快速排序是20世纪科技领域的十大算法之一 ,他由C. A. R. Hoare于1960年提出的一种划分交换排序。快速排序也是一种采用分治法解决问题的一个典型应用。在很多编程语言中,对数组,列表进行的非稳定排序在内部实现中都使用的是快速排序。而且快速排序在面试中经常会遇到。本文首先介绍快速排序的思路,算法的实现、分析、优化及改进。
一 原理

快速排序的基本思想如下:

如上图所示快速排序的一个重要步骤是对序列进行以中轴数进行划分,左边都小于这个中轴数,右边都大于该中轴数,然后对左右的子序列继续这一步骤直到子序列长度为1。下面来看某一次划分的步骤,如下图:

上图中的划分操作可以分为以下5个步骤:
- 获取中轴元素
- i从左至右扫描,如果小于基准元素,则i自增,否则记下a[i]
- j从右至左扫描,如果大于基准元素,则i自减,否则记下a[j]
- 交换a[i]和a[j]
- 重复这一步骤直至i和j交错,然后和基准元素比较,然后交换。
划分过程的代码实现如下:
划分前后,元素在序列中的分布如下图:
private static int partition(Comparable[] arr, int low, int high) {
int i = low, j = high + 1;
Comparable v = arr[low];
while (true) {
while (less(arr[++i], v)) {
if (i == high)
break;
}
while (less(v, arr[--j])) {
if (j == low)
break;
}
if (i >= j)
break;
exch(arr, i, j);
}
exch(arr, low, j);
return j;
}
二 实现
public class QuickSort {
public static void sort(Comparable[] arr) {
shuffleArr(arr);
sort(arr, 0, arr.length - 1);
}
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w) < 0;
}
private static void sort(Comparable[] arr, int low, int high) {
if (high <= low)
return;
int j = partition(arr, low, high);
sort(arr, low, j - 1);
sort(arr, j + 1, high);
}
private static int partition(Comparable[] arr, int low, int high) {
...
}
private static void shuffleArr(Comparable[] arr) {
...
}
}
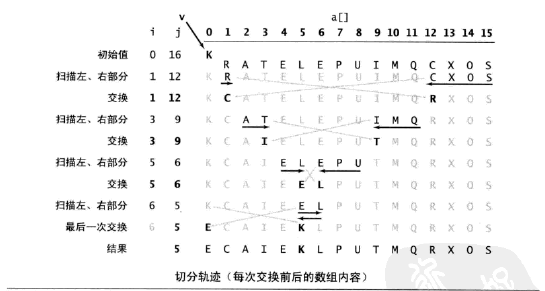
下图说明了快速排序中,每一次划分之后的结果:

一般快速排序的动画如下:

三 分析
- 在最好的情况下,快速排序只需要大约nlgn次比较操作,在最坏的情况下需要大约1/2 n2 次比较操作。在最好的情况下,每次的划分都会恰好从中间将序列划分开来,那么只需要lgn次划分即可划分完成,是一个标准的分治算法Cn=2Cn/2+N,每一次划分都需要比较N次,大家可以回想下我们是如何证明合并排序的时间复杂度的。

- 在最坏的情况下,即序列已经排好序的情况下,每次划分都恰好把数组划分成了0,n两部分,那么需要n次划分,但是比较的次数则变成了n, n-1, n-2,….1, 所以整个比较次数约为n(n-1)/2~n2/2.

- 平均情况下,快速排序需要大约1.39NlgN次比较,这比合并排序多了39%的比较,但是由于涉及了较少的数据交换和移动操作,他要比合并排序更快。
- 为了避免出现最坏的情况,导致序列划分不均,我们可以首先对序列进行随机化排列然后再进行排序就可以避免这一情况的出现。
- 快速排序是一种就地(in-place)排序算法。在分割操作中只需要常数个额外的空间。在递归中,也只需要对数个额外空间。
- 另外,快速排序是非稳定性排序。

四 改进
对一般快速排序进行一些改进可以提高其效率。
1. 当划分到较小的子序列时,通常可以使用插入排序替代快速排序。对于较小的子序列(通常序列元素个数为5-15个左右),我们就可以采用插入排序直接进行排序而不用继续递归,算法改造如下:

2. 三平均分区法(Median of three partitioning)
在一般的的快速排序中,选择的是第一个元素作为中轴(pivot),这会出现某些分区严重不均的极端情况,比如划分为了1和n-1两个序列,从而导 致出现最坏的情况。三平均分区法与一般的快速排序方法不同,它并不是选择待排数组的第一个数作为中轴,而是选用待排数组最左边、最右边和最中间的三个元素 的中间值作为中轴。这一改进对于原来的快速排序算法来说,主要有两点优势:
(1) 首先,它使得最坏情况发生的几率减小了。
(2) 其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。如果在分区排序时,中间的这个元素(也即中轴)是与最右边数过来第二个元素进行交换的话,那么就可以省略与这一哨点值的比较。
对于三平均分区法还可以进一步扩展,在选取中轴值时,可以从由左中右三个中选取扩大到五个元素中或者更多元素中选取,一般的,会有(2t+1)平均 分区法(median-of-(2t+1)。常用的一个改进是,当序列元素小于某个阈值N时,采用三平均分区,当大于时采用5平均分区。
采用三平均分区法对快速排序的改进如下:
private static void Sort(Comparable[] array, int lo, int hi) {
int m = MedianOf3(array, lo, lo + (hi - lo) / 2, hi);
exch(array, lo, m);
int index = partition(array, lo, hi);
Sort(array, lo, index - 1);
Sort(array, index + 1, hi);
}
private static int MedianOf3(Comparable[] array, int lo, int center, int hi) {
return (less(array[lo], array[center]) ? (less(array[center], array[hi]) ? center
: less(array[lo], array[hi]) ? hi : lo)
: (less(array[hi], array[center]) ? center : less(array[hi],
array[lo]) ? hi : lo));
}
使用插入排序对小序列进行排序以及使用三平均分区法对一般快速排序进行改进后运行结果示意图如下:

