本文翻译自博客:
《Do We Really Need Model Compression?》
作者:Mitchell A. Gordon
前言:
模型压缩是一种缩小训练后的神经网络的技术。 压缩的模型在使用少量计算资源的情况下,其性能通常与原始模型相似。 但是,在许多应用程序中,瓶颈被证明是在压缩之前训练原始的大型神经网络。例如,可以在低成本的GPU(12 GB的内存)上训练基于BERT的模型,但是BERT-large需要在Google TPU(64 GB的内存)上训练,这使许多人无法尝试使用预训练的语言模型。
模型压缩领域的结果告诉我们,我们收敛的解决方案通常比最初训练的模型具有更少的参数。那么,是什么阻止我们通过从头训练小型模型来节省GPU内存呢?
在这篇文章中,我们将探索从头开始训练小型模型所涉及的困难。我们将讨论模型压缩为何起作用,以及两种进行内存有效训练的方法:过量参数的界限和更好的优化方法,这些方法可以减少或消除事后模型压缩。最后我们将总结未来的研究方向。
Appropriately-Parameterized Models
适量参数的模型--既没有过量参数也没有欠参数的模型,而是具有合适数量的参数以表示任务的理想解决方案的模型。
我们通常不会在深度学习范式中训练适量参数的模型。这是因为对于给定的数据集,通常不知道使用多少参数量合适。即使知道了解决方案,众所周知,使用梯度下降法训练适量参数的模型也很困难。
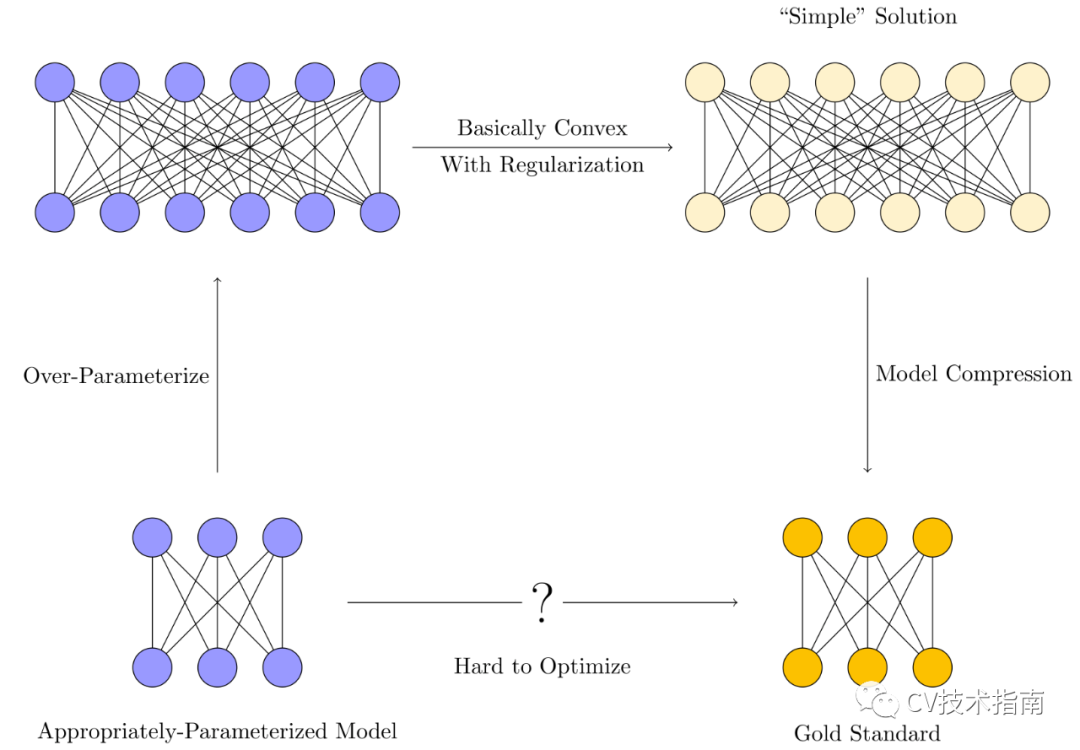
相反,训练程序通常看起来像这样:
![]()
- 我们会训练一个过参数化的模型。这些模型通常具有比训练样本数量更多的参数。
- 各种正则化技术(隐式或其他)用于约束优化,以偏向于“简单解决方案”而不是过度拟合。
- 模型压缩通过消除冗余来提取嵌入在较大模型中的“简单”模型,使内存和时间效率更接近理想的适量参数的模型。
极端的过度参数化使训练变得更加容易。 但是,由于模型被过度参数化,因此它们可以存储数据,而不是学习数据中的有用模式,因此需要进行正则化。 然后,模型压缩利用这种简单性仅保留解决方案实际需要的参数。
由于我们的目标是使用更少的GPU内存来训练神经网络,因此我们可以提出一些明显的问题:
- 为什么需要过度参数化? 需要多少过参数化?
