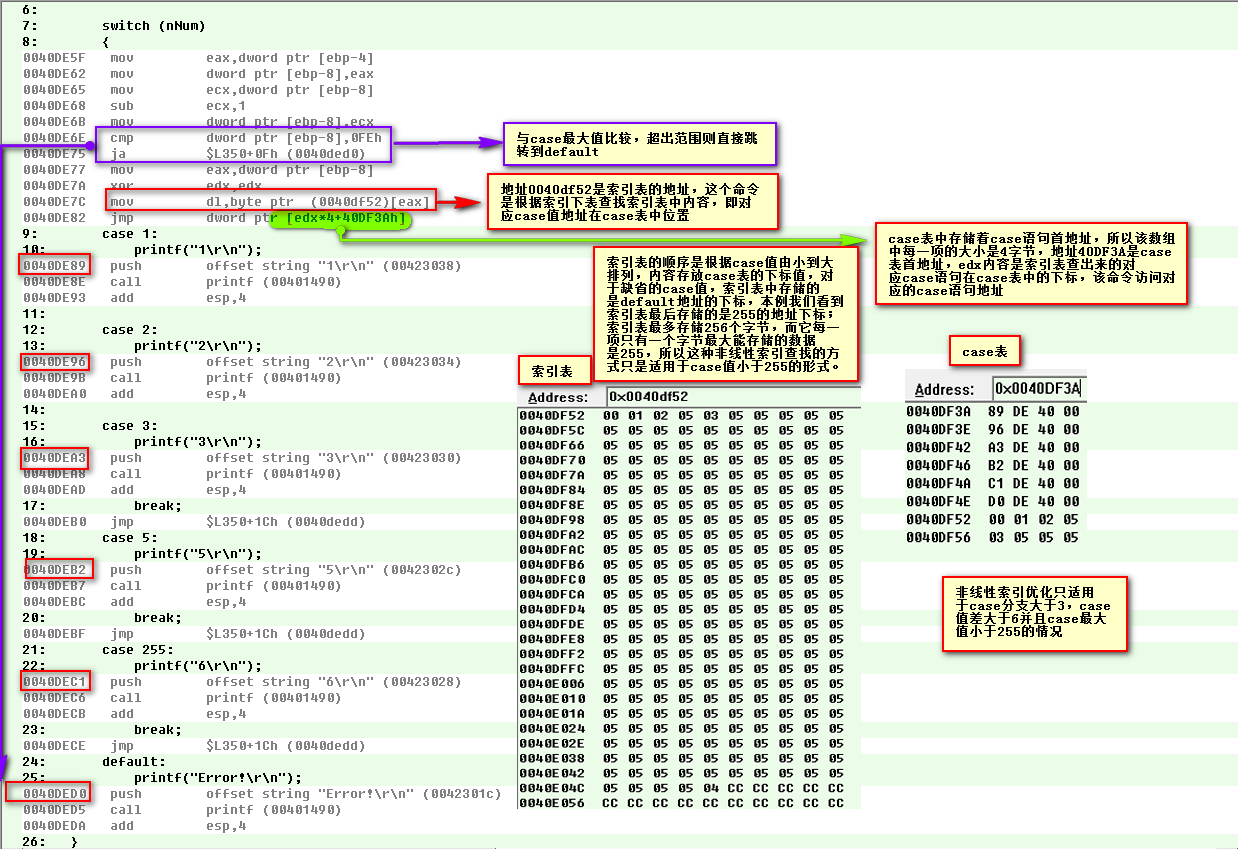
二、以上我们讨论的都是case值线性情况,如果case的值之间的差值大于6,即呈现非线性的话,上述方式就不能起作用了,在case表中如果我们依然将缺省的case值地址用default地址代替,将会造成很大的内存浪费。这里用的是非线性索引优化具体如图:
三、如果是case值大于255的情况上述方式也不行,这时候用的是二叉树查找的方式:取case中间值作为根节点,大于根节点的放于左子树,小于的放到右子树。实际上为了降低树,提高查找效率,程序会根据情况用结合上述几种优化,if……else优化、有序线性优化、非线性索引优化。