3. 三分区(3-way partitioning) 快速排序
通常,我们的待排序的序列关键字中会有很多重复的值,比如我们想对所有的学生按照年龄进行排序,按照性别进行排序等,这样每一类别中会有很多的重复 的值。理论上,这些重复的值只需要处理一次就行了。但是一般的快速排序会递归进行划分,因为一般的快速排序只是将序列划分为了两部分,小于或者大于等于这 两部分。既然要利用连续、相等的元素不需要再参与排序这个事实,一个直接的想法就是通过划分让相等的元素连续地摆放:

然后只对左侧小于V的序列和右侧大于V对的序列进行排序。这种三路划分与计算机科学中无处不在,它与Dijkstra提出的“荷兰国旗问题”(The Dutch National Flag Problem)非常相似。
Dijkstra的方法如上图:从左至右扫描数组,维护一个指针lt使得[lo…lt-1]中的元素都比v小,一个指针gt使得所有[gt+1….hi]的元素都大于v,以及一个 指针i,使得所有[lt…i-1]的元素都和v相等。元素[i…gt]之间是还没有处理到的元素,i从lo开始,从左至右开始扫描:
- 如果a[i]<v: 交换a[lt]和a[i],lt和i自增
- 如果a[i]>v:交换a[i]和a[gt], gt自减
- 如果a[i]=v: i自增
下面是使用Dijkstra的三分区快速排序代码:
private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) return;
int lt = lo, gt = hi;
Comparable v = a[lo];
int i = lo;
while (i <= gt) {
int cmp = a[i].compareTo(v);
if (cmp < 0) exch(a, lt++, i++);
else if (cmp > 0) exch(a, i, gt--);
else i++;
}
// a[lo..lt-1] < v = a[lt..gt] < a[gt+1..hi].
sort(a, lo, lt-1);
sort(a, gt+1, hi);
}
三分区快速排序的每一步如下图所示:

三分区快速排序的示意图如下:

Dijkstra的三分区快速排序虽然在快速排序发现不久后就提出来了,但是对于序列中重复值不多的情况下,它比传统的2分区快速排序需要更多的交换次数。Bentley 和D. McIlroy在普通的三分区快速排序的基础上,对一般的快速排序进行了改进。在划分过程中,i遇到的与v相等的元素交换到最左边,j遇到的与v相等的元素交换到最右边,i与j相遇后再把数组两端与v相等的元素交换到中间

这个方法不能完全满足只扫描一次的要求,但它有两个好处:首先,如果数据中没有重复的值,那么该方法几乎没有额外的开销;其次,如果有重复值,那么这些重复的值不会参与下一趟排序,减少了无用的划分。下面是采用 Bentley&D. McIlroy 三分区快速排序的算法改进:
private static void sort(Comparable[] a, int lo, int hi) {
int N = hi - lo + 1;
// cutoff to insertion sort
if (N <= CUTOFF) {
insertionSort(a, lo, hi);
return;
}
// Bentley-McIlroy 3-way partitioning
int i = lo, j = hi+1;
int p = lo, q = hi+1;
Comparable v = a[lo];
while (true) {
while (less(a[++i], v))
if (i == hi) break;
while (less(v, a[--j]))
if (j == lo) break;
// pointers cross
if (i == j && eq(a[i], v))
exch(a, ++p, i);
if (i >= j) break;
exch(a, i, j);
if (eq(a[i], v)) exch(a, ++p, i);
if (eq(a[j], v)) exch(a, --q, j);
}
i = j + 1;
for (int k = lo; k <= p; k++)
exch(a, k, j--);
for (int k = hi; k >= q; k--)
exch(a, k, i++);
sort(a, lo, j);
sort(a, i, hi);
}
三分区快速排序的动画如下:

4.并行化
和前面讨论对合并排序的改进一样,对所有使用分治法解决问题的算法其实都可以进行并行化,快速排序的并行化改进我在之前的浅谈并发与并行这篇文章中已经有过介绍,这里不再赘述。
五 总结
由于快速排序在排序算法中具有排序速度快,而且是就地排序等优点,使得在许多编程语言的内部元素排序实现中采用的就是快速排序,本问首先介绍了一般的快速排序,分析了快速排序的时间复杂度,然后就分析了对快速排序的几点改进,包括对小序列采用插入排序替代,三平均划分,三分区划分等改进方法。