- 我们可以通过使用更智能的优化方法来减少过度参数化吗?
接下来的两个部分将依次解决这些问题。
Over-parameterization Bounds
为什么需要超量参数?通过充分超量参数的神经网络,我们可以使优化的landscape有效凸出。 杜etc(2019)、Haeffele和Vidal(2017)在一些简单情况下对此进行了数学证明,给出了必要的过参数化量,能在多项式时间内实现0训练损失。有效地,过度参数化是为了增加内存使用量而牺牲了计算难易度。
这些界限通常被认为是宽松的。 这意味着尽管我们可以预测出足够数量的参数来完美拟合某些数据,但我们仍然不知道要完美拟合数据所需的最小参数数量。 严格的界限可能取决于从优化过程(SGD与GD,Adam与其他)到体系结构的所有方面。计算严格边界甚至比训练所有可能的候选网络在计算上更加棘手。
但是,在这方面肯定还有改进的余地。严格的过度参数化范围将使我们可以训练较小的网络,而无需在架构上进行网格搜索,也不必担心更大的网络可能为我们带来更好的性能。 证明是否可以扩展到recurrent models, transformers,按batch norm训练的模型等仍然存在问题。
上面忽略了提及不同的体系结构可能具有不同的过参数化范围的情况。 那么,一种合理的方法是使用具有较低过参数化范围的不同体系结构。 一些有趣的“efficient transformers”包括Reformer,ALBERT,Sparse Transformers和SRU。
Better Optimization Techniques
从经验上讲,很难对参数正确的模型进行训练。 用梯度下降训练适当大小的模型通常会严重失败。 该模型将无法收敛以适合训练数据,更不用说泛化了。这部分由神经网络的优化环境的非凸性/ non-friendliness来部分解释,但是训练适量参数化模型的计算复杂度的精确表征仍然不完整。
模型压缩技术通过阐明过参数化模型趋于收敛的解的类型,为我们提供了有关如何训练适当参数化模型的提示。 模型压缩的类型很多,每种模型都利用一种不同类型的“简单性”,这种“简单性”往往在训练有素的神经网络中发现:
-
许多权重接近零(修剪)
-
权重矩阵低秩(权重分解)
-
权重只用几位来表示(量化)
-
层通常会学习类似的功能(权重共享)
这些“简单性”中的每一个都是由于训练过程中的正则化(隐式或其他)或训练数据的质量而引起的。当我们知道我们正在寻找具有这些特性的解决方案时,它为改进我们的优化技术开辟了令人振奋的新方向。
Sparse Networks from Scratch
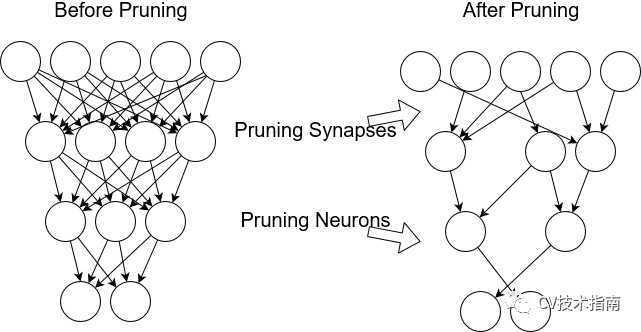
权重修剪可能是最成功的压缩方法示例,可以将压缩方法转变为优化方法。 经过训练的神经网络通常具有许多权重(30-95%),它们接近于0。可以删除这些权重而不会影响神经网络的输出。
![]()
我们是否可以通过从一开始就训练稀疏神经网络来减少GPU使用,而不是事后修剪呢?有一阵子,我们认为答案是否定的。稀疏的网络很难训练;优化环境非常不凸且不友好。
