本文将介绍一篇很有意思的论文,该方向比较新,故本文保留了较多论文中的设计思路,背景知识等相关内容。
前言:
人类具有识别环境中未知对象实例的本能。当相应的知识最终可用时,对这些未知实例的内在好奇心有助于了解它们。 这促使我们提出一个新的计算机视觉问题,称为:“开放世界对象检测”,其中模型的任务是:
1)将尚未引入的对象识别为“未知”,无需明确监;
2)在逐渐接收到相应的标签时,逐步学习这些已识别的未知类别,而不会忘记先前学习的类别。
我们制定了这个问题,引入了评估协议并提供了一种新颖的解决方案,我们称之为 ORE:开放世界对象检测器,基于对比聚类和基于能量的未知对象识别。
我们的实验评估和消融研究分析了 ORE 在实现开放世界目标方面的功效。作为一个有趣的副产品,我们发现识别和表征未知实例有助于减少增量心理对象检测设置中的混乱,在那里我们实现了SOTA性能,而无需额外的方法论。我们希望我们的工作能够吸引对这个新确定但至关重要的研究方向的进一步研究。
论文:Towards Open World Object Detection
源码:https://github.com/JosephKJ/OWOD
关注公众号CV技术指南,及时获取更多计算机视觉技术总结文章。
本文出发点
深度学习加速了目标检测研究的进展,其中模型的任务是识别和定位图像中的对象。 所有现有的方法都在一个强有力的假设下工作,即所有要检测的类在训练阶段都可用。当我们放宽这个假设时会出现两个具有挑战性的场景:
1)测试图像可能包含来自未知类的对象,这些对象应该被归类为未知。
2)当有关此类已识别未知数的信息(标签)可用时,模型应该能够逐步学习新类。
发展心理学研究发现识别未知事物的能力是吸引好奇心的关键。这种好奇心激发了学习新事物的欲望。 这促使我们提出一个新问题,即模型应该能够将未知对象的实例识别为未知对象,然后在训练数据逐渐到达时以统一的方式学习识别它们。 我们将此问题设置称为开放世界对象检测。
