一.tcp的三次握手分析:
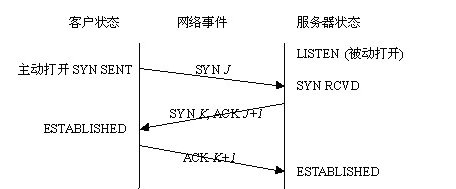
第一次握手:建立连接时,客户端发送 SYN 包(tcp协议中syn位置1,序号为J)到服务器,并进入 SYN_SEND 状态,等待服务器确认;
第二次握手:服务器收到 SYN 包,必须确认客户的 SYN,同时自己也发送一个 SYN 包,即 SYN+ACK包(tcp协议中syn位置1,ack位置1,序号K,确定序号为J+1),此时服务器进入 SYN_RCVD 状态;
第三次握手:客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(tcp协议中ack位置1,确认序号K+1),此包发送完毕,客户端和服务器进入 ESTABLISHED 状态,完成三次握手。
具体状态转换图如下:
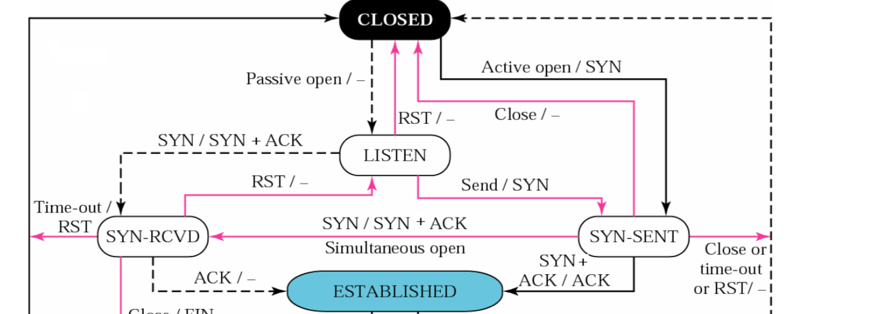
上图中A/B(A代表收到的消息,B代表发出的消息),沿着黑虚线是服务器端经过的状态,沿着黑实线是客户端的状态,红线是在三次握手的过程中出现其他状况是状态的相应的转换。
二.下面对在三次握手中所使用的具体函数进行分析,由上次实验我们知道了在三次握手中使用了socket、connect、listen、bind、accept等函数,本次实验我们看看这些函数具体如何调用其他函数完成相应的连接。
对于服务器端的流程——类似于接电话过程:
socket()[找到一个可以通话的手机]----->bind()[插入一个固定号码]------>listen()[随时准备接听]-------> accept------->recv()------->send()------>close();
对于客户端的主要流程----类似于打电话过程:
socket()----->connect()------>recv/read/send------>close()
流程如下图所示:

下面对具体函数分析:
在服务端:
1,socket:
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
当服务器程序调用socket系统调用之后,内核会创建一个struct socket和一个struct sock结构,两者可以通过指针成员变量相互访问对方。内核直接操作的是struct sock结构。struct socket的存在是为了适应linux的虚拟文件系统,把socket也当作一个文件系统,通过指定superblock中不同的操作函数实现完成相应的功能。在linux内核中存在不同的sock类型,与TCP相关的有struct sock、 struct inet_connection_sock,、struct tcp_sock等。这些结构的实现非常灵活,可以相互进行类型转换。这个机制的实现是结构体的一层层包含关系:struct tcp_sock的第一个成员变量是struct inet_connection_sock,struct inet_connection_sock的第一个成员变量是struct sock。
查找socket源码如下:
int __sys_socket(int family, int type, int protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
struct socket源码如下:
struct socket {
socket_state state; // 连接状态:SS_CONNECTING, SS_CONNECTED 等
short type; // 类型:SOCK_STREAM, SOCK_DGRAM 等
unsigned long flags; // 标志位:SOCK_ASYNC_NOSPACE(发送队列是否已满)等
struct socket_wq __rcu *wq; // 等待队列
struct file *file; // 该socket结构体对应VFS中的file指针
struct sock *sk; // socket网络层表示,真正处理网络协议的地方
const struct proto_ops *ops; // socket操作函数集:bind, connect, accept 等
};
bind()、connect()使用socket创建的文件描述符来找到socket结构体,再进一步找到sock结构体,从而进行端口的绑定。
2,bind()函数
/* * Bind a name to a socket. Nothing much to do here since it's * the protocol's responsibility to handle the local address. * * We move the socket address to kernel space before we call * the protocol layer (having also checked the address is ok). */ int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address); if (!err) { err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen); if (!err) err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen); } fput_light(sock->file, fput_needed); } return err; }
创建完socket之后就是地址的绑定了,通过bind系统调用实现。该调用通过传递进来的文件描述符找到对应的socket结构,然后通过socket访问sock结构。操作sock进行地址的绑定。如果指定了端口检查端口的可用性并绑定,否则随机分配一个端口进行绑定。但是怎样获知当前系统的端口绑定状态呢?通过一个全局变量inet_hashinfo进行,每次成功绑定一个端口会都将该sock加入到inet_hashinfo的绑定散列表中。加入之后bind的系统调用已基本完成了。
