索引(也叫做“键(key)”)是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量非常大时。索引可以包含一个或者多个列的值。如果索引包含多个列,那么列的顺序十分重要,因为MySQL只能使用索引的最左前缀列。
1.索引的创建和删除
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引的实例如下:


ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。PRIMARY KEY索引和UNIQUE索引非常类似。事实上,PRIMARY KEY索引仅是一个具有名称PRIMARY的UNIQUE索引。这表示一个表只能包含一个PRIMARY KEY,因为一个表中不可能具有两个同名的索引。下面的SQL语句对students表在sid上添加PRIMARY KEY索引。
ALTER TABLE students ADD PRIMARY KEY (sid)
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉table_name中的索引index_name。第3条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
2.索引的类型
在MySql中索引是在存储引擎层实现,所以并没有统一的索引标准:不同的存储引擎的索引工作方式不一样。
2.1 B-Tree索引
B-Tree索引使用B-Tree数据结构来存储数据。实际上在很多存储引擎使用的是B+Tree(每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围查询)。不同的存储引擎以不同的方式使用B-Tree索引,MyISAM使用前缀压缩技术使索引更小,但InnoDB则按照原数据格式进行存储。MyISAM索引通过数据的物理位置引用被索引的行,而InnoDB则根据主键引用被索引的行。
B-Tree索引通常意味着所有值都是按顺序存储点,并且每一个叶子节点到跟的距离相同。下图反应了InnoDB的索引是如何工作的。

B-Tree索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据。B-Tree索引对列是顺序组织的,所以很适合范围查询。如下数据表:
CREATE TABLE Peaple ( last_name VARCHAR (50) NOT NULL, first_name VARCHAR (50) NOT NULL, dob DATE NOT NULL, gender ENUM ('m', 'f') NOT NULL, KEY (last_name, first_name, dob) );
其索引是如下图组织数据存储的:
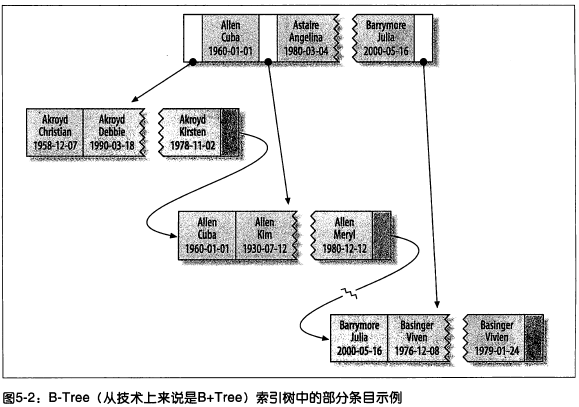
索引对多个值进行排序的依据是CREATE TABLE语句中定义索引时列的顺序 B-Tree索引对如下类型的查询有效:
- 全值匹配:指和索引中所有列进行匹配。
- 匹配最左前缀。
- 匹配列前缀:只匹配某一列的值的开头部分。
- 匹配范围值。
- 精确匹配某一列并范围匹配另外一列。
- 只访问索引的查询。
索引树中的节点是有序的,除了按值查找外,索引还可以用户查询中的Order BY操作。
B-Tree索引使用的限制:
- 如果不是按照索引的最左列开始查找,则无法使用索引。
- 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
2.2Hash索引
哈希索引基于哈希表实现,只能精确匹配索引所有列的查询才有效。在MySQL中,只有Memory引擎显示支持哈希索引。哈希索引存在以下限制:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。
- 哈希索引数据不是按照索引值进行顺序存储的所以无法用于排序。
- 哈希索引不支持部分索引列匹配查找。
- 哈希索引只支持等值比较查询,包括=、IN()、和<==>,不支持任何范围查询。
- 存在哈希冲突现象。
InnoDB引擎有一个特殊的“自适应哈希索引”。当InnoDB注意到某些索引值被频繁使用时,它会在内存中基于B-Tree索引之上再创建一个Hash索引。这个行为是完全自动的、内部行为,用户无法配置或者控制,如果有必要可以关闭该功能。
2.3自定义哈希索引
如果存储引擎不支持哈希索引,则可以自己定义哈希索引。具体思路是:在B-Tree基础之上创建一个伪哈希索引。这和真正的哈希所用不完全相同,因为还是使用B-Tree进行查找,但是它使用哈希值而不是键本身进行索引查找。你需要做的就是在查询的Where字句中手动指定使用哈希函数。
例如需要存储大量的URL,并需要根据URL进行搜索查找。如果使用B-Tree来存在URL,存储的内容就很大。例如如下查询:
MySql>SELECT id FROM url WHERE url='http://www.mysql.com';
若删除删除原来URL列上的索引,而新增一个被索引的url_crc列,使用CRC32做哈希,就可以使用下面的方式查询:
MySql>SELECT id FROM url WHERE url='http://www.mysql.com' AND url_crc=CRC32('http://www.mysql.com');
对于这种实现的缺陷是需要维护哈希值,哈希值可以使用触发器实现。同时为了处理哈希冲突,当使用哈希索引进行查找时,必须在WHERE子句中包含常量值。
3.索引的优点
索引可以让服务器快速定位到表指定的位置,但这不是索引唯一的作用。
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O