开放世界对象检测设置比现有的封闭世界、静态学习设置更自然。 世界在新类的数量、类型和配置方面是多样化和动态的。 我们不能假设在训练期间可以看到推理时期望的所有类。 检测系统在机器人、自动驾驶汽车、植物表型分析、医疗保健和监控中的实际部署无法在内部训练的情况下全面了解推理时预期的类别。
人们可以从部署在这种设置中的对象检测算法中期望的最自然和现实的行为是自信地将未知对象预测为未知,并将已知对象归入相应的类。 当有关已识别未知类的更多信息可用时,系统应该能够将它们合并到其现有的知识库中。 这将定义一个智能对象检测系统,我们正在努力实现这一目标。
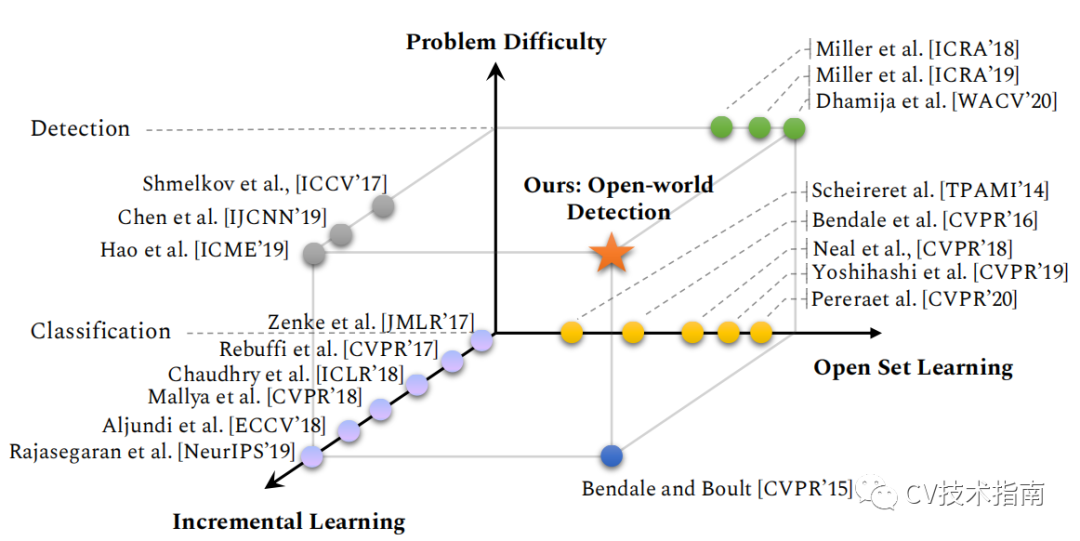
![]()
计算机视觉任务难度图
本文贡献
• 我们引入了一种新颖的问题设置,即开放世界对象检测,它更接近地模拟现实世界。
• 我们开发了一种称为 ORE 的新方法,它基于对比聚类、未知感知提议网络和基于能量的未知识别,以应对开放世界检测的挑战。
• 我们引入了一个全面的实验设置,它有助于测量对象检测器的开放世界特征,并根据竞争基线方法对其进行基准测试。
• 作为一个有趣的副产品,所提出的方法在增量对象检测方面实现了最先进的性能,即使主要不是为此而设计的。
Open World Object Detection

![]()
开放世界对象检测设置考虑了一个对象检测模型 Mc,该模型经过训练可以检测所有以前遇到的 C 个对象类。 重要的是,模型 MC 能够识别属于任何已知 C 类的测试实例,并且还可以通过将其分类为未知类实例来识别新的或未见过的类实例,用标签(0) 表示。然后人类将未知的实例集 Ut识别 n 个新的感兴趣类(在潜在的大量未知数中)并给模型提供训练示例。