函数的三个参数分别为:
fd:即socket描述字,它是通过socket()函数创建了,唯一标识一个socket。bind()函数就是将给这个描述字绑定一个名字。
umyaddr:一个 struct sockaddr _user*指针,指向要绑定给sockfd的协议地址。这个地址结构根据地址创建socket时的地址协议族的不同而不同,
addrlen:对应的是地址的长度。
3.listen()
listen()源码如下
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
return __sys_listen(fd, backlog);
}
同样的内核通过文件描述符找到对应的sock,然后将其转换为inet_connection_sock结构。在inet_connection_sock结构体中含有一个类型为request_sock_queue的icsk_accept_queue变量,存储一些希望建立连接的sock相关的信息。
结构如下;
struct request_sock_queue {
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
rwlock_t syn_wait_lock;
u8 rskq_defer_accept;
struct listen_sock *listen_opt;
};
listen_opt用了存储当前正在请求建立连接的sock,称作半连接状态,当内核收到一个带有skb之后需找到对应的sock。该过程通过__inet_lookup_skb进行实现。该函数主要调用__inet_lookup,其中:首先看看这个包是不是一个已经建立好连接的sock中的包,通过__inet_lookup_established函数进行操作,失败的话可能是一个新的SYN数据包,此时还没有建立连接所以没有对应的sock,和该sock相关的只可能是监听sock了。
所以通过__inet_lookup_listener函数找到在本地的监听对应端口的sock。
无论哪种情况,找到sock之后便会将sock和skb一同传入tcp_v4_do_rcv函数作统一处理:
if (sk->sk_state == TCP_ESTABLISHED) {
sock_rps_save_rxhash(sk, skb->rxhash);
TCP_CHECK_TIMER(sk);
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
TCP_CHECK_TIMER(sk);
return 0;
}
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
如果是一个已建立连接的sock,调用tcp_rcv_established函数进行相应的处理。
如果是一个正在监听的sock,需要新建一个sock来保存这个半连接请求,该操作通过tcp_v4_hnd_req实现。
这里我们只关注tcp的建立过程,所以只分析tcp_v4_hnd_req和tcp_child_process函数:
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
struct tcphdr *th = tcp_hdr(skb);
const struct iphdr *iph = ip_hdr(skb);
struct sock *nsk;
struct request_sock **prev;
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source,
iph->saddr, iph->daddr);
if (req)
return tcp_check_req(sk, skb, req, prev);
nsk = inet_lookup_established(sock_net(sk), &tcp_hashinfo, iph->saddr,
th->source, iph->daddr, th->dest, inet_iif(skb));
if (nsk) {
if (nsk->sk_state != TCP_TIME_WAIT) {
bh_lock_sock(nsk);
return nsk;
}
inet_twsk_put(inet_twsk(nsk));
return NULL;
}
return sk;
}
通过tcp_v4_hnd_req函数就能够找到或创建和这个skb相关的sock。
A.如果返回的sock和处于Listen状态的sock不同,表示返回的是一个新的sock,第三次握手已经完成了。调用tcp_child_process处理。该函数的逻辑是让这个新的tcp_sock开始处理TCP段,同时唤醒应用层调用accept阻塞的程序,告知它有新的请求建立完成,可以从全连接队列中取出了。
B.如果返回的sock没有变化,表示是一个新的请求,调用tcp_rcv_state_process函数处理第一次连接的情况。该函数的逻辑较为复杂,简单的可以概括为新建一个request_sock并插入半连接队列,设置该request_sock的sock为SYN_RCV状态。然后构建SYN+ACK发送给客户端,完成TCP三次握手连接的第二步。
4.accept()
源码如下:
/*
* For accept, we attempt to create a new socket, set up the link
* with the client, wake up the client, then return the new
* connected fd. We collect the address of the connector in kernel
* space and move it to user at the very end. This is unclean because
* we open the socket then return an error.