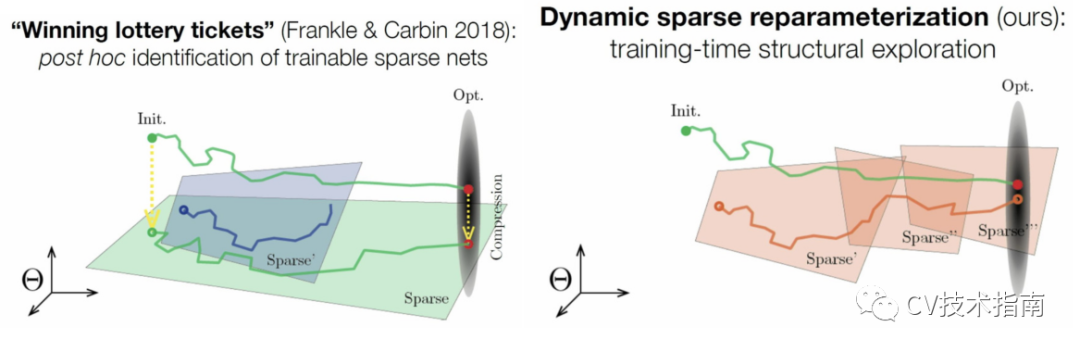
然而,Frankel和Carbin(2018)朝着这个方向迈出了第一步。他们发现他们可以从头开始重新训练修剪的网络,但前提是必须将其重新初始化为在密集训练期间使用的相同初始化。他们对此的解释是the Lottery Ticket Hypothesis:密集网络实际上是许多适量参数化的稀疏模型的并行随机初始化组合。 碰巧得到了幸运的初始化并收敛于解决方案。
![]()
最近,Dettmers和Zettlemoyer(2019),Mostafa(2019),和Evci 等人(2019),指明可以从头开始训练适当参数化的稀疏网络,从而大大减少了训练神经网络所需的GPU内存量。重要的不是初始化,而是探索模型的稀疏子空间的能力。Lee等人的类似工作(2018),尝试通过对数据进行一次传递来快速找到合适的稀疏架构。
我相信,其他类型的模型压缩可能会重复这种模式。 一般而言,模式是:
- 模型压缩方法揭示了训练后的神经网络中的一些常见冗余。
- 研究了造成这种冗余的归纳偏差/正则化。
- 从训练开始,就创建了一种巧妙的优化算法来训练没有这种冗余的网络。
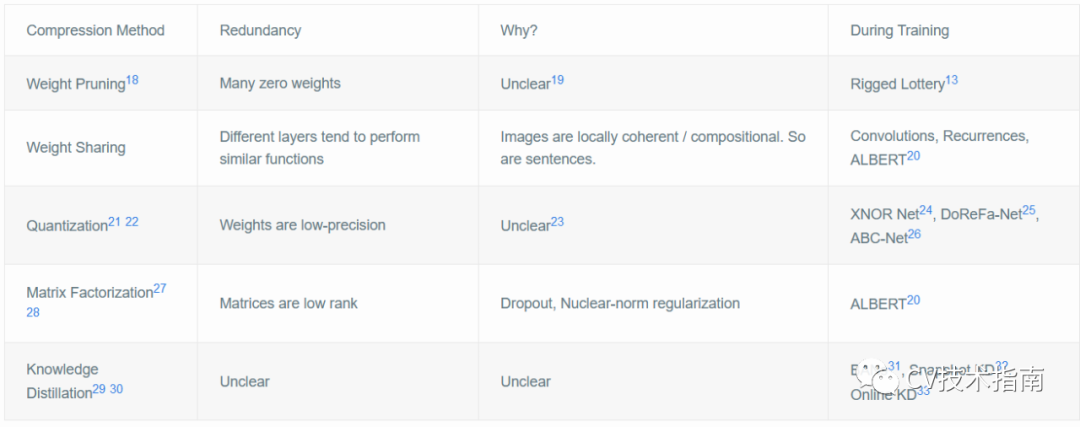
下表列出了其他类型的模型压缩,以及为使模型更接近训练的开始而付出的努力16(成功水平各不相同)
![]()
Future Directions
我们真的需要模型压缩吗? 这篇文章的标题具有挑衅性,但想法并非如此:通过收紧过度参数化的界限并改善我们的优化方法,我们可以减少或消除对事后模型压缩的需求。 显然,在我们有一个明确的答案之前,仍有许多悬而未决的问题需要回答。 以下是我希望在未来几年完成的一些工作。
超量参数方面
-
我们可以通过窥视数据质量(使用低资源计算)来获得更紧密的界限吗?
-
如果我们使用巧妙的优化技巧(如Rigged Lottery13),超参数化界限会如何变化?
-
我们可以得到强化学习环境的过度参数化界限吗?
-
我们可以将这些范围扩展到其他常用的体系结构(RNN,Transformers)吗?
优化方面
-
我们没有利用的经过训练的神经网络中还有其他冗余吗?
-
使这些变得可行:
从头开始训练量化的神经网络。
从头开始使用低秩矩阵训练神经网络。
-
弄清楚为什么知识蒸馏可以改善优化。如果可能的话,使用类似的想法进行优化,同时使用更少的GPU内存。
正则化方面
-
哪些类型的正则化会导致哪些类型的模型冗余?
-
修剪和重新训练与L0正则化有何关系?哪些隐式正则化导致可修剪性?
-
哪些类型的正则化可以量化?
原文链接:
http://mitchgordon.me/machine/learning/2020/01/13/do-we-really-need-model-compression.html#fn:lottery-general
本文来源于公众号CV技术指南的论文分享系列,更多内容请扫描文末二维码关注公众号。

![]()