学习器逐步添加 n 个新类并自行更新以生成更新的模型 MC+n,而无需在整个数据集上从头开始重新训练。已知类集也更新 Kt+1 = Kt + {C + 1, ... . . ,C+n}。这个循环在物体检测器的整个生命周期中持续,在那里它用新知识自适应地更新自己。
ORE(开放世界目标检测器)
一种成功的开放世界对象检测方法应该能够在没有明确监督的情况下识别未知实例,并且在将这些识别出的新实例的标签呈现给模型以进行知识升级(无需从头开始重新训练)时,不会忘记早期实例。 我们提出了一个解决方案 ORE,它以统一的方式解决了这两个挑战。
设计思路如下:
神经网络是通用函数逼近器,它通过一系列隐藏层学习输入和输出之间的映射。在这些隐藏层中学习的潜在表示直接控制每个功能的实现方式。 我们假设在对象检测器的潜在空间中学习明确区分类别可能会产生双重影响。
首先,它帮助模型识别未知实例的特征表示与其他已知实例有何不同,这有助于将未知实例识别为新颖性。 其次,它有助于学习新类实例的特征表示,而不会与潜在空间中的先前类重叠,这有助于在不遗忘的情况下进行增量学习。帮助我们意识到这一点的关键部分是我们在潜在空间中提出的对比聚类。
为了使用对比聚类对未知数进行最佳聚类,我们需要对未知实例进行监督。 即使是潜在的无限未知类集的一小部分,手动注释也是不可行的。 为了解决这个问题,我们提出了一种基于区域提议网络(RPN) 的自动标记机制来伪标记未知实例。 潜在空间中自动标记的未知实例的固有分离有助于我们基于能量的分类头区分已知和未知实例。
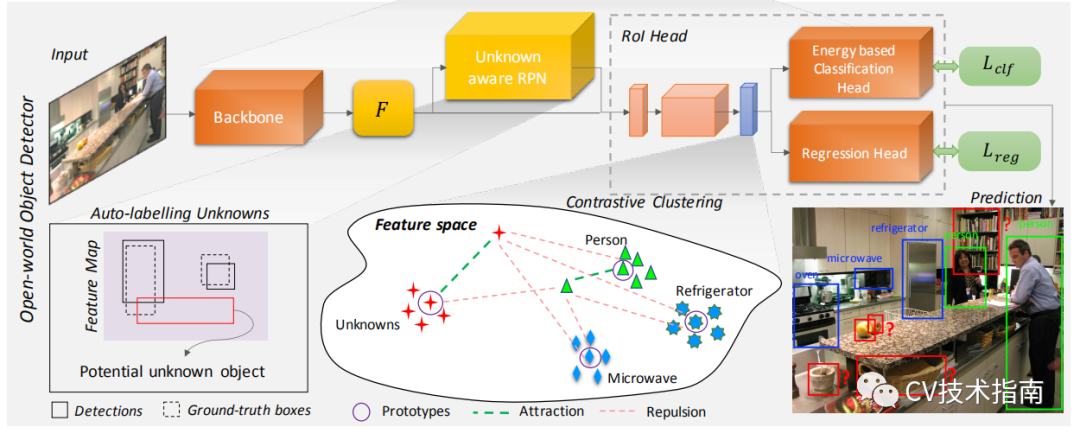
![]()
如上图所示,选择 Faster R-CNN 作为基础检测器。与单阶段的Retina Net 检测器和YOLO 检测器相比,它具有更好的开放集性能。
Faster R-CNN是一个两阶段的目标检测器。在第一阶段,一个与类别无关的区域提议网络 (RPN) 从共享骨干网络的特征图中提出可能具有对象的潜在区域。第二阶段对每个提议区域的边界框坐标进行分类和调整。由感兴趣区域 (RoI) 头部中的残差块生成的特征进行对比聚类。RPN 和分类头分别用于自动标记和识别未知数。
