1.下载spark2.4.3 使用用户的hadoop的版本,解压并放到/usr/local下并改名为spark目录
![]()
2.设置spark目录为本用户所有
![]()
3.设置环境变量
(1)#~/.bashrc
export SPARK_HOME=/usr/local/spark
source ~/.bashrc

(2)cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
![]()
(3)进入 /usr/local/spark/conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
SPARK_LOCAL_IP="127.0.0.1"
![]()
4.单机模式
/usr/local/spark/bin/spark-shell

5.增加内容到最外层标签内,文件是/usr/local/hadoop/etc/hadoop/yarn-site.xml
![]()
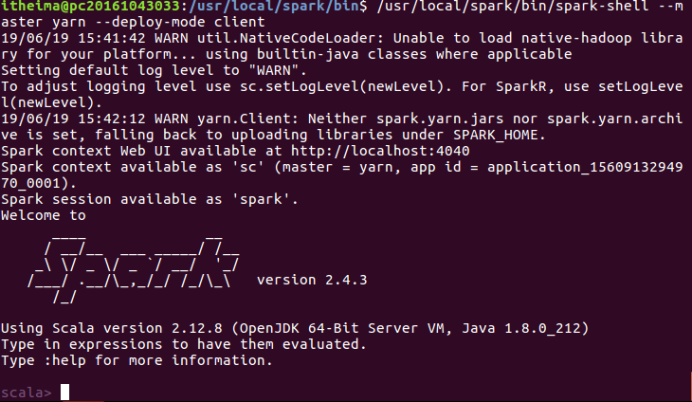
执行(yarn模式)
/usr/local/spark/bin/spark-shell --master yarn --deploy-mode client