*
* 1003.1g adds the ability to recvmsg() to query connection pending
* status to recvmsg. We need to add that support in a way thats
* clean when we restructure accept also.
*/
int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = -ENFILE;
newsock = sock_alloc();
if (!newsock)
goto out_put;
newsock->type = sock->type;
newsock->ops = sock->ops;
该调用创建新的struct socket表示新的连接,搜寻全连接队列,如果队列为空,将程序自身挂起等待连接请求的完成。否则从队列中取出头部request_sock,并设置新的struct socket和request_sock中的struct sock的对应关系。这样一个连接至此就建立完成了。客户端可以通过新返回的struct socket进行通信,同时旧的struct socket继续在监听。
客户端
1,socket()
socket的实现和服务器端一样
2,connect()
源码如下:
/* * Attempt to connect to a socket with the server address. The address * is in user space so we verify it is OK and move it to kernel space. * * For 1003.1g we need to add clean support for a bind to AF_UNSPEC to * break bindings * * NOTE: 1003.1g draft 6.3 is broken with respect to AX.25/NetROM and * other SEQPACKET protocols that take time to connect() as it doesn't * include the -EINPROGRESS status for such sockets. */ int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; err = move_addr_to_kernel(uservaddr, addrlen, &address); if (err < 0) goto out_put; err = security_socket_connect(sock, (struct sockaddr *)&address, addrlen); if (err) goto out_put; err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags); out_put: fput_light(sock->file, fput_needed); out: return err; } SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, int, addrlen) { return __sys_connect(fd, uservaddr, addrlen);
connect系统调用根据文件描述符找到socket和sock,如果当前socket的状态是SS_UNCONNECTED的情况下才正常处理连接请求。首先调用tcp协议簇的connect函数(即tcp_v4_connect)发送SYN,然后将socket状态置为SS_CONNECTING,将进程阻塞等待连接的完成。剩下的两次握手由协议栈自动完成。
tcp_v4_connect函数:
该函数首先进行一些合法性验证,随后调用ip_route_connect函数查找路由信息,将当前sock置为SYN_SENT状态,然后调用inet_hash_connect函数绑定本地的端口,和服务器端绑定端口的过程类似,但是会额外的将sock添加inet_hashinfo中的ehash散列表中(添加到这的原因是因为希望以后收到的SYN+ACK时能够找到对应的sock,虽然当前并没有真正意义上的建立连接)。到最后调用tcp_connect构建SYN数据包发送。
tcp_connect函数:
该函数逻辑比较简单,构造SYN数据段并设置相应的字段,将该段添加到发送队列上调用tcp_transmit_skb发送skb,最后重设重传定时器以便重传SYN数据段。
当客户端收到SYN+ACK之后,首先会通过tcp_v4_rcv从已建立连接散列表中找到对应的sock,然后调用tcp_v4_do_rcv函数进行处理,在该函数中主要的执行过程是调用tcp_rcv_state_process。又回到了tcp_rcv_state_process函数,它处理sock不处于ESTABLISHED和LISTEN的所有情况。当发现是一个SYN+AC段并且当前sock处于SYN_SENT状态时,表示连接建立马上要完成了。首先初始化TCP连接中一些需要的信息,如窗口大小,MSS,保活定时器等信息。然后给该sock的上层应用发送信号告知它连接建立已经完成,最后通过tcp_send_ack发送ACK完成最后一次握手。