对比聚类算法如下:

![]()
Auto-labelling Unknowns with RPN
我们基于区域提议网络 (RPN) 与类别无关的事实。给定输入图像,RPN 为前景和背景实例生成一组边界框预测,以及相应的对象分数。我们将那些具有高对象分数但不与真实对象重叠的提议标记为潜在的未知对象。简单地说,我们选择前 k 个背景区域提议,按其对象性分数排序,作为未知对象。
Energy Based Unknown Identififier
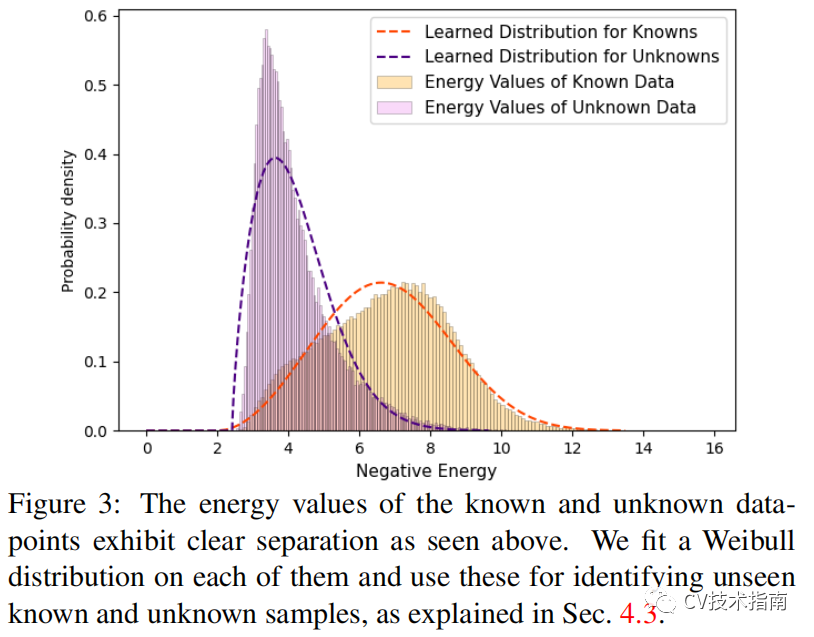
![]()
由于通过对比聚类在潜在空间中实施了清晰的分离,可以看到已知类数据点和未知数据点的能级明显分离,如上图所示。我们通过energy based models(EBMs)来学习一个能量函数,使用单个输出标量来估计观察变量 F 和可能的输出变量集 L 之间的兼容性。
Alleviating Forgetting
我们考虑了终身学习中的很多方法,最终决定使用相对简单的 ORE 方法来减轻遗忘,即我们存储一组平衡的示例并在每个增量步骤之后微调模型。在每一点上,我们确保每个类的最少 Nex 实例存在于示例集中。
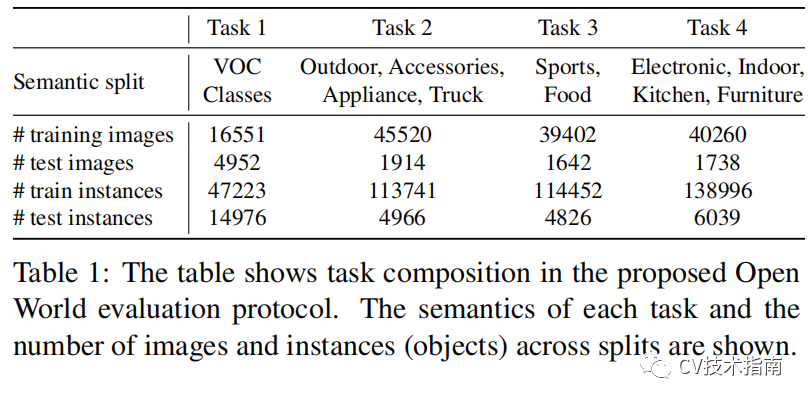
评协议
![]()
实验结果
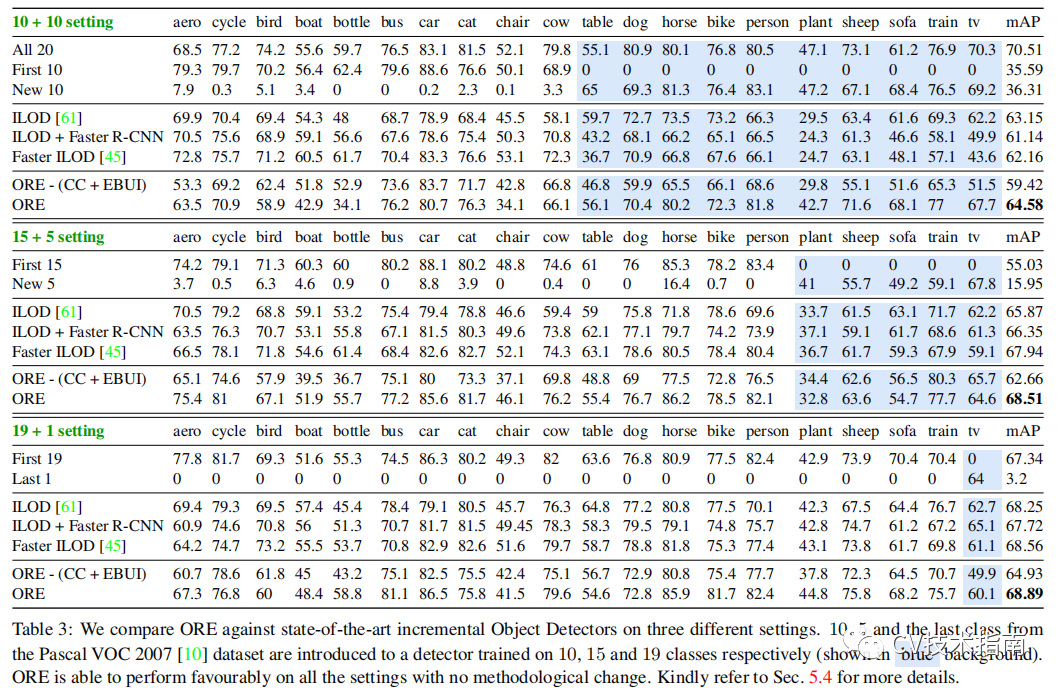
![]()
蓝色部分为刚开始作为背景,在经过ORE训练后自主识别的准确度。

![]()
该图展示了ORE通过RPN很好地识别了一些未知对象,但在第三张图中也有指鹿为马的现象出现。
本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